 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFlow: Zero-Shot Physics-Consistent Sampling via Proximal Flow Guidance
Jan 28, 2026Inferring physical fields from sparse observations while strictly satisfying partial differential equations (PDEs) is a fundamental challenge in computational physics. Recently, deep generative models offer powerful data-driven priors for such inverse problems, yet existing methods struggle to enforce hard physical constraints without costly retraining or disrupting the learned generative prior. Consequently, there is a critical need for a sampling mechanism that can reconcile strict physical consistency and observational fidelity with the statistical structure of the pre-trained prior. To this end, we present ProFlow, a proximal guidance framework for zero-shot physics-consistent sampling, defined as inferring solutions from sparse observations using a fixed generative prior without task-specific retraining. The algorithm employs a rigorous two-step scheme that alternates between: (\romannumeral1) a terminal optimization step, which projects the flow prediction onto the intersection of the physically and observationally consistent sets via proximal minimization; and (\romannumeral2) an interpolation step, which maps the refined state back to the generative trajectory to maintain consistency with the learned flow probability path. This procedure admits a Bayesian interpretation as a sequence of local maximum a posteriori (MAP) updates. Comprehensive benchmarks on Poisson, Helmholtz, Darcy, and viscous Burgers' equations demonstrate that ProFlow achieves superior physical and observational consistency, as well as more accurate distributional statistics, compared to state-of-the-art diffusion- and flow-based baselines.
Terminally constrained flow-based generative models from an optimal control perspective
Jan 14, 2026We address the problem of sampling from terminally constrained distributions with pre-trained flow-based generative models through an optimal control formulation. Theoretically, we characterize the value function by a Hamilton-Jacobi-Bellman equation and derive the optimal feedback control as the minimizer of the associated Hamiltonian. We show that as the control penalty increases, the controlled process recovers the reference distribution, while as the penalty vanishes, the terminal law converges to a generalized Wasserstein projection onto the constraint manifold. Algorithmically, we introduce Terminal Optimal Control with Flow-based models (TOCFlow), a geometry-aware sampling-time guidance method for pre-trained flows. Solving the control problem in a terminal co-moving frame that tracks reference trajectories yields a closed-form scalar damping factor along the Riemannian gradient, capturing second-order curvature effects without matrix inversions. TOCFlow therefore matches the geometric consistency of Gauss-Newton updates at the computational cost of standard gradient guidance. We evaluate TOCFlow on three high-dimensional scientific tasks spanning equality, inequality, and global statistical constraints, namely Darcy flow, constrained trajectory planning, and turbulence snapshot generation with Kolmogorov spectral scaling. Across all settings, TOCFlow improves constraint satisfaction over Euclidean guidance and projection baselines while preserving the reference model's generative quality.
Toward Theoretical Insights into Diffusion Trajectory Distillation via Operator Merging
May 21, 2025Diffusion trajectory distillation methods aim to accelerate sampling in diffusion models, which produce high-quality outputs but suffer from slow sampling speeds. These methods train a student model to approximate the multi-step denoising process of a pretrained teacher model in a single step, enabling one-shot generation. However, theoretical insights into the trade-off between different distillation strategies and generative quality remain limited, complicating their optimization and selection. In this work, we take a first step toward addressing this gap. Specifically, we reinterpret trajectory distillation as an operator merging problem in the linear regime, where each step of the teacher model is represented as a linear operator acting on noisy data. These operators admit a clear geometric interpretation as projections and rescalings corresponding to the noise schedule. During merging, signal shrinkage occurs as a convex combination of operators, arising from both discretization and limited optimization time of the student model. We propose a dynamic programming algorithm to compute the optimal merging strategy that maximally preserves signal fidelity. Additionally, we demonstrate the existence of a sharp phase transition in the optimal strategy, governed by data covariance structures. Our findings enhance the theoretical understanding of diffusion trajectory distillation and offer practical insights for improving distillation strategies.
