 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHint-before-Solving Prompting: Guiding LLMs to Effectively Utilize Encoded Knowledge
Paper and Code


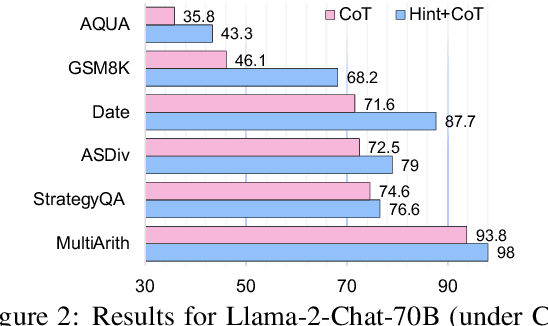

Large Language Models (LLMs) have recently showcased remarkable generalizability in various domains. Despite their extensive knowledge, LLMs still face challenges in efficiently utilizing encoded knowledge to develop accurate and logical reasoning processes. To mitigate this problem, we introduced Hint-before-Solving Prompting (HSP), which guides the model to generate hints (e.g., specific knowledge or key ideas) for solving the problem and then generate solutions containing intermediate reasoning steps. Since HSP is orthogonal to prompting methods (e.g., Chain-of-Thought (CoT)), we applied HSP to CoT, Least-to-Most, Plan-and-Solve, and Standard promptings. The results of extensive experiments on 6 reasoning benchmarks and 4 open-source LLMs demonstrate that HSP can effectively improve the accuracy of reasoning tasks: (1) By applying high-quality hint-enhanced HSP to CoT prompting, Llama2-70B-Chat shows an improvement of 9.7. (2) Beyond exploring training-free LLM capabilities, we built the HSPMATH dataset based on HSP and fine-tuned Llemma-7B, reaching 64.3 accuracy, surpassing GPT-3.5 and WizardMath-13B. We make our code and dataset publicly available at \url{https://github.com/jinlanfu/HSP}.