 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Semantic Scene Completion with a Refinement Module
Dec 20, 2025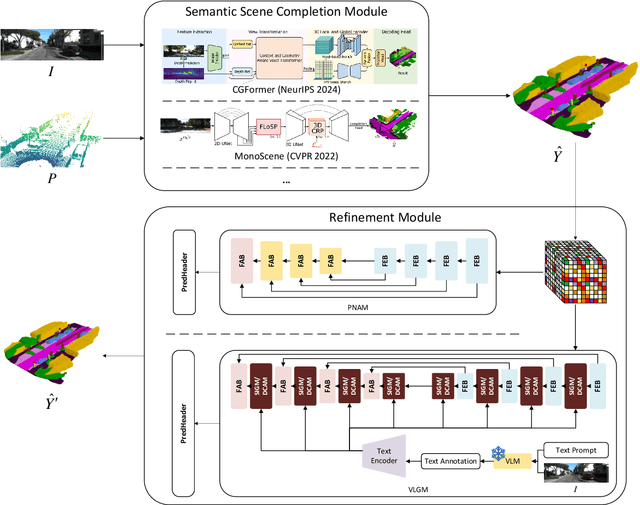
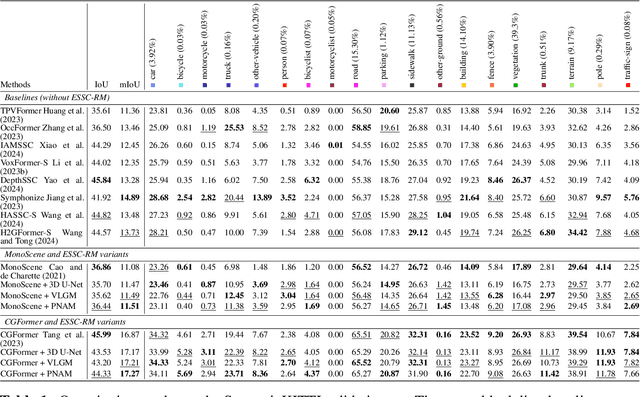
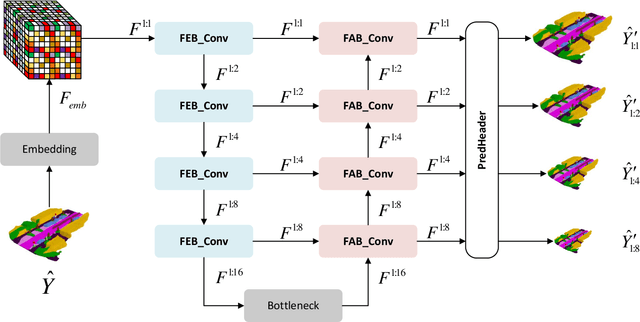

We propose ESSC-RM, a plug-and-play Enhancing framework for Semantic Scene Completion with a Refinement Module, which can be seamlessly integrated into existing SSC models. ESSC-RM operates in two phases: a baseline SSC network first produces a coarse voxel prediction, which is subsequently refined by a 3D U-Net-based Prediction Noise-Aware Module (PNAM) and Voxel-level Local Geometry Module (VLGM) under multiscale supervision. Experiments on SemanticKITTI show that ESSC-RM consistently improves semantic prediction performance. When integrated into CGFormer and MonoScene, the mean IoU increases from 16.87% to 17.27% and from 11.08% to 11.51%, respectively. These results demonstrate that ESSC-RM serves as a general refinement framework applicable to a wide range of SSC models.
Translating Images to Road Network:A Non-Autoregressive Sequence-to-Sequence Approach
Feb 13, 2024



The extraction of road network is essential for the generation of high-definition maps since it enables the precise localization of road landmarks and their interconnections. However, generating road network poses a significant challenge due to the conflicting underlying combination of Euclidean (e.g., road landmarks location) and non-Euclidean (e.g., road topological connectivity) structures. Existing methods struggle to merge the two types of data domains effectively, but few of them address it properly. Instead, our work establishes a unified representation of both types of data domain by projecting both Euclidean and non-Euclidean data into an integer series called RoadNet Sequence. Further than modeling an auto-regressive sequence-to-sequence Transformer model to understand RoadNet Sequence, we decouple the dependency of RoadNet Sequence into a mixture of auto-regressive and non-autoregressive dependency. Building on this, our proposed non-autoregressive sequence-to-sequence approach leverages non-autoregressive dependencies while fixing the gap towards auto-regressive dependencies, resulting in success on both efficiency and accuracy. Extensive experiments on nuScenes dataset demonstrate the superiority of RoadNet Sequence representation and the non-autoregressive approach compared to existing state-of-the-art alternatives. The code is open-source on https://github.com/fudan-zvg/RoadNetworkTRansformer.
S-Agents: self-organizing agents in open-ended environment
Feb 08, 2024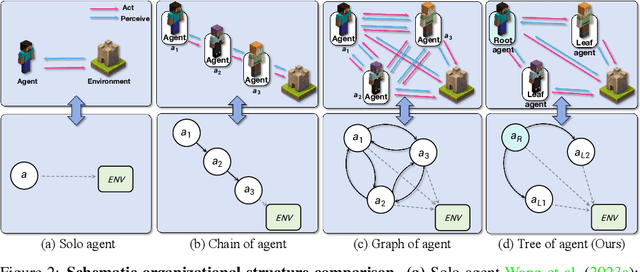
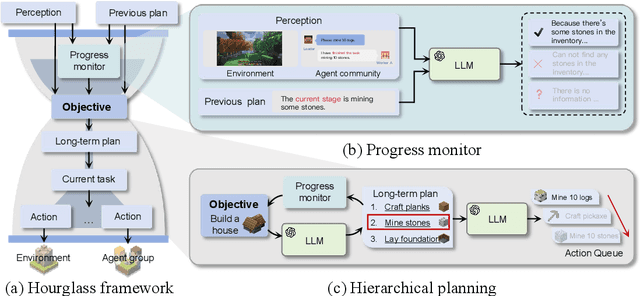


