 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLP Splatting: Object-Centric Neural Fields
Jun 02, 20263D representations are fundamental to scene rendering, understanding, and interaction. Recent approaches, such as 3D Gaussian Splatting and Neural Radiance Fields, achieve impressive photorealistic novel-view synthesis, but lack the ability to easily decompose scene elements into a few primitives, requiring additional segmentation or grouping for object-level manipulation. We present MLP-Splatting, a method that enables scene decomposition via a few expressive light-field primitives while providing photorealistic novel-view synthesis. MLP-Splatting models each primitive as an independent compact MLP with localized spatial support that predicts radiance and opacity. In contrast to low-level Gaussian primitives or a single global radiance field, our neural primitives provide greater expressive capacity while remaining spatially localized. Rendering is performed through efficient sparse volumetric compositing over ray-primitive interactions. Our primitives are supervised using RGB supervision alone, which yields primitives that represent local scene regions often corresponding to objects or object parts, enabling interactive object-level editing without segmentation masks by selecting a handful of primitives. Our method, augmented with optional semantic feature distillation, enables open-vocabulary scene interaction and open-set instant segmentation. Compared to state-of-the-art methods, we achieve substantially lower memory usage (1/15$\times$) and faster rendering (3$\times$), as we show in our experiments compared to semantic 3DGS methods. Project Page: https://shinjeongkim.com/mlp-splatting
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
KV-Tracker: Real-Time Pose Tracking with Transformers
Dec 27, 2025Multi-view 3D geometry networks offer a powerful prior but are prohibitively slow for real-time applications. We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos. Our method rapidly selects and manages a set of images as keyframes to map a scene or object via $π^3$ with full bidirectional attention. We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking. This allows for up to $15\times$ speedup during inference without the fear of drift or catastrophic forgetting. Our caching strategy is model-agnostic and can be applied to other off-the-shelf multi-view networks without retraining. We demonstrate KV-Tracker on both scene-level tracking and the more challenging task of on-the-fly object tracking and reconstruction without depth measurements or object priors. Experiments on the TUM RGB-D, 7-Scenes, Arctic and OnePose datasets show the strong performance of our system while maintaining high frame-rates up to ${\sim}27$ FPS.
EscherNet: A Generative Model for Scalable View Synthesis
Feb 06, 2024We introduce EscherNet, a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with a specialised camera positional encoding, allowing precise and continuous relative control of the camera transformation between an arbitrary number of reference and target views. EscherNet offers exceptional generality, flexibility, and scalability in view synthesis -- it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, despite being trained with a fixed number of 3 reference views to 3 target views. As a result, EscherNet not only addresses zero-shot novel view synthesis, but also naturally unifies single- and multi-image 3D reconstruction, combining these diverse tasks into a single, cohesive framework. Our extensive experiments demonstrate that EscherNet achieves state-of-the-art performance in multiple benchmarks, even when compared to methods specifically tailored for each individual problem. This remarkable versatility opens up new directions for designing scalable neural architectures for 3D vision. Project page: \url{https://kxhit.github.io/EscherNet}.
vMAP: Vectorised Object Mapping for Neural Field SLAM
Feb 03, 2023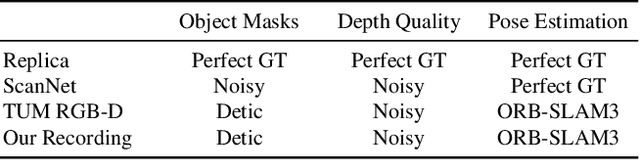
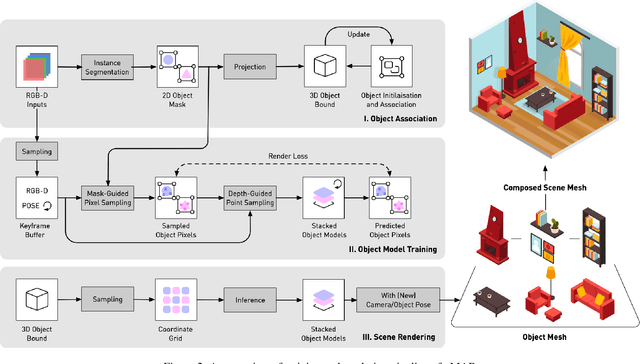


We present vMAP, an object-level dense SLAM system using neural field representations. Each object is represented by a small MLP, enabling efficient, watertight object modelling without the need for 3D priors. As an RGB-D camera browses a scene with no prior information, vMAP detects object instances on-the-fly, and dynamically adds them to its map. Specifically, thanks to the power of vectorised training, vMAP can optimise as many as 50 individual objects in a single scene, with an extremely efficient training speed of 5Hz map update. We experimentally demonstrate significantly improved scene-level and object-level reconstruction quality compared to prior neural field SLAM systems.
