 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuy versus Build an LLM: A Decision Framework for Governments
Feb 13, 2026Large Language Models (LLMs) represent a new frontier of digital infrastructure that can support a wide range of public-sector applications, from general purpose citizen services to specialized and sensitive state functions. When expanding AI access, governments face a set of strategic choices over whether to buy existing services, build domestic capabilities, or adopt hybrid approaches across different domains and use cases. These are critical decisions especially when leading model providers are often foreign corporations, and LLM outputs are increasingly treated as trusted inputs to public decision-making and public discourse. In practice, these decisions are not intended to mandate a single approach across all domains; instead, national AI strategies are typically pluralistic, with sovereign, commercial and open-source models coexisting to serve different purposes. Governments may rely on commercial models for non-sensitive or commodity tasks, while pursuing greater control for critical, high-risk or strategically important applications. This paper provides a strategic framework for making this decision by evaluating these options across dimensions including sovereignty, safety, cost, resource capability, cultural fit, and sustainability. Importantly, "building" does not imply that governments must act alone: domestic capabilities may be developed through public research institutions, universities, state-owned enterprises, joint ventures, or broader national ecosystems. By detailing the technical requirements and practical challenges of each pathway, this work aims to serve as a reference for policy-makers to determine whether a buy or build approach best aligns with their specific national needs and societal goals.
Do Prompts Guarantee Safety? Mitigating Toxicity from LLM Generations through Subspace Intervention
Feb 06, 2026Large Language Models (LLMs) are powerful text generators, yet they can produce toxic or harmful content even when given seemingly harmless prompts. This presents a serious safety challenge and can cause real-world harm. Toxicity is often subtle and context-dependent, making it difficult to detect at the token level or through coarse sentence-level signals. Moreover, efforts to mitigate toxicity often face a trade-off between safety and the coherence, or fluency of the generated text. In this work, we present a targeted subspace intervention strategy for identifying and suppressing hidden toxic patterns from underlying model representations, while preserving overall ability to generate safe fluent content. On the RealToxicityPrompts, our method achieves strong mitigation performance compared to existing baselines, with minimal impact on inference complexity. Across multiple LLMs, our approach reduces toxicity of state-of-the-art detoxification systems by 8-20%, while maintaining comparable fluency. Through extensive quantitative and qualitative analyses, we show that our approach achieves effective toxicity reduction without impairing generative performance, consistently outperforming existing baselines.
Reasoning LLMs are Wandering Solution Explorers
May 26, 2025Large Language Models (LLMs) have demonstrated impressive reasoning abilities through test-time computation (TTC) techniques such as chain-of-thought prompting and tree-based reasoning. However, we argue that current reasoning LLMs (RLLMs) lack the ability to systematically explore the solution space. This paper formalizes what constitutes systematic problem solving and identifies common failure modes that reveal reasoning LLMs to be wanderers rather than systematic explorers. Through qualitative and quantitative analysis across multiple state-of-the-art LLMs, we uncover persistent issues: invalid reasoning steps, redundant explorations, hallucinated or unfaithful conclusions, and so on. Our findings suggest that current models' performance can appear to be competent on simple tasks yet degrade sharply as complexity increases. Based on the findings, we advocate for new metrics and tools that evaluate not just final outputs but the structure of the reasoning process itself.
Bullying the Machine: How Personas Increase LLM Vulnerability
May 19, 2025Large Language Models (LLMs) are increasingly deployed in interactions where they are prompted to adopt personas. This paper investigates whether such persona conditioning affects model safety under bullying, an adversarial manipulation that applies psychological pressures in order to force the victim to comply to the attacker. We introduce a simulation framework in which an attacker LLM engages a victim LLM using psychologically grounded bullying tactics, while the victim adopts personas aligned with the Big Five personality traits. Experiments using multiple open-source LLMs and a wide range of adversarial goals reveal that certain persona configurations -- such as weakened agreeableness or conscientiousness -- significantly increase victim's susceptibility to unsafe outputs. Bullying tactics involving emotional or sarcastic manipulation, such as gaslighting and ridicule, are particularly effective. These findings suggest that persona-driven interaction introduces a novel vector for safety risks in LLMs and highlight the need for persona-aware safety evaluation and alignment strategies.
Technical Report for ICML 2024 TiFA Workshop MLLM Attack Challenge: Suffix Injection and Projected Gradient Descent Can Easily Fool An MLLM
Dec 20, 2024


This technical report introduces our top-ranked solution that employs two approaches, \ie suffix injection and projected gradient descent (PGD) , to address the TiFA workshop MLLM attack challenge. Specifically, we first append the text from an incorrectly labeled option (pseudo-labeled) to the original query as a suffix. Using this modified query, our second approach applies the PGD method to add imperceptible perturbations to the image. Combining these two techniques enables successful attacks on the LLaVA 1.5 model.
