 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo World Action Models Generalize Better than VLAs? A Robustness Study
Mar 23, 2026Robot action planning in the real world is challenging as it requires not only understanding the current state of the environment but also predicting how it will evolve in response to actions. Vision-language-action (VLA), which repurpose large-scale vision-language models for robot action generation using action experts, have achieved notable success across a variety of robotic tasks. Nevertheless, their performance remains constrained by the scope of their training data, exhibiting limited generalization to unseen scenarios and vulnerability to diverse contextual perturbations. More recently, world models have been revisited as an alternative to VLAs. These models, referred to as world action models (WAMs), are built upon world models that are trained on large corpora of video data to predict future states. With minor adaptations, their latent representation can be decoded into robot actions. It has been suggested that their explicit dynamic prediction capacity, combined with spatiotemporal priors acquired from web-scale video pretraining, enables WAMs to generalize more effectively than VLAs. In this paper, we conduct a comparative study of prominent state-of-the-art VLA policies and recently released WAMs. We evaluate their performance on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under various visual and language perturbations. Our results show that WAMs achieve strong robustness, with LingBot-VA reaching 74.2% success rate on RoboTwin 2.0-Plus and Cosmos-Policy achieving 82.2% on LIBERO-Plus. While VLAs such as $π_{0.5}$ can achieve comparable robustness on certain tasks, they typically require extensive training with diverse robotic datasets and varied learning objectives. Hybrid approaches that partially incorporate video-based dynamic learning exhibit intermediate robustness, highlighting the importance of how video priors are integrated.
SSR: Pushing the Limit of Spatial Intelligence with Structured Scene Reasoning
Feb 28, 2026While Multimodal Large Language Models (MLLMs) excel in semantic tasks, they frequently lack the "spatial sense" essential for sophisticated geometric reasoning. Current models typically suffer from exorbitant modality-alignment costs and deficiency in fine-grained structural modeling precision.We introduce SSR, a framework designed for Structured Scene Reasoning that seamlessly integrates 2D and 3D representations via a lightweight alignment mechanism. To minimize training overhead, our framework anchors 3D geometric features to the large language model's pre-aligned 2D visual semantics through cross-modal addition and token interleaving, effectively obviating the necessity for large-scale alignment pre-training. To underpin complex spatial reasoning, we propose a novel scene graph generation pipeline that represents global layouts as a chain of independent local triplets defined by relative coordinates. This is complemented by an incremental generation algorithm, enabling the model to construct "language-model-friendly" structural scaffolds for complex environments. Furthermore, we extend these capabilities to global-scale 3D global grounding task, achieving absolute metric precision across heterogeneous data sources. At a 7B parameter scale, SSR achieves state-of-the-art performance on multiple spatial intelligence benchmarks, notably scoring 73.9 on VSI-Bench. Our approach significantly outperforms much larger models, demonstrating that efficient feature alignment and structured scene reasoning are the cornerstones of authentic spatial intelligence.
Towards Adaptive, Scalable, and Robust Coordination of LLM Agents: A Dynamic Ad-Hoc Networking Perspective
Feb 08, 2026Multi-agent architectures built on large language models (LLMs) have demonstrated the potential to realize swarm intelligence through well-crafted collaboration. However, the substantial burden of manual orchestration inherently raises an imperative to automate the design of agentic workflows. We frame such an agent coordination challenge as a classic problem in dynamic ad-hoc networking: How to establish adaptive and reliable communication among a scalable number of agentic hosts? In response to this unresolved dilemma, we introduce RAPS, a reputation-aware publish-subscribe paradigm for adaptive, scalable, and robust coordination of LLM agents. RAPS is grounded in the Distributed Publish-Subscribe Protocol, allowing LLM agents to exchange messages based on their declared intents rather than predefined topologies. Beyond this substrate, RAPS further incorporates two coherent overlays: (i) Reactive Subscription, enabling agents to dynamically refine their intents; and (ii) Bayesian Reputation, empowering each agent with a local watchdog to detect and isolate malicious peers. Extensive experiments over five benchmarks showcase that our design effectively reconciles adaptivity, scalability, and robustness in a unified multi-agent coordination framework.
Top 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
Geo-ConvGRU: Geographically Masked Convolutional Gated Recurrent Unit for Bird-Eye View Segmentation
Dec 28, 2024Convolutional Neural Networks (CNNs) have significantly impacted various computer vision tasks, however, they inherently struggle to model long-range dependencies explicitly due to the localized nature of convolution operations. Although Transformers have addressed limitations in long-range dependencies for the spatial dimension, the temporal dimension remains underexplored. In this paper, we first highlight that 3D CNNs exhibit limitations in capturing long-range temporal dependencies. Though Transformers mitigate spatial dimension issues, they result in a considerable increase in parameter and processing speed reduction. To overcome these challenges, we introduce a simple yet effective module, Geographically Masked Convolutional Gated Recurrent Unit (Geo-ConvGRU), tailored for Bird's-Eye View segmentation. Specifically, we substitute the 3D CNN layers with ConvGRU in the temporal module to bolster the capacity of networks for handling temporal dependencies. Additionally, we integrate a geographical mask into the Convolutional Gated Recurrent Unit to suppress noise introduced by the temporal module. Comprehensive experiments conducted on the NuScenes dataset substantiate the merits of the proposed Geo-ConvGRU, revealing that our approach attains state-of-the-art performance in Bird's-Eye View segmentation.