Convergence Dynamics and Stabilization Strategies of Co-Evolving Generative Models
Mar 11, 2025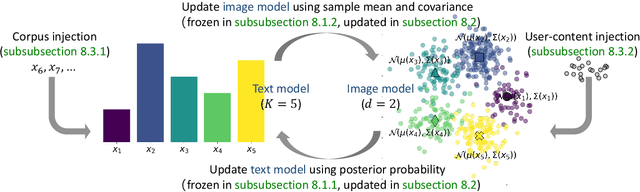
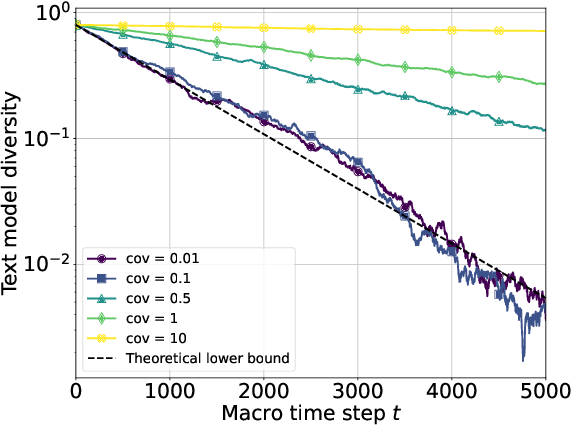
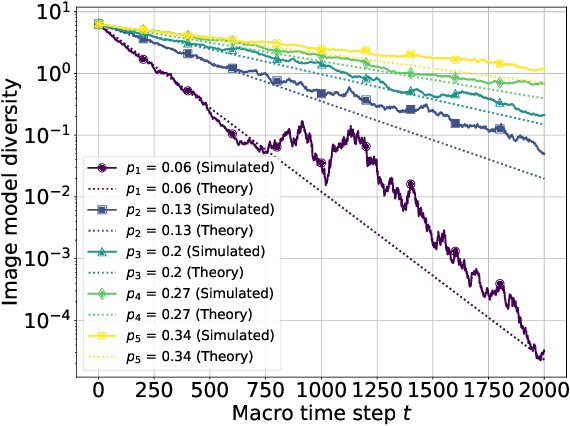
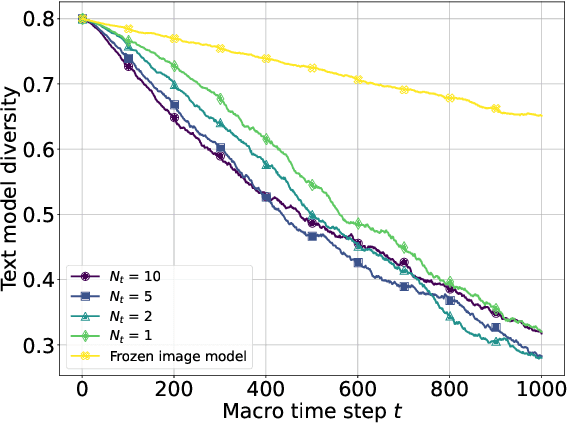
The increasing prevalence of synthetic data in training loops has raised concerns about model collapse, where generative models degrade when trained on their own outputs. While prior work focuses on this self-consuming process, we study an underexplored yet prevalent phenomenon: co-evolving generative models that shape each other's training through iterative feedback. This is common in multimodal AI ecosystems, such as social media platforms, where text models generate captions that guide image models, and the resulting images influence the future adaptation of the text model. We take a first step by analyzing such a system, modeling the text model as a multinomial distribution and the image model as a conditional multi-dimensional Gaussian distribution. Our analysis uncovers three key results. First, when one model remains fixed, the other collapses: a frozen image model causes the text model to lose diversity, while a frozen text model leads to an exponential contraction of image diversity, though fidelity remains bounded. Second, in fully interactive systems, mutual reinforcement accelerates collapse, with image contraction amplifying text homogenization and vice versa, leading to a Matthew effect where dominant texts sustain higher image diversity while rarer texts collapse faster. Third, we analyze stabilization strategies implicitly introduced by real-world external influences. Random corpus injections for text models and user-content injections for image models prevent collapse while preserving both diversity and fidelity. Our theoretical findings are further validated through experiments.