Strong Preferences Affect the Robustness of Value Alignment
Oct 03, 2024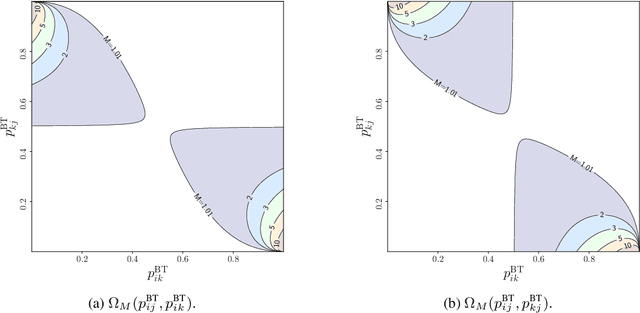
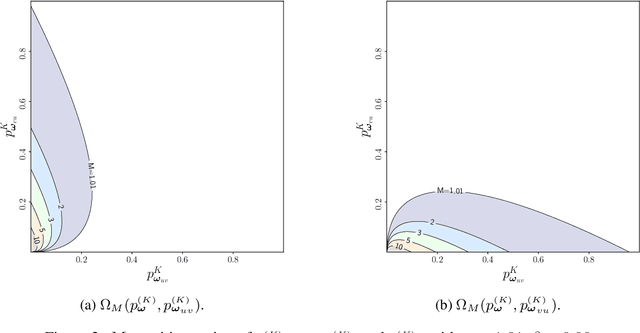
Value alignment, which aims to ensure that large language models (LLMs) and other AI agents behave in accordance with human values, is critical for ensuring safety and trustworthiness of these systems. A key component of value alignment is the modeling of human preferences as a representation of human values. In this paper, we investigate the robustness of value alignment by examining the sensitivity of preference models. Specifically, we ask: how do changes in the probabilities of some preferences affect the predictions of these models for other preferences? To answer this question, we theoretically analyze the robustness of widely used preference models by examining their sensitivities to minor changes in preferences they model. Our findings reveal that, in the Bradley-Terry and the Placket-Luce model, the probability of a preference can change significantly as other preferences change, especially when these preferences are dominant (i.e., with probabilities near 0 or 1). We identify specific conditions where this sensitivity becomes significant for these models and discuss the practical implications for the robustness and safety of value alignment in AI systems.
Rehearsing Answers to Probable Questions with Perspective-Taking
Sep 27, 2024

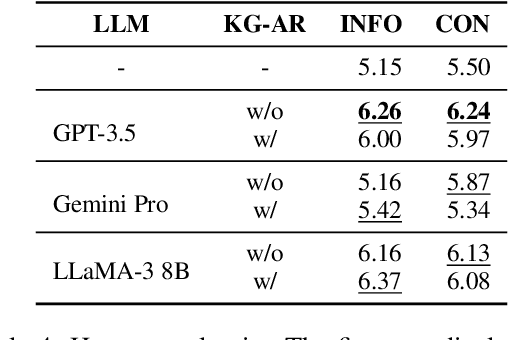
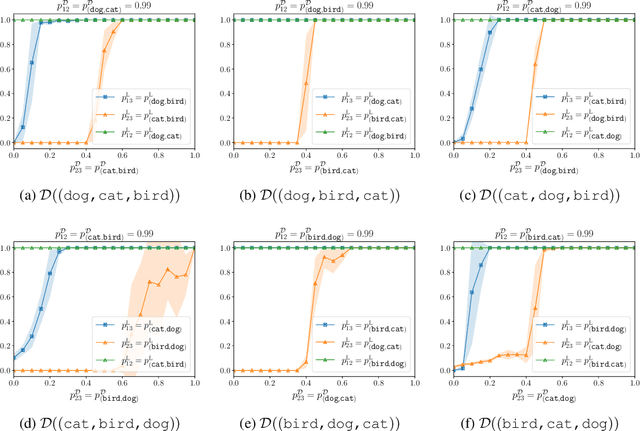
Question answering (QA) has been a long-standing focus in the NLP field, predominantly addressing reading comprehension and common sense QA. However, scenarios involving the preparation of answers to probable questions during professional oral presentations remain underexplored. In this paper, we pioneer the examination of this crucial yet overlooked topic by utilizing real-world QA conversation transcripts between company managers and professional analysts. We explore the proposed task using three causal knowledge graphs (KGs) and three large language models (LLMs). This work provides foundational insights into the application of LLMs in professional QA scenarios, highlighting the importance of causal KGs and perspective-taking in generating effective responses.