DA$^2$ Dataset: Toward Dexterity-Aware Dual-Arm Grasping
Jul 31, 2022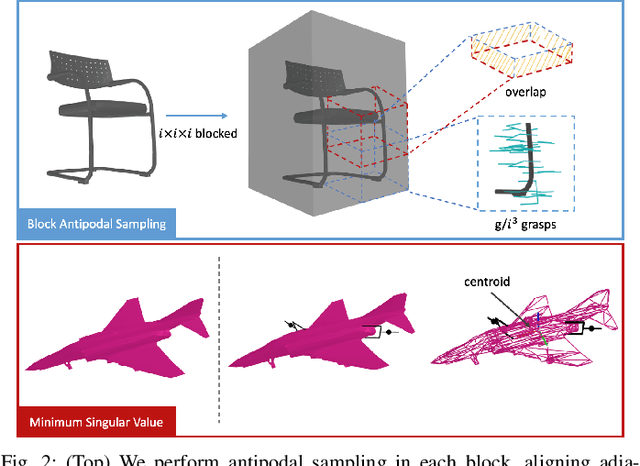
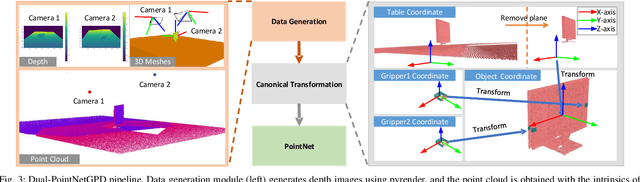
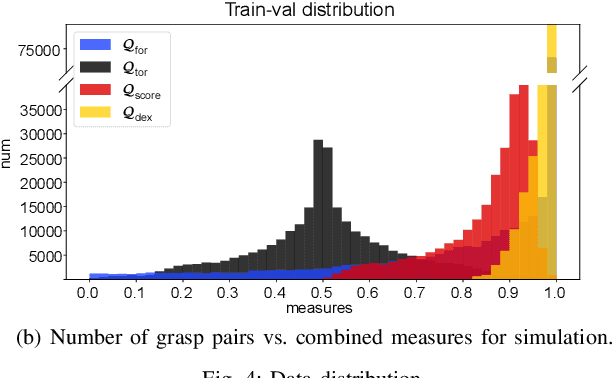
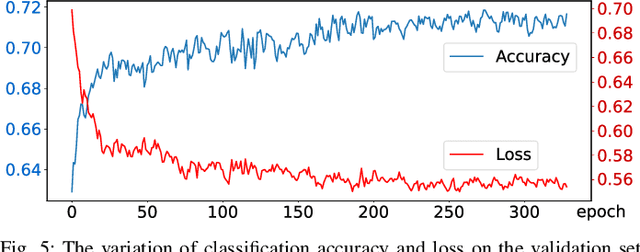
In this paper, we introduce DA$^2$, the first large-scale dual-arm dexterity-aware dataset for the generation of optimal bimanual grasping pairs for arbitrary large objects. The dataset contains about 9M pairs of parallel-jaw grasps, generated from more than 6000 objects and each labeled with various grasp dexterity measures. In addition, we propose an end-to-end dual-arm grasp evaluation model trained on the rendered scenes from this dataset. We utilize the evaluation model as our baseline to show the value of this novel and nontrivial dataset by both online analysis and real robot experiments. All data and related code will be open-sourced at https://sites.google.com/view/da2dataset.
