 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Semidefinite Convex Relaxation for Optimal Control Problems With Spatio-Temporal Constraints
Jan 06, 2026Solving optimal control problems (OCPs) of autonomous agents operating under spatial and temporal constraints fast and accurately is essential in applications ranging from eco-driving of autonomous vehicles to quadrotor navigation. However, the nonlinear programs approximating the OCPs are inherently nonconvex due to the coupling between the dynamics and the event timing, and therefore, they are challenging to solve. Most approaches address this challenge by predefining waypoint times or just using nonconvex trajectory optimization, which simplifies the problem but often yields suboptimal solutions. To significantly improve the numerical properties, we propose a formulation with a time-scaling direct multiple shooting scheme that partitions the prediction horizon into segments aligned with characteristic time constraints. Moreover, we develop a fast semidefinite-programming-based convex relaxation that exploits the sparsity pattern of the lifted formulation. Comprehensive simulation studies demonstrate the solution optimality and computational efficiency. Furthermore, real-world experiments on a quadrotor waypoint flight task with constrained open time windows validate the practical applicability of the approach in complex environments.
MAER-Nav: Bidirectional Motion Learning Through Mirror-Augmented Experience Replay for Robot Navigation
Mar 31, 2025



Deep Reinforcement Learning (DRL) based navigation methods have demonstrated promising results for mobile robots, but suffer from limited action flexibility in confined spaces. Conventional DRL approaches predominantly learn forward-motion policies, causing robots to become trapped in complex environments where backward maneuvers are necessary for recovery. This paper presents MAER-Nav (Mirror-Augmented Experience Replay for Robot Navigation), a novel framework that enables bidirectional motion learning without requiring explicit failure-driven hindsight experience replay or reward function modifications. Our approach integrates a mirror-augmented experience replay mechanism with curriculum learning to generate synthetic backward navigation experiences from successful trajectories. Experimental results in both simulation and real-world environments demonstrate that MAER-Nav significantly outperforms state-of-the-art methods while maintaining strong forward navigation capabilities. The framework effectively bridges the gap between the comprehensive action space utilization of traditional planning methods and the environmental adaptability of learning-based approaches, enabling robust navigation in scenarios where conventional DRL methods consistently fail.
Risk-Aware Reinforcement Learning for Autonomous Driving: Improving Safety When Driving through Intersection
Mar 27, 2025Applying reinforcement learning to autonomous driving has garnered widespread attention. However, classical reinforcement learning methods optimize policies by maximizing expected rewards but lack sufficient safety considerations, often putting agents in hazardous situations. This paper proposes a risk-aware reinforcement learning approach for autonomous driving to improve the safety performance when crossing the intersection. Safe critics are constructed to evaluate driving risk and work in conjunction with the reward critic to update the actor. Based on this, a Lagrangian relaxation method and cyclic gradient iteration are combined to project actions into a feasible safe region. Furthermore, a Multi-hop and Multi-layer perception (MLP) mixed Attention Mechanism (MMAM) is incorporated into the actor-critic network, enabling the policy to adapt to dynamic traffic and overcome permutation sensitivity challenges. This allows the policy to focus more effectively on surrounding potential risks while enhancing the identification of passing opportunities. Simulation tests are conducted on different tasks at unsignalized intersections. The results show that the proposed approach effectively reduces collision rates and improves crossing efficiency in comparison to baseline algorithms. Additionally, our ablation experiments demonstrate the benefits of incorporating risk-awareness and MMAM into RL.
Enhancing Deep Reinforcement Learning-based Robot Navigation Generalization through Scenario Augmentation
Mar 03, 2025



This work focuses on enhancing the generalization performance of deep reinforcement learning-based robot navigation in unseen environments. We present a novel data augmentation approach called scenario augmentation, which enables robots to navigate effectively across diverse settings without altering the training scenario. The method operates by mapping the robot's observation into an imagined space, generating an imagined action based on this transformed observation, and then remapping this action back to the real action executed in simulation. Through scenario augmentation, we conduct extensive comparative experiments to investigate the underlying causes of suboptimal navigation behaviors in unseen environments. Our analysis indicates that limited training scenarios represent the primary factor behind these undesired behaviors. Experimental results confirm that scenario augmentation substantially enhances the generalization capabilities of deep reinforcement learning-based navigation systems. The improved navigation framework demonstrates exceptional performance by producing near-optimal trajectories with significantly reduced navigation time in real-world applications.
PAI at SemEval-2023 Task 2: A Universal System for Named Entity Recognition with External Entity Information
May 10, 2023The MultiCoNER II task aims to detect complex, ambiguous, and fine-grained named entities in low-context situations and noisy scenarios like the presence of spelling mistakes and typos for multiple languages. The task poses significant challenges due to the scarcity of contextual information, the high granularity of the entities(up to 33 classes), and the interference of noisy data. To address these issues, our team {\bf PAI} proposes a universal Named Entity Recognition (NER) system that integrates external entity information to improve performance. Specifically, our system retrieves entities with properties from the knowledge base (i.e. Wikipedia) for a given text, then concatenates entity information with the input sentence and feeds it into Transformer-based models. Finally, our system wins 2 first places, 4 second places, and 1 third place out of 13 tracks. The code is publicly available at \url{https://github.com/diqiuzhuanzhuan/semeval-2023}.