Bridging the Intent Gap: Knowledge-Enhanced Visual Generation
May 21, 2024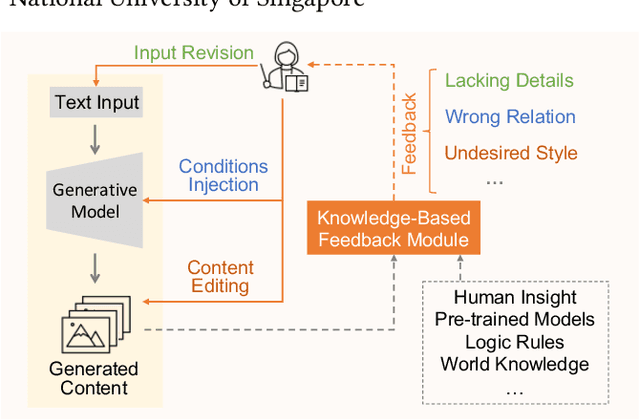
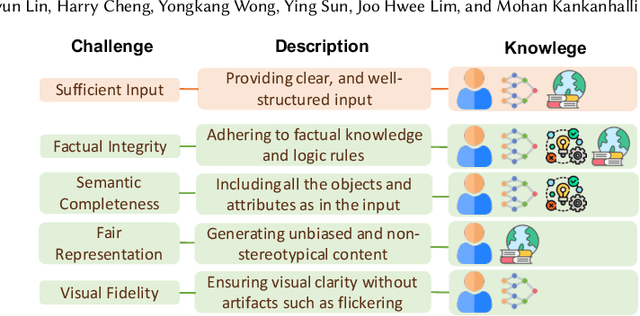
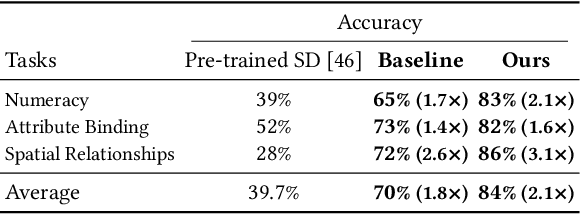
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Jan 22, 2024Hallucination has been widely recognized to be a significant drawback for large language models (LLMs). There have been many works that attempt to reduce the extent of hallucination. These efforts have mostly been empirical so far, which cannot answer the fundamental question whether it can be completely eliminated. In this paper, we formalize the problem and show that it is impossible to eliminate hallucination in LLMs. Specifically, we define a formal world where hallucination is defined as inconsistencies between a computable LLM and a computable ground truth function. By employing results from learning theory, we show that LLMs cannot learn all of the computable functions and will therefore always hallucinate. Since the formal world is a part of the real world which is much more complicated, hallucinations are also inevitable for real world LLMs. Furthermore, for real world LLMs constrained by provable time complexity, we describe the hallucination-prone tasks and empirically validate our claims. Finally, using the formal world framework, we discuss the possible mechanisms and efficacies of existing hallucination mitigators as well as the practical implications on the safe deployment of LLMs.
A Study on Differentiable Logic and LLMs for EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2023
Jul 13, 2023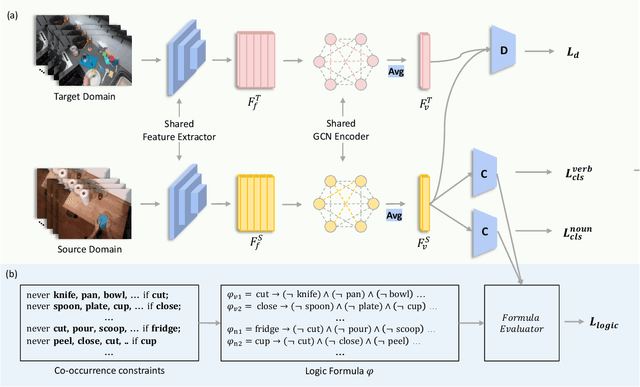
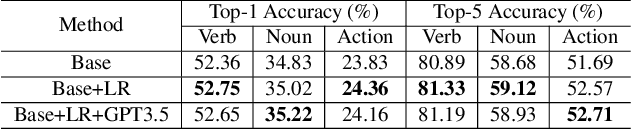
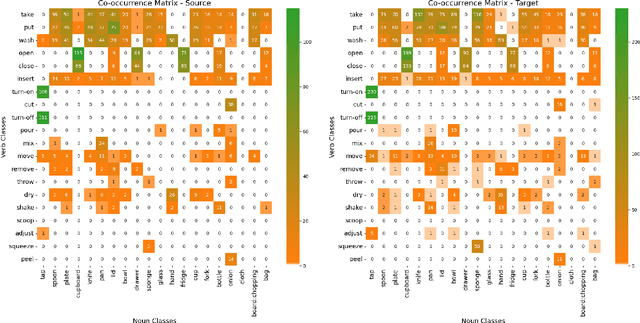

In this technical report, we present our findings from a study conducted on the EPIC-KITCHENS-100 Unsupervised Domain Adaptation task for Action Recognition. Our research focuses on the innovative application of a differentiable logic loss in the training to leverage the co-occurrence relations between verb and noun, as well as the pre-trained Large Language Models (LLMs) to generate the logic rules for the adaptation to unseen action labels. Specifically, the model's predictions are treated as the truth assignment of a co-occurrence logic formula to compute the logic loss, which measures the consistency between the predictions and the logic constraints. By using the verb-noun co-occurrence matrix generated from the dataset, we observe a moderate improvement in model performance compared to our baseline framework. To further enhance the model's adaptability to novel action labels, we experiment with rules generated using GPT-3.5, which leads to a slight decrease in performance. These findings shed light on the potential and challenges of incorporating differentiable logic and LLMs for knowledge extraction in unsupervised domain adaptation for action recognition. Our final submission (entitled `NS-LLM') achieved the first place in terms of top-1 action recognition accuracy.