How Do Flow Matching Models Memorize and Generalize in Sample Data Subspaces?
Oct 31, 2024



Real-world data is often assumed to lie within a low-dimensional structure embedded in high-dimensional space. In practical settings, we observe only a finite set of samples, forming what we refer to as the sample data subspace. It serves an essential approximation supporting tasks such as dimensionality reduction and generation. A major challenge lies in whether generative models can reliably synthesize samples that stay within this subspace rather than drifting away from the underlying structure. In this work, we provide theoretical insights into this challenge by leveraging Flow Matching models, which transform a simple prior into a complex target distribution via a learned velocity field. By treating the real data distribution as discrete, we derive analytical expressions for the optimal velocity field under a Gaussian prior, showing that generated samples memorize real data points and represent the sample data subspace exactly. To generalize to suboptimal scenarios, we introduce the Orthogonal Subspace Decomposition Network (OSDNet), which systematically decomposes the velocity field into subspace and off-subspace components. Our analysis shows that the off-subspace component decays, while the subspace component generalizes within the sample data subspace, ensuring generated samples preserve both proximity and diversity.
MEP: Multiple Kernel Learning Enhancing Relative Positional Encoding Length Extrapolation
Mar 26, 2024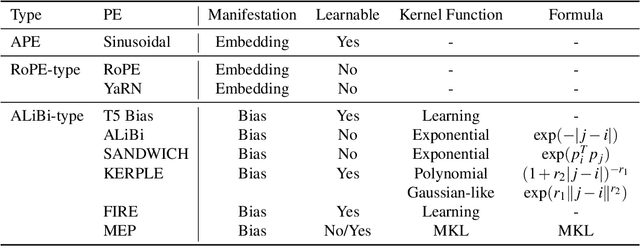
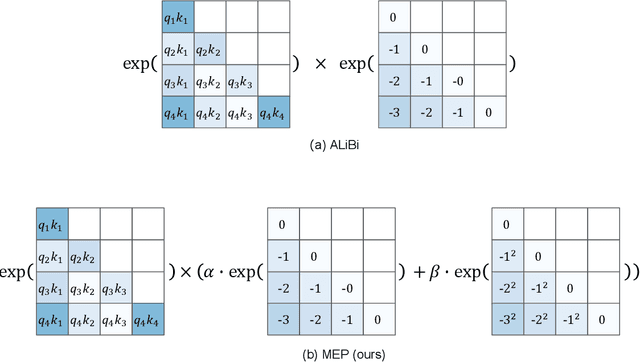
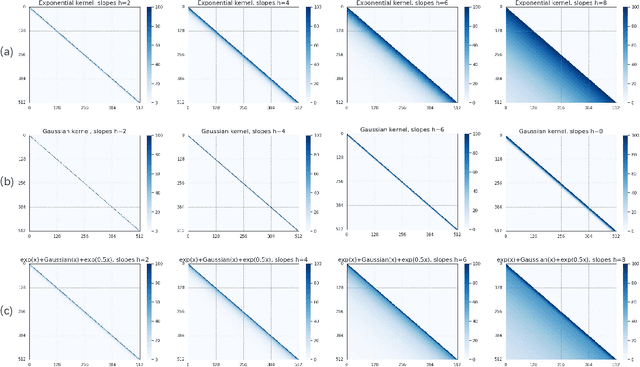
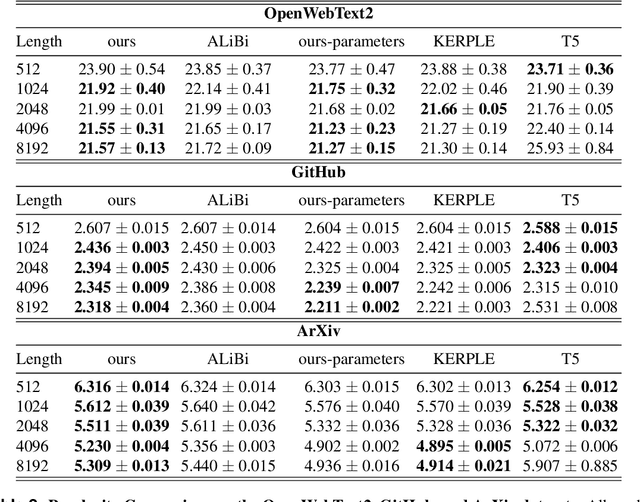
When the predicted sequence length exceeds the length seen during training, the transformer's inference accuracy diminishes. Existing relative position encoding methods, such as those based on the ALiBi technique, address the length extrapolation challenge exclusively through the implementation of a single kernel function, which introduces a constant bias to every post-softmax attention scores according to their distance. These approaches do not investigate or employ multiple kernel functions to address the extrapolation challenge. Drawing on the ALiBi approach, this study proposes a novel relative positional