Leveraging large language models (LLMs), autonomous agents have significantly improved, gaining the ability to handle a variety of tasks. In open-ended settings, optimizing collaboration for efficiency and effectiveness demands flexible adjustments. Despite this, current research mainly emphasizes fixed, task-oriented workflows and overlooks agent-centric organizational structures. Drawing inspiration from human organizational behavior, we introduce a self-organizing agent system (S-Agents) with a "tree of agents" structure for dynamic workflow, an "hourglass agent architecture" for balancing information priorities, and a "non-obstructive collaboration" method to allow asynchronous task execution among agents. This structure can autonomously coordinate a group of agents, efficiently addressing the challenges of an open and dynamic environment without human intervention. Our experiments demonstrate that S-Agents proficiently execute collaborative building tasks and resource collection in the Minecraft environment, validating their effectiveness.
S-NeRF++: Autonomous Driving Simulation via Neural Reconstruction and Generation
Feb 03, 2024



Autonomous driving simulation system plays a crucial role in enhancing self-driving data and simulating complex and rare traffic scenarios, ensuring navigation safety. However, traditional simulation systems, which often heavily rely on manual modeling and 2D image editing, struggled with scaling to extensive scenes and generating realistic simulation data. In this study, we present S-NeRF++, an innovative autonomous driving simulation system based on neural reconstruction. Trained on widely-used self-driving datasets such as nuScenes and Waymo, S-NeRF++ can generate a large number of realistic street scenes and foreground objects with high rendering quality as well as offering considerable flexibility in manipulation and simulation. Specifically, S-NeRF++ is an enhanced neural radiance field for synthesizing large-scale scenes and moving vehicles, with improved scene parameterization and camera pose learning. The system effectively utilizes noisy and sparse LiDAR data to refine training and address depth outliers, ensuring high quality reconstruction and novel-view rendering. It also provides a diverse foreground asset bank through reconstructing and generating different foreground vehicles to support comprehensive scenario creation. Moreover, we have developed an advanced foreground-background fusion pipeline that skillfully integrates illumination and shadow effects, further enhancing the realism of our simulations. With the high-quality simulated data provided by our S-NeRF++, we found the perception methods enjoy performance boost on several autonomous driving downstream tasks, which further demonstrate the effectiveness of our proposed simulator.
LaneGraph2Seq: Lane Topology Extraction with Language Model via Vertex-Edge Encoding and Connectivity Enhancement
Jan 31, 2024Understanding road structures is crucial for autonomous driving. Intricate road structures are often depicted using lane graphs, which include centerline curves and connections forming a Directed Acyclic Graph (DAG). Accurate extraction of lane graphs relies on precisely estimating vertex and edge information within the DAG. Recent research highlights Transformer-based language models' impressive sequence prediction abilities, making them effective for learning graph representations when graph data are encoded as sequences. However, existing studies focus mainly on modeling vertices explicitly, leaving edge information simply embedded in the network. Consequently, these approaches fall short in the task of lane graph extraction. To address this, we introduce LaneGraph2Seq, a novel approach for lane graph extraction. It leverages a language model with vertex-edge encoding and connectivity enhancement. Our serialization strategy includes a vertex-centric depth-first traversal and a concise edge-based partition sequence. Additionally, we use classifier-free guidance combined with nucleus sampling to improve lane connectivity. We validate our method on prominent datasets, nuScenes and Argoverse 2, showcasing consistent and compelling results. Our LaneGraph2Seq approach demonstrates superior performance compared to state-of-the-art techniques in lane graph extraction.
WoVoGen: World Volume-aware Diffusion for Controllable Multi-camera Driving Scene Generation
Dec 06, 2023