An End-to-End Vehicle Trajcetory Prediction Framework
Apr 19, 2023



Anticipating the motion of neighboring vehicles is crucial for autonomous driving, especially on congested highways where even slight motion variations can result in catastrophic collisions. An accurate prediction of a future trajectory does not just rely on the previous trajectory, but also, more importantly, a simulation of the complex interactions between other vehicles nearby. Most state-of-the-art networks built to tackle the problem assume readily available past trajectory points, hence lacking a full end-to-end pipeline with direct video-to-output mechanism. In this article, we thus propose a novel end-to-end architecture that takes raw video inputs and outputs future trajectory predictions. It first extracts and tracks the 3D location of the nearby vehicles via multi-head attention-based regression networks as well as non-linear optimization. This provides the past trajectory points which then feeds into the trajectory prediction algorithm consisting of an attention-based LSTM encoder-decoder architecture, which allows it to model the complicated interdependence between the vehicles and make an accurate prediction of the future trajectory points of the surrounding vehicles. The proposed model is evaluated on the large-scale BLVD dataset, and has also been implemented on CARLA. The experimental results demonstrate that our approach outperforms various state-of-the-art models.
Machine Learning-Aided Operations and Communications of Unmanned Aerial Vehicles: A Contemporary Survey
Nov 07, 2022The ongoing amalgamation of UAV and ML techniques is creating a significant synergy and empowering UAVs with unprecedented intelligence and autonomy. This survey aims to provide a timely and comprehensive overview of ML techniques used in UAV operations and communications and identify the potential growth areas and research gaps. We emphasise the four key components of UAV operations and communications to which ML can significantly contribute, namely, perception and feature extraction, feature interpretation and regeneration, trajectory and mission planning, and aerodynamic control and operation. We classify the latest popular ML tools based on their applications to the four components and conduct gap analyses. This survey also takes a step forward by pointing out significant challenges in the upcoming realm of ML-aided automated UAV operations and communications. It is revealed that different ML techniques dominate the applications to the four key modules of UAV operations and communications. While there is an increasing trend of cross-module designs, little effort has been devoted to an end-to-end ML framework, from perception and feature extraction to aerodynamic control and operation. It is also unveiled that the reliability and trust of ML in UAV operations and applications require significant attention before full automation of UAVs and potential cooperation between UAVs and humans come to fruition.
A Diversity-Enhanced and Constraints-Relaxed Augmentation for Low-Resource Classification
Sep 24, 2021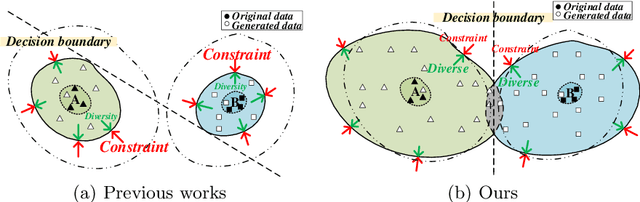
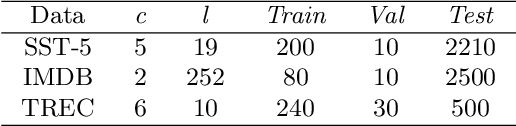
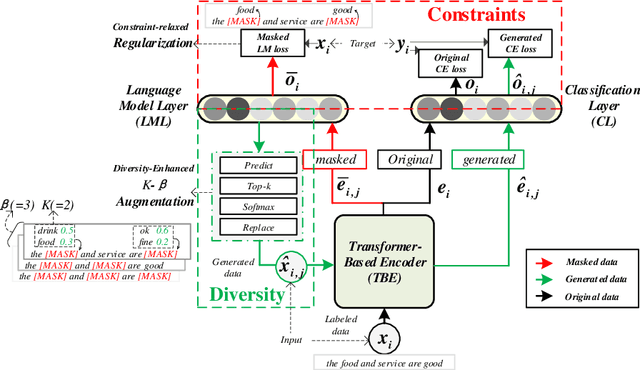
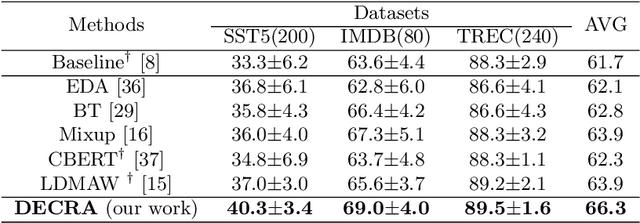
Data augmentation (DA) aims to generate constrained and diversified data to improve classifiers in Low-Resource Classification (LRC). Previous studies mostly use a fine-tuned Language Model (LM) to strengthen the constraints but ignore the fact that the potential of diversity could improve the effectiveness of generated data. In LRC, strong constraints but weak diversity in DA result in the poor generalization ability of classifiers. To address this dilemma, we propose a {D}iversity-{E}nhanced and {C}onstraints-\{R}elaxed {A}ugmentation (DECRA). Our DECRA has two essential components on top of a transformer-based backbone model. 1) A k-beta augmentation, an essential component of DECRA, is proposed to enhance the diversity in generating constrained data. It expands the changing scope and improves the degree of complexity of the generated data. 2) A masked language model loss, instead of fine-tuning, is used as a regularization. It relaxes constraints so that the classifier can be trained with more scattered generated data. The combination of these two components generates data that can reach or approach category boundaries and hence help the classifier generalize better. We evaluate our DECRA on three public benchmark datasets under low-resource settings. Extensive experiments demonstrate that our DECRA outperforms state-of-the-art approaches by 3.8% in the overall score.