encoding method, called MEP, which employs a weighted average to combine distinct kernel functions(such as the exponential kernel and the Gaussian kernel) to generate a bias that is applied to post-softmax attention scores. Initially, the framework utilizes various kernel functions to construct multiple kernel functions. Each kernel function adheres to a consistent mean weight coefficient, harnessing the synergistic advantages of different kernels to formulate an innovative bias function. Subsequently, specific slopes are tailored for each kernel function, applying penalties at varying rates, to enhance the model's extrapolation capabilities. Finally, this bias is seamlessly incorporated as a penalty to the post-softmax scores. We present two distinct versions of our method: a parameter-free variant that requires no new learnable parameters, which enhances length extrapolation capabilities without compromising training efficiency, and a parameterized variant capable of integrating state-of-the-art techniques. Empirical evaluations across diverse datasets have demonstrated that both variants of our method achieve state-of-the-art performance, outperforming traditional parameter-free and parameterized approaches.
PAI at SemEval-2023 Task 2: A Universal System for Named Entity Recognition with External Entity Information
May 10, 2023The MultiCoNER II task aims to detect complex, ambiguous, and fine-grained named entities in low-context situations and noisy scenarios like the presence of spelling mistakes and typos for multiple languages. The task poses significant challenges due to the scarcity of contextual information, the high granularity of the entities(up to 33 classes), and the interference of noisy data. To address these issues, our team {\bf PAI} proposes a universal Named Entity Recognition (NER) system that integrates external entity information to improve performance. Specifically, our system retrieves entities with properties from the knowledge base (i.e. Wikipedia) for a given text, then concatenates entity information with the input sentence and feeds it into Transformer-based models. Finally, our system wins 2 first places, 4 second places, and 1 third place out of 13 tracks. The code is publicly available at \url{https://github.com/diqiuzhuanzhuan/semeval-2023}.