Semantic Segmentation-assisted Scene Completion for LiDAR Point Clouds
Sep 23, 2021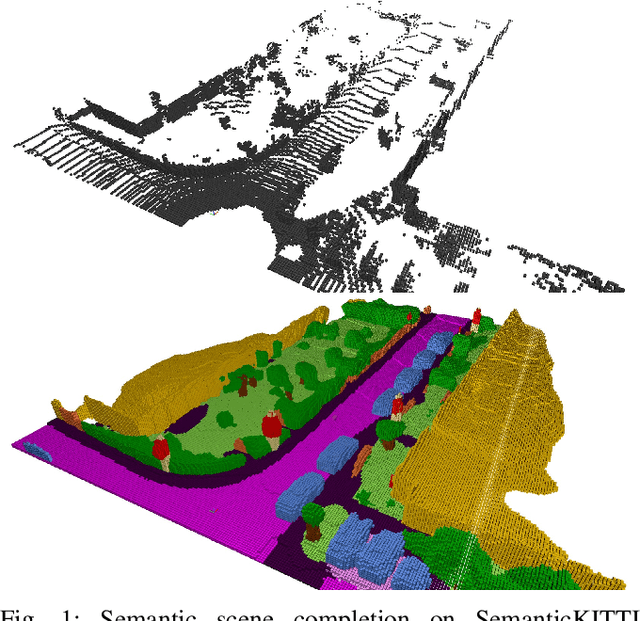
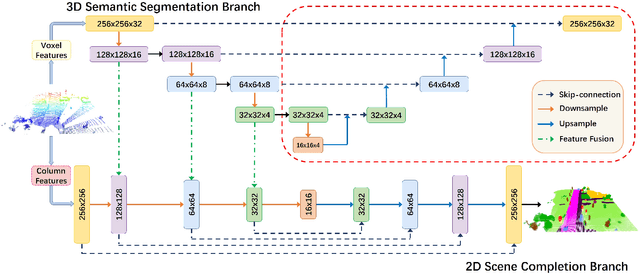
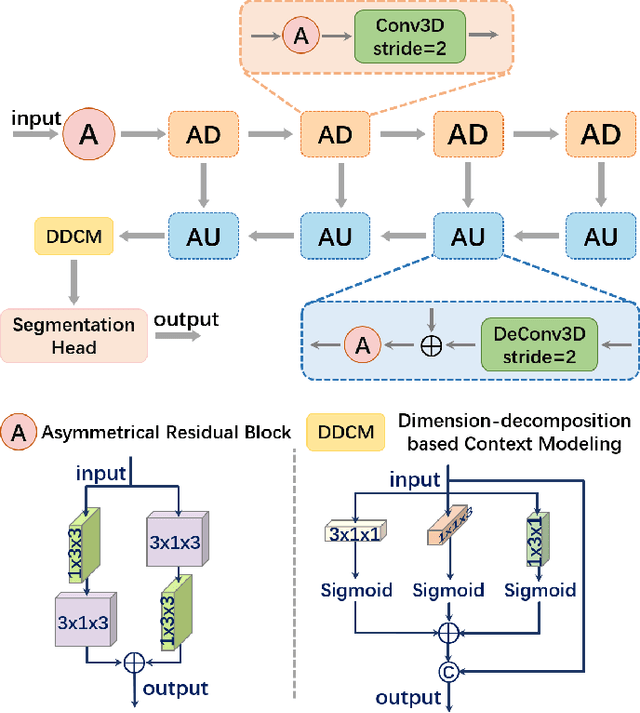
Outdoor scene completion is a challenging issue in 3D scene understanding, which plays an important role in intelligent robotics and autonomous driving. Due to the sparsity of LiDAR acquisition, it is far more complex for 3D scene completion and semantic segmentation. Since semantic features can provide constraints and semantic priors for completion tasks, the relationship between them is worth exploring. Therefore, we propose an end-to-end semantic segmentation-assisted scene completion network, including a 2D completion branch and a 3D semantic segmentation branch. Specifically, the network takes a raw point cloud as input, and merges the features from the segmentation branch into the completion branch hierarchically to provide semantic information. By adopting BEV representation and 3D sparse convolution, we can benefit from the lower operand while maintaining effective expression. Besides, the decoder of the segmentation branch is used as an auxiliary, which can be discarded in the inference stage to save computational consumption. Extensive experiments demonstrate that our method achieves competitive performance on SemanticKITTI dataset with low latency. Code and models will be released at https://github.com/jokester-zzz/SSA-SC.