Adversarial Mixing Policy for Relaxing Locally Linear Constraints in Mixup
Sep 15, 2021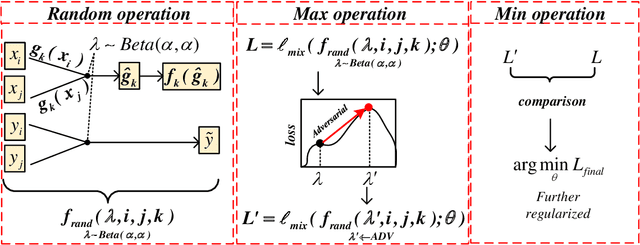
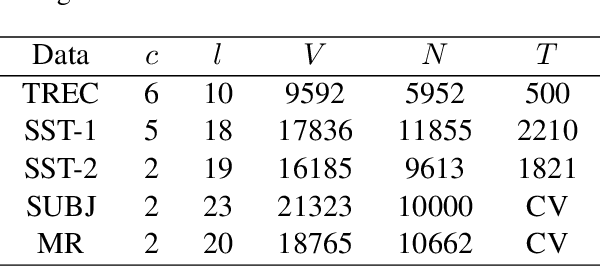
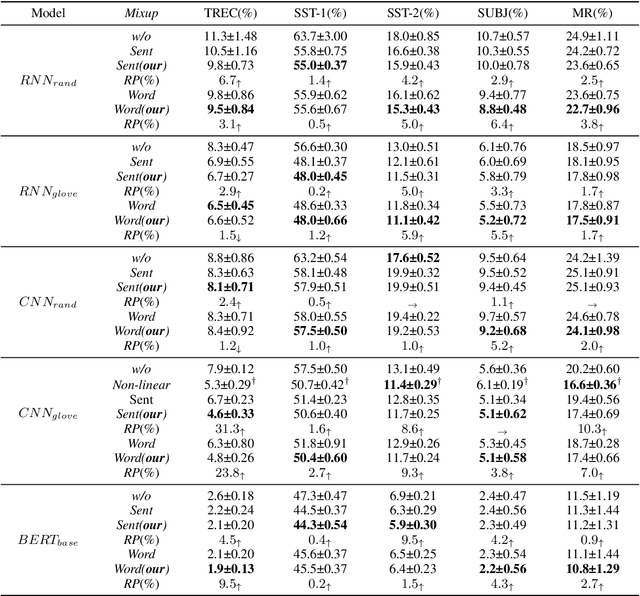
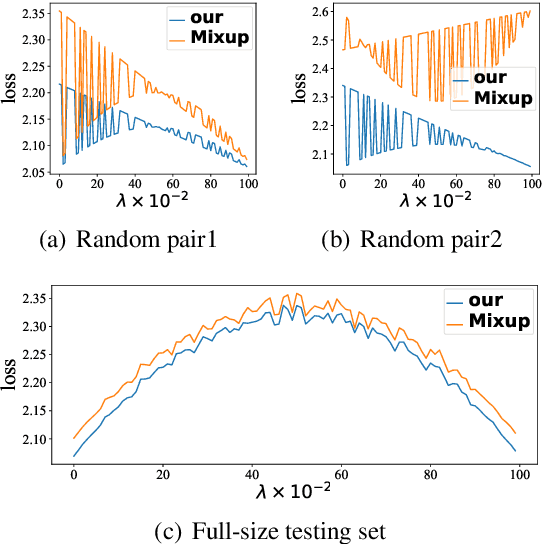
Mixup is a recent regularizer for current deep classification networks. Through training a neural network on convex combinations of pairs of examples and their labels, it imposes locally linear constraints on the model's input space. However, such strict linear constraints often lead to under-fitting which degrades the effects of regularization. Noticeably, this issue is getting more serious when the resource is extremely limited. To address these issues, we propose the Adversarial Mixing Policy (AMP), organized in a min-max-rand formulation, to relax the Locally Linear Constraints in Mixup. Specifically, AMP adds a small adversarial perturbation to the mixing coefficients rather than the examples. Thus, slight non-linearity is injected in-between the synthetic examples and synthetic labels. By training on these data, the deep networks are further regularized, and thus achieve a lower predictive error rate. Experiments on five text classification benchmarks and five backbone models have empirically shown that our methods reduce the error rate over Mixup variants in a significant margin (up to 31.3%), especially in low-resource conditions (up to 17.5%).