A More Stable Accelerated Gradient Method Inspired by Continuous-Time Perspective
Dec 09, 2021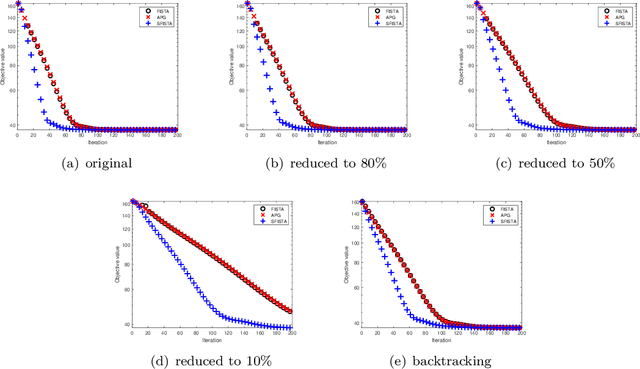
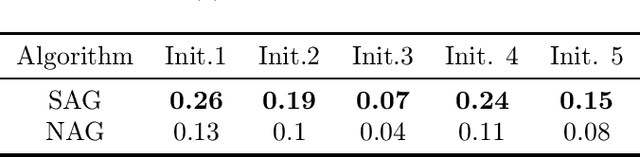
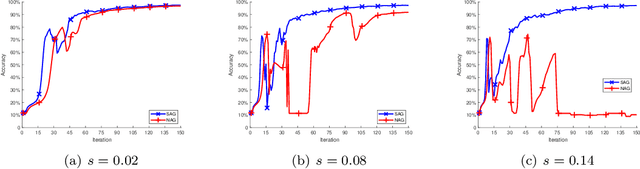
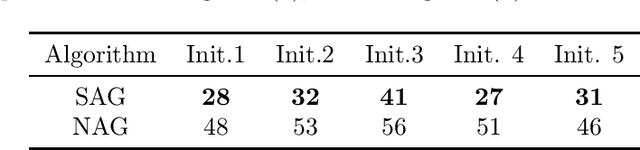
Nesterov's accelerated gradient method (NAG) is widely used in problems with machine learning background including deep learning, and is corresponding to a continuous-time differential equation. From this connection, the property of the differential equation and its numerical approximation can be investigated to improve the accelerated gradient method. In this work we present a new improvement of NAG in terms of stability inspired by numerical analysis. We give the precise order of NAG as a numerical approximation of its continuous-time limit and then present a new method with higher order. We show theoretically that our new method is more stable than NAG for large step size. Experiments of matrix completion and handwriting digit recognition demonstrate that the stability of our new method is better. Furthermore, better stability leads to higher computational speed in experiments.
SOFT: Softmax-free Transformer with Linear Complexity
Oct 29, 2021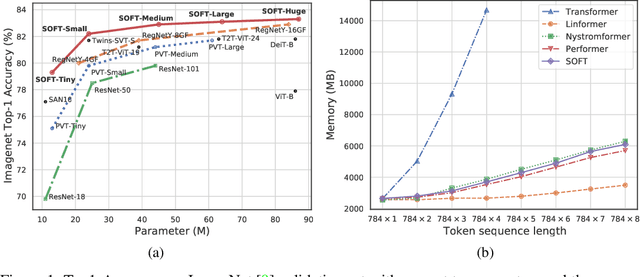
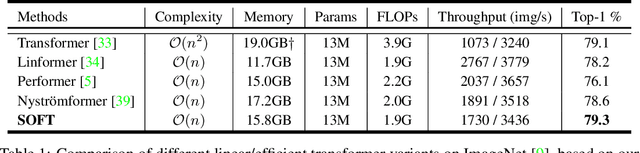
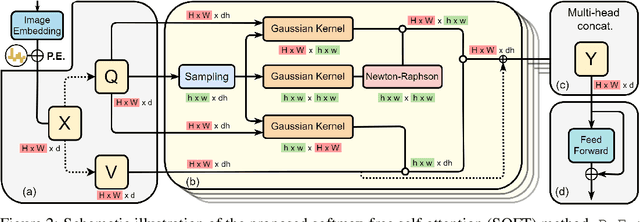
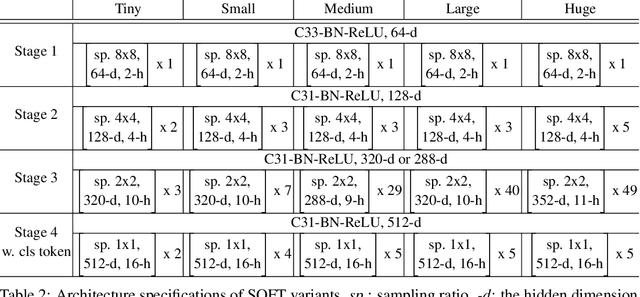
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by self-attention. However, the employment of self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have been made in Natural Language Processing. However, an in-depth analysis in this work shows that they are either theoretically flawed or empirically ineffective for visual recognition. We further identify that their limitations are rooted in keeping the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Keeping this softmax operation challenges any subsequent linearization efforts. Based on this insight, for the first time, a softmax-free transformer or SOFT is proposed. To remove softmax in self-attention, Gaussian kernel function is used to replace the dot-product similarity without further normalization. This enables a full self-attention matrix to be approximated via a low-rank matrix decomposition. The robustness of the approximation is achieved by calculating its Moore-Penrose inverse using a Newton-Raphson method. Extensive experiments on ImageNet show that our SOFT significantly improves the computational efficiency of existing ViT variants. Crucially, with a linear complexity, much longer token sequences are permitted in SOFT, resulting in superior trade-off between accuracy and complexity.