SSC: Semantic Scan Context for Large-Scale Place Recognition
Jul 10, 2021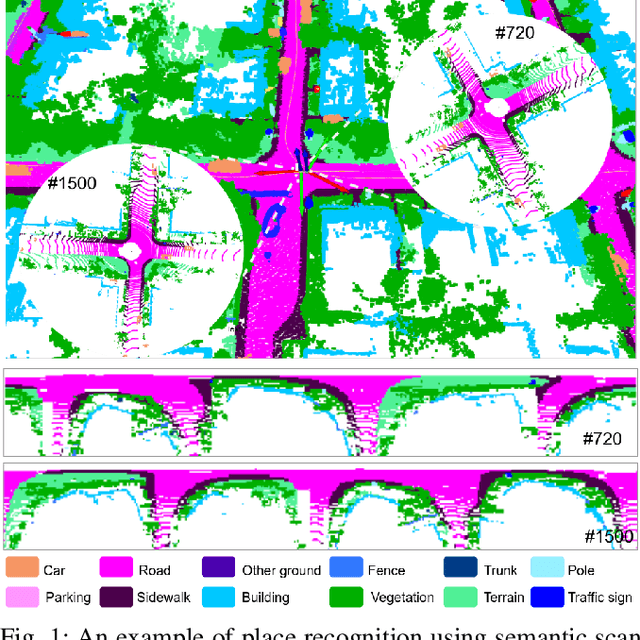

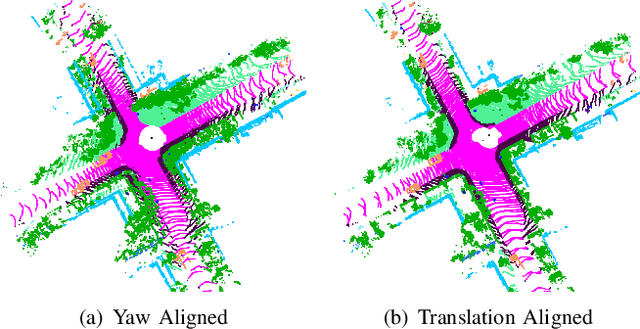
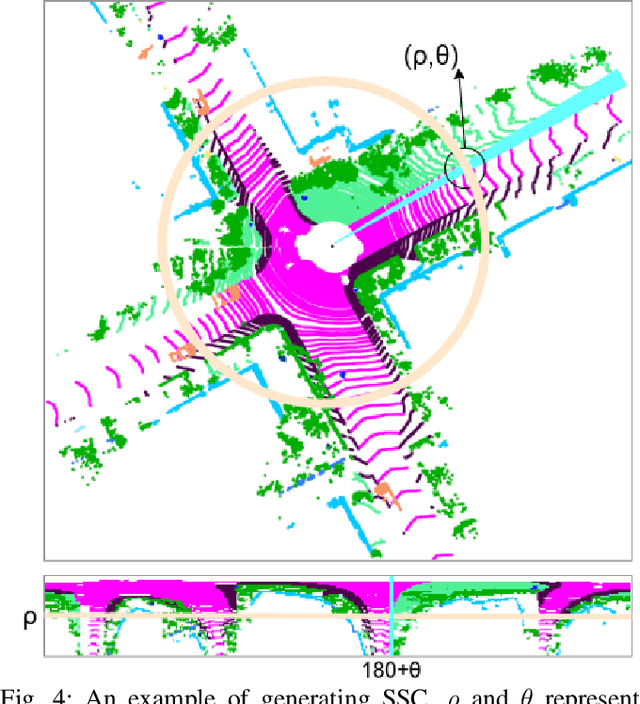
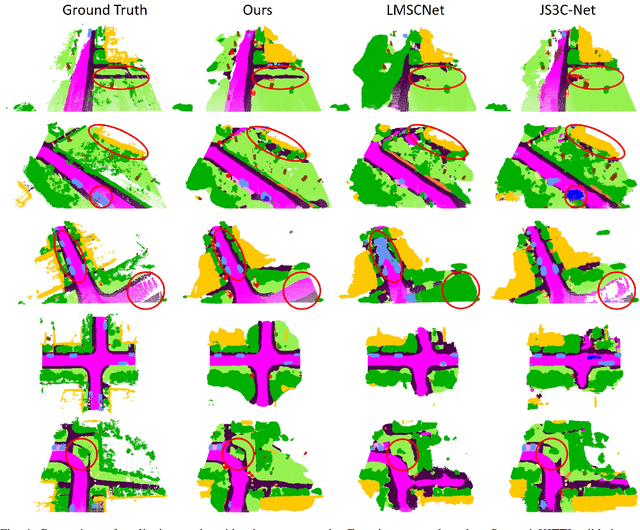
Place recognition gives a SLAM system the ability to correct cumulative errors. Unlike images that contain rich texture features, point clouds are almost pure geometric information which makes place recognition based on point clouds challenging. Existing works usually encode low-level features such as coordinate, normal, reflection intensity, etc., as local or global descriptors to represent scenes. Besides, they often ignore the translation between point clouds when matching descriptors. Different from most existing methods, we explore the use of high-level features, namely semantics, to improve the descriptor's representation ability. Also, when matching descriptors, we try to correct the translation between point clouds to improve accuracy. Concretely, we propose a novel global descriptor, Semantic Scan Context, which explores semantic information to represent scenes more effectively. We also present a two-step global semantic ICP to obtain the 3D pose (x, y, yaw) used to align the point cloud to improve matching performance. Our experiments on the KITTI dataset show that our approach outperforms the state-of-the-art methods with a large margin. Our code is available at: https://github.com/lilin-hitcrt/SSC.