Translating Images to Road Network:A Non-Autoregressive Sequence-to-Sequence Approach
Feb 13, 2024



The extraction of road network is essential for the generation of high-definition maps since it enables the precise localization of road landmarks and their interconnections. However, generating road network poses a significant challenge due to the conflicting underlying combination of Euclidean (e.g., road landmarks location) and non-Euclidean (e.g., road topological connectivity) structures. Existing methods struggle to merge the two types of data domains effectively, but few of them address it properly. Instead, our work establishes a unified representation of both types of data domain by projecting both Euclidean and non-Euclidean data into an integer series called RoadNet Sequence. Further than modeling an auto-regressive sequence-to-sequence Transformer model to understand RoadNet Sequence, we decouple the dependency of RoadNet Sequence into a mixture of auto-regressive and non-autoregressive dependency. Building on this, our proposed non-autoregressive sequence-to-sequence approach leverages non-autoregressive dependencies while fixing the gap towards auto-regressive dependencies, resulting in success on both efficiency and accuracy. Extensive experiments on nuScenes dataset demonstrate the superiority of RoadNet Sequence representation and the non-autoregressive approach compared to existing state-of-the-art alternatives. The code is open-source on https://github.com/fudan-zvg/RoadNetworkTRansformer.
LaneGraph2Seq: Lane Topology Extraction with Language Model via Vertex-Edge Encoding and Connectivity Enhancement
Jan 31, 2024Understanding road structures is crucial for autonomous driving. Intricate road structures are often depicted using lane graphs, which include centerline curves and connections forming a Directed Acyclic Graph (DAG). Accurate extraction of lane graphs relies on precisely estimating vertex and edge information within the DAG. Recent research highlights Transformer-based language models' impressive sequence prediction abilities, making them effective for learning graph representations when graph data are encoded as sequences. However, existing studies focus mainly on modeling vertices explicitly, leaving edge information simply embedded in the network. Consequently, these approaches fall short in the task of lane graph extraction. To address this, we introduce LaneGraph2Seq, a novel approach for lane graph extraction. It leverages a language model with vertex-edge encoding and connectivity enhancement. Our serialization strategy includes a vertex-centric depth-first traversal and a concise edge-based partition sequence. Additionally, we use classifier-free guidance combined with nucleus sampling to improve lane connectivity. We validate our method on prominent datasets, nuScenes and Argoverse 2, showcasing consistent and compelling results. Our LaneGraph2Seq approach demonstrates superior performance compared to state-of-the-art techniques in lane graph extraction.
Self-supervised Event-based Monocular Depth Estimation using Cross-modal Consistency
Jan 14, 2024An event camera is a novel vision sensor that can capture per-pixel brightness changes and output a stream of asynchronous ``events''. It has advantages over conventional cameras in those scenes with high-speed motions and challenging lighting conditions because of the high temporal resolution, high dynamic range, low bandwidth, low power consumption, and no motion blur. Therefore, several supervised monocular depth estimation from events is proposed to address scenes difficult for conventional cameras. However, depth annotation is costly and time-consuming. In this paper, to lower the annotation cost, we propose a self-supervised event-based monocular depth estimation framework named EMoDepth. EMoDepth constrains the training process using the cross-modal consistency from intensity frames that are aligned with events in the pixel coordinate. Moreover, in inference, only events are used for monocular depth prediction. Additionally, we design a multi-scale skip-connection architecture to effectively fuse features for depth estimation while maintaining high inference speed. Experiments on MVSEC and DSEC datasets demonstrate that our contributions are effective and that the accuracy can outperform existing supervised event-based and unsupervised frame-based methods.