Generating multi-camera street-view videos is critical for augmenting autonomous driving datasets, addressing the urgent demand for extensive and varied data. Due to the limitations in diversity and challenges in handling lighting conditions, traditional rendering-based methods are increasingly being supplanted by diffusion-based methods. However, a significant challenge in diffusion-based methods is ensuring that the generated sensor data preserve both intra-world consistency and inter-sensor coherence. To address these challenges, we combine an additional explicit world volume and propose the World Volume-aware Multi-camera Driving Scene Generator (WoVoGen). This system is specifically designed to leverage 4D world volume as a foundational element for video generation. Our model operates in two distinct phases: (i) envisioning the future 4D temporal world volume based on vehicle control sequences, and (ii) generating multi-camera videos, informed by this envisioned 4D temporal world volume and sensor interconnectivity. The incorporation of the 4D world volume empowers WoVoGen not only to generate high-quality street-view videos in response to vehicle control inputs but also to facilitate scene editing tasks.
Enhancing High-Resolution 3D Generation through Pixel-wise Gradient Clipping
Oct 19, 2023



High-resolution 3D object generation remains a challenging task primarily due to the limited availability of comprehensive annotated training data. Recent advancements have aimed to overcome this constraint by harnessing image generative models, pretrained on extensive curated web datasets, using knowledge transfer techniques like Score Distillation Sampling (SDS). Efficiently addressing the requirements of high-resolution rendering often necessitates the adoption of latent representation-based models, such as the Latent Diffusion Model (LDM). In this framework, a significant challenge arises: To compute gradients for individual image pixels, it is necessary to backpropagate gradients from the designated latent space through the frozen components of the image model, such as the VAE encoder used within LDM. However, this gradient propagation pathway has never been optimized, remaining uncontrolled during training. We find that the unregulated gradients adversely affect the 3D model's capacity in acquiring texture-related information from the image generative model, leading to poor quality appearance synthesis. To address this overarching challenge, we propose an innovative operation termed Pixel-wise Gradient Clipping (PGC) designed for seamless integration into existing 3D generative models, thereby enhancing their synthesis quality. Specifically, we control the magnitude of stochastic gradients by clipping the pixel-wise gradients efficiently, while preserving crucial texture-related gradient directions. Despite this simplicity and minimal extra cost, extensive experiments demonstrate the efficacy of our PGC in enhancing the performance of existing 3D generative models for high-resolution object rendering.
SUIT: Learning Significance-guided Information for 3D Temporal Detection
Jul 04, 2023



3D object detection from LiDAR point cloud is of critical importance for autonomous driving and robotics. While sequential point cloud has the potential to enhance 3D perception through temporal information, utilizing these temporal features effectively and efficiently remains a challenging problem. Based on the observation that the foreground information is sparsely distributed in LiDAR scenes, we believe sufficient knowledge can be provided by sparse format rather than dense maps. To this end, we propose to learn Significance-gUided Information for 3D Temporal detection (SUIT), which simplifies temporal information as sparse features for information fusion across frames. Specifically, we first introduce a significant sampling mechanism that extracts information-rich yet sparse features based on predicted object centroids. On top of that, we present an explicit geometric transformation learning technique, which learns the object-centric transformations among sparse features across frames. We evaluate our method on large-scale nuScenes and Waymo dataset, where our SUIT not only significantly reduces the memory and computation cost of temporal fusion, but also performs well over the state-of-the-art baselines.
Generative Semantic Segmentation
Mar 20, 2023We present Generative Semantic Segmentation (GSS), a generative learning approach for semantic segmentation. Uniquely, we cast semantic segmentation as an image-conditioned mask generation problem. This is achieved by replacing the conventional per-pixel discriminative learning with a latent prior learning process. Specifically, we model the variational posterior distribution of latent variables given the segmentation mask. To that end, the segmentation mask is expressed with a special type of image (dubbed as maskige). This posterior distribution allows to generate segmentation masks unconditionally. To achieve semantic segmentation on a given image, we further introduce a conditioning network. It is optimized by minimizing the divergence between the posterior distribution of maskige (i.e., segmentation masks) and the latent prior distribution of input training images. Extensive experiments on standard benchmarks show that our GSS can perform competitively to prior art alternatives in the standard semantic segmentation setting, whilst achieving a new state of the art in the more challenging cross-domain setting.
SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation
Feb 09, 2023



Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement render these methods unsuitable on the mobile device, especially for the high-resolution per-pixel semantic segmentation task. In this paper, we introduce a new method squeeze-enhanced Axial TransFormer (SeaFormer) for mobile semantic segmentation. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. Coupled with a light segmentation head, we achieve the best trade-off between segmentation accuracy and latency on the ARM-based mobile devices on the ADE20K and Cityscapes datasets. Critically, we beat both the mobile-friendly rivals and Transformer-based counterparts with better performance and lower latency without bells and whistles. Beyond semantic segmentation, we further apply the proposed SeaFormer architecture to image classification problem, demonstrating the potentials of serving as a versatile mobile-friendly backbone.