SA-LOAM: Semantic-aided LiDAR SLAM with Loop Closure
Jul 01, 2021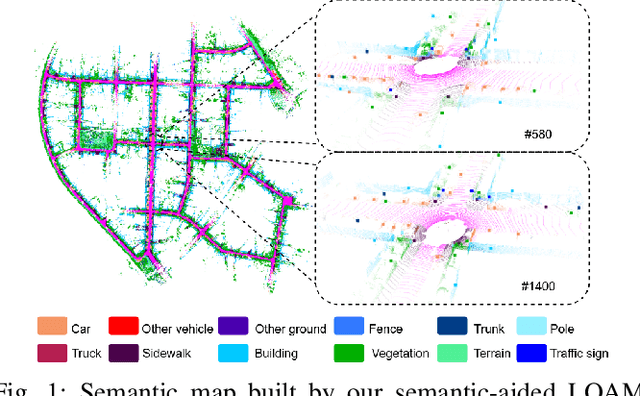
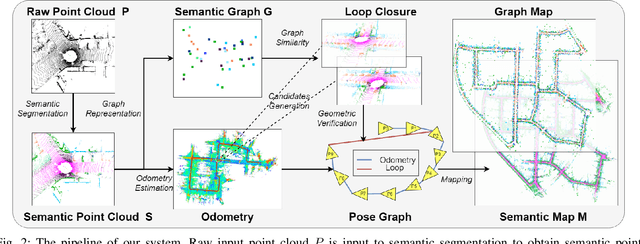

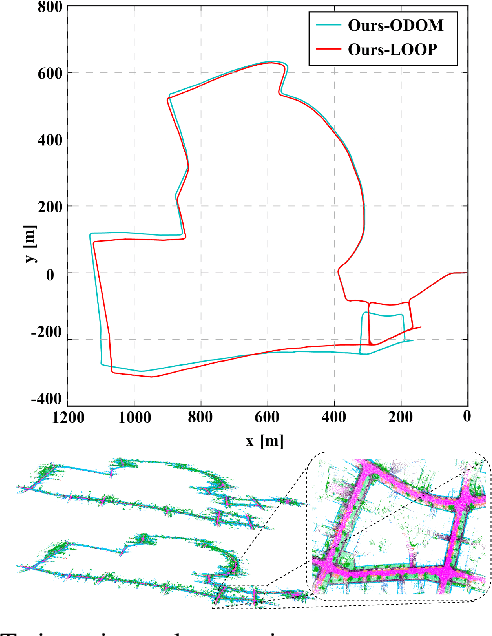
LiDAR-based SLAM system is admittedly more accurate and stable than others, while its loop closure detection is still an open issue. With the development of 3D semantic segmentation for point cloud, semantic information can be obtained conveniently and steadily, essential for high-level intelligence and conductive to SLAM. In this paper, we present a novel semantic-aided LiDAR SLAM with loop closure based on LOAM, named SA-LOAM, which leverages semantics in odometry as well as loop closure detection. Specifically, we propose a semantic-assisted ICP, including semantically matching, downsampling and plane constraint, and integrates a semantic graph-based place recognition method in our loop closure detection module. Benefitting from semantics, we can improve the localization accuracy, detect loop closures effectively, and construct a global consistent semantic map even in large-scale scenes. Extensive experiments on KITTI and Ford Campus dataset show that our system significantly improves baseline performance, has generalization ability to unseen data and achieves competitive results compared with state-of-the-art methods.