Semi-Supervised Learning for Visual Bird's Eye View Semantic Segmentation
Aug 28, 2023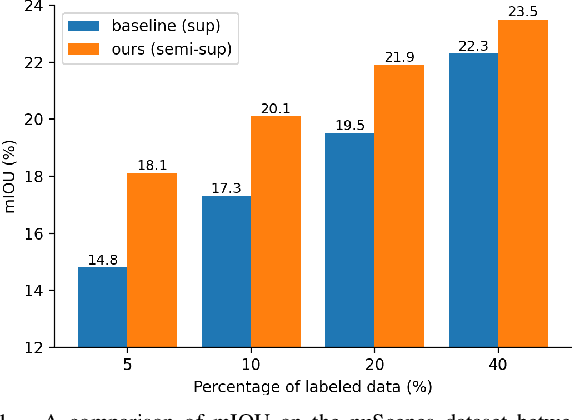
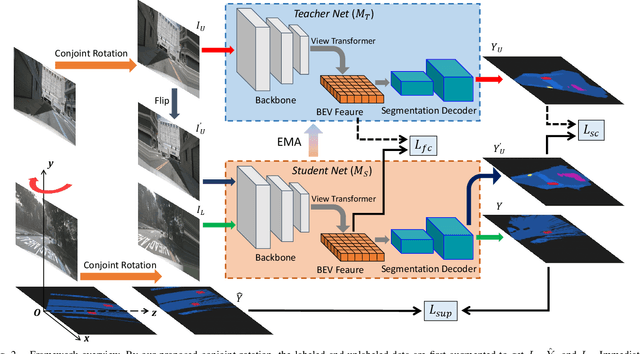
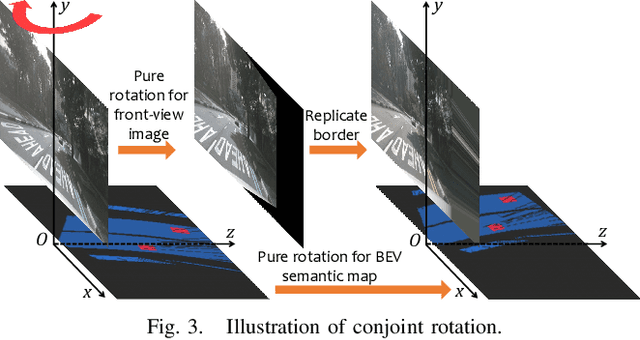
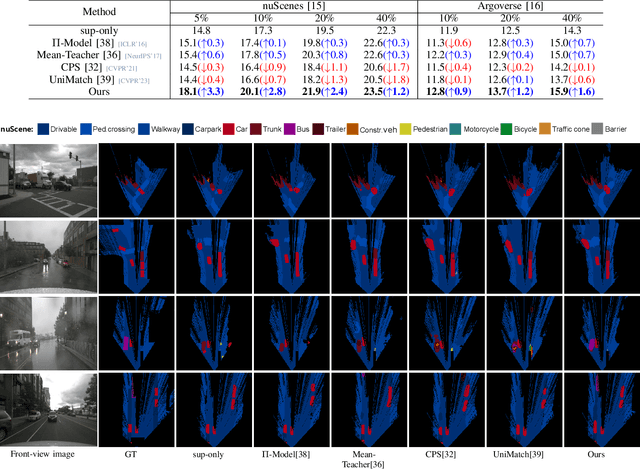
Visual bird's eye view (BEV) semantic segmentation helps autonomous vehicles understand the surrounding environment only from images, including static elements (e.g., roads) and dynamic elements (e.g., vehicles, pedestrians). However, the high cost of annotation procedures of full-supervised methods limits the capability of the visual BEV semantic segmentation, which usually needs HD maps, 3D object bounding boxes, and camera extrinsic matrixes. In this paper, we present a novel semi-supervised framework for visual BEV semantic segmentation to boost performance by exploiting unlabeled images during the training. A consistency loss that makes full use of unlabeled data is then proposed to constrain the model on not only semantic prediction but also the BEV feature. Furthermore, we propose a novel and effective data augmentation method named conjoint rotation which reasonably augments the dataset while maintaining the geometric relationship between the front-view images and the BEV semantic segmentation. Extensive experiments on the nuScenes and Argoverse datasets show that our semi-supervised framework can effectively improve prediction accuracy. To the best of our knowledge, this is the first work that explores improving visual BEV semantic segmentation performance using unlabeled data. The code will be publicly available.
HybridPoint: Point Cloud Registration Based on Hybrid Point Sampling and Matching
Apr 23, 2023



Patch-to-point matching has become a robust way of point cloud registration. However, previous patch-matching methods employ superpoints with poor localization precision as nodes, which may lead to ambiguous patch partitions. In this paper, we propose a HybridPoint-based network to find more robust and accurate correspondences. Firstly, we propose to use salient points with prominent local features as nodes to increase patch repeatability, and introduce some uniformly distributed points to complete the point cloud, thus constituting hybrid points. Hybrid points not only have better localization precision but also give a complete picture of the whole point cloud. Furthermore, based on the characteristic of hybrid points, we propose a dual-classes patch matching module, which leverages the matching results of salient points and filters the matching noise of non-salient points. Experiments show that our model achieves state-of-the-art performance on 3DMatch, 3DLoMatch, and KITTI odometry, especially with 93.0% Registration Recall on the 3DMatch dataset. Our code and models are available at https://github.com/liyih/HybridPoint.