 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Useful LLM Evaluation
Jun 03, 2024LLMs have gotten attention across various research domains due to their exceptional performance on a wide range of complex tasks. Therefore, refined methods to evaluate the capabilities of LLMs are needed to determine the tasks and responsibility they should undertake. Our study mainly discussed how LLMs, as useful tools, should be effectively assessed. We proposed the two-stage framework: from ``core ability'' to ``agent'', clearly explaining how LLMs can be applied based on their specific capabilities, along with the evaluation methods in each stage. Core ability refers to the capabilities that LLMs need in order to generate high-quality natural language texts. After confirming LLMs possess core ability, they can solve real-world and complex tasks as agent. In the "core ability" stage, we discussed the reasoning ability, societal impact, and domain knowledge of LLMs. In the ``agent'' stage, we demonstrated embodied action, planning, and tool learning of LLMs agent applications. Finally, we examined the challenges currently confronting the evaluation methods for LLMs, as well as the directions for future development.
Measuring Taiwanese Mandarin Language Understanding
Mar 29, 2024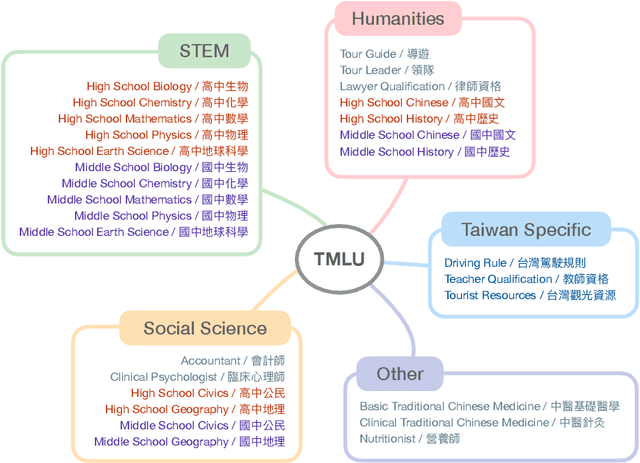

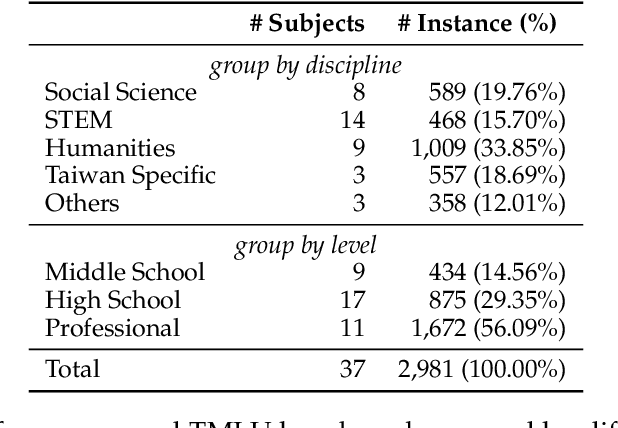

The evaluation of large language models (LLMs) has drawn substantial attention in the field recently. This work focuses on evaluating LLMs in a Chinese context, specifically, for Traditional Chinese which has been largely underrepresented in existing benchmarks. We present TMLU, a holistic evaluation suit tailored for assessing the advanced knowledge and reasoning capability in LLMs, under the context of Taiwanese Mandarin. TMLU consists of an array of 37 subjects across social science, STEM, humanities, Taiwan-specific content, and others, ranging from middle school to professional levels. In addition, we curate chain-of-thought-like few-shot explanations for each subject to facilitate the evaluation of complex reasoning skills. To establish a comprehensive baseline, we conduct extensive experiments and analysis on 24 advanced LLMs. The results suggest that Chinese open-weight models demonstrate inferior performance comparing to multilingual proprietary ones, and open-weight models tailored for Taiwanese Mandarin lag behind the Simplified-Chinese counterparts. The findings indicate great headrooms for improvement, and emphasize the goal of TMLU to foster the development of localized Taiwanese-Mandarin LLMs. We release the benchmark and evaluation scripts for the community to promote future research.
IF-Net: An Illumination-invariant Feature Network
Aug 10, 2020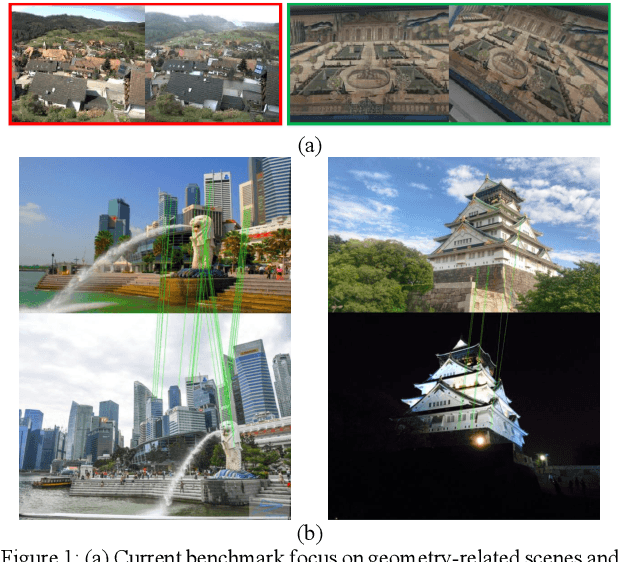
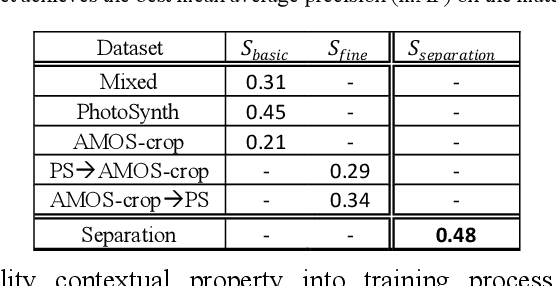


Feature descriptor matching is a critical step is many computer vision applications such as image stitching, image retrieval and visual localization. However, it is often affected by many practical factors which will degrade its performance. Among these factors, illumination variations are the most influential one, and especially no previous descriptor learning works focus on dealing with this problem. In this paper, we propose IF-Net, aimed to generate a robust and generic descriptor under crucial illumination changes conditions. We find out not only the kind of training data important but also the order it is presented. To this end, we investigate several dataset scheduling methods and propose a separation training scheme to improve the matching accuracy. Further, we propose a ROI loss and hard-positive mining strategy along with the training scheme, which can strengthen the ability of generated descriptor dealing with large illumination change conditions. We evaluate our approach on public patch matching benchmark and achieve the best results compared with several state-of-the-arts methods. To show the practicality, we further evaluate IF-Net on the task of visual localization under large illumination changes scenes, and achieves the best localization accuracy.