FlowMOT: 3D Multi-Object Tracking by Scene Flow Association
Dec 15, 2020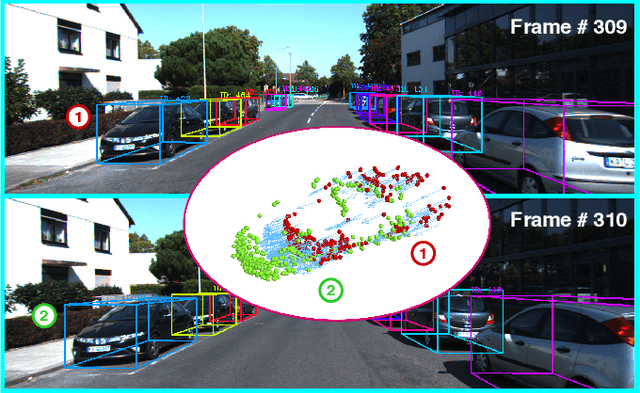

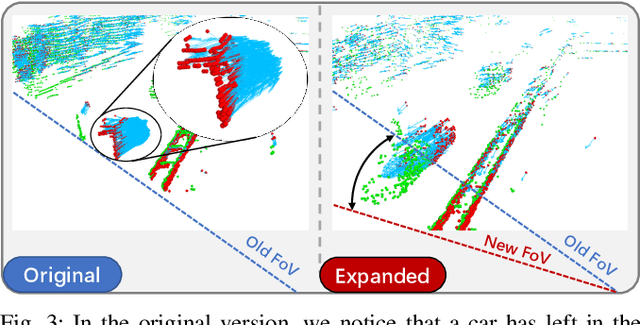

Most end-to-end Multi-Object Tracking (MOT) methods face the problems of low accuracy and poor generalization ability. Although traditional filter-based methods can achieve better results, they are difficult to be endowed with optimal hyperparameters and often fail in varying scenarios. To alleviate these drawbacks, we propose a LiDAR-based 3D MOT framework named FlowMOT, which integrates point-wise motion information into the traditional matching algorithm, enhancing the robustness of the data association. We firstly utilize a scene flow estimation network to obtain implicit motion information between two adjacent frames and calculate the predicted detection for each old tracklet in the previous frame. Then we use Hungarian algorithm to generate optimal matching relations with the ID propagation strategy to finish the tracking task. Experiments on KITTI MOT dataset show that our approach outperforms recent end-to-end methods and achieves competitive performance with the state-of-the-art filter-based method. In addition, ours can work steadily in the various-speed scenes where the filter-based methods may fail.