A Diversity-Enhanced and Constraints-Relaxed Augmentation for Low-Resource Classification
Sep 24, 2021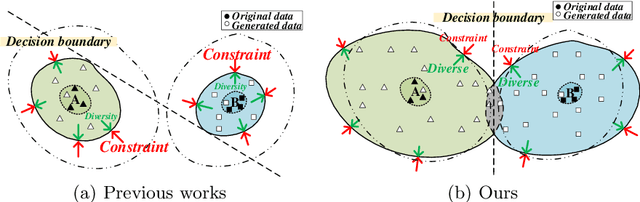
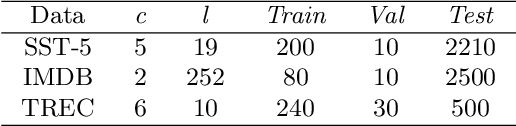
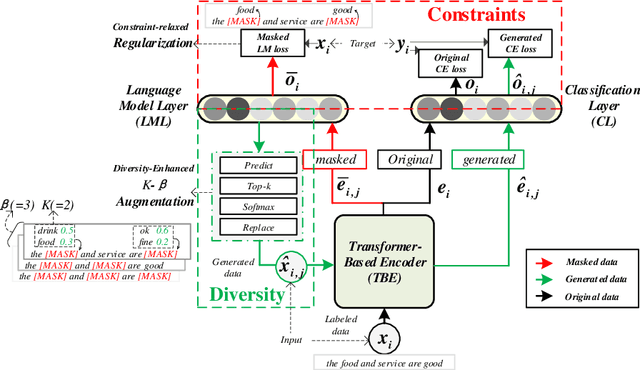
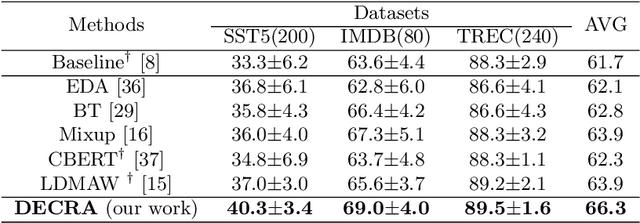
Data augmentation (DA) aims to generate constrained and diversified data to improve classifiers in Low-Resource Classification (LRC). Previous studies mostly use a fine-tuned Language Model (LM) to strengthen the constraints but ignore the fact that the potential of diversity could improve the effectiveness of generated data. In LRC, strong constraints but weak diversity in DA result in the poor generalization ability of classifiers. To address this dilemma, we propose a {D}iversity-{E}nhanced and {C}onstraints-\{R}elaxed {A}ugmentation (DECRA). Our DECRA has two essential components on top of a transformer-based backbone model. 1) A k-beta augmentation, an essential component of DECRA, is proposed to enhance the diversity in generating constrained data. It expands the changing scope and improves the degree of complexity of the generated data. 2) A masked language model loss, instead of fine-tuning, is used as a regularization. It relaxes constraints so that the classifier can be trained with more scattered generated data. The combination of these two components generates data that can reach or approach category boundaries and hence help the classifier generalize better. We evaluate our DECRA on three public benchmark datasets under low-resource settings. Extensive experiments demonstrate that our DECRA outperforms state-of-the-art approaches by 3.8% in the overall score.