 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRehearsing Answers to Probable Questions with Perspective-Taking
Sep 27, 2024

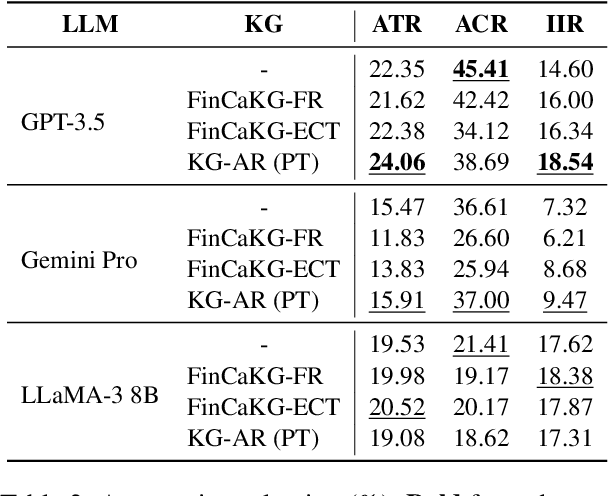
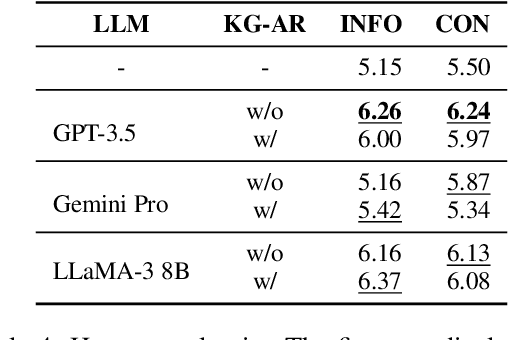
Question answering (QA) has been a long-standing focus in the NLP field, predominantly addressing reading comprehension and common sense QA. However, scenarios involving the preparation of answers to probable questions during professional oral presentations remain underexplored. In this paper, we pioneer the examination of this crucial yet overlooked topic by utilizing real-world QA conversation transcripts between company managers and professional analysts. We explore the proposed task using three causal knowledge graphs (KGs) and three large language models (LLMs). This work provides foundational insights into the application of LLMs in professional QA scenarios, highlighting the importance of causal KGs and perspective-taking in generating effective responses.
A Survey of Useful LLM Evaluation
Jun 03, 2024LLMs have gotten attention across various research domains due to their exceptional performance on a wide range of complex tasks. Therefore, refined methods to evaluate the capabilities of LLMs are needed to determine the tasks and responsibility they should undertake. Our study mainly discussed how LLMs, as useful tools, should be effectively assessed. We proposed the two-stage framework: from ``core ability'' to ``agent'', clearly explaining how LLMs can be applied based on their specific capabilities, along with the evaluation methods in each stage. Core ability refers to the capabilities that LLMs need in order to generate high-quality natural language texts. After confirming LLMs possess core ability, they can solve real-world and complex tasks as agent. In the "core ability" stage, we discussed the reasoning ability, societal impact, and domain knowledge of LLMs. In the ``agent'' stage, we demonstrated embodied action, planning, and tool learning of LLMs agent applications. Finally, we examined the challenges currently confronting the evaluation methods for LLMs, as well as the directions for future development.