 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
Feb 13, 2026Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
AdaSearch: Balancing Parametric Knowledge and Search in Large Language Models via Reinforcement Learning
Dec 18, 2025Equipping large language models (LLMs) with search engines via reinforcement learning (RL) has emerged as an effective approach for building search agents. However, overreliance on search introduces unnecessary cost and risks exposure to noisy or malicious content, while relying solely on parametric knowledge risks hallucination. The central challenge is to develop agents that adaptively balance parametric knowledge with external search, invoking search only when necessary. Prior work mitigates search overuse by shaping rewards around the number of tool calls. However, these penalties require substantial reward engineering, provide ambiguous credit assignment, and can be exploited by agents that superficially reduce calls. Moreover, evaluating performance solely through call counts conflates necessary and unnecessary search, obscuring the measurement of true adaptive behavior. To address these limitations, we first quantify the self-knowledge awareness of existing search agents via an F1-based decision metric, revealing that methods such as Search-R1 often overlook readily available parametric knowledge. Motivated by these findings, we propose AdaSearch, a simple two-stage, outcome-driven RL framework that disentangles problem solving from the decision of whether to invoke search, and makes this decision process explicit and interpretable. This transparency is crucial for high-stakes domains such as finance and medical question answering, yet is largely neglected by prior approaches. Experiments across multiple model families and sizes demonstrate that AdaSearch substantially improves knowledge-boundary awareness, reduces unnecessary search calls, preserves strong task performance, and offers more transparent, interpretable decision behaviors.
Evaluating Large Language Models as Expert Annotators
Aug 11, 2025Textual data annotation, the process of labeling or tagging text with relevant information, is typically costly, time-consuming, and labor-intensive. While large language models (LLMs) have demonstrated their potential as direct alternatives to human annotators for general domains natural language processing (NLP) tasks, their effectiveness on annotation tasks in domains requiring expert knowledge remains underexplored. In this paper, we investigate: whether top-performing LLMs, which might be perceived as having expert-level proficiency in academic and professional benchmarks, can serve as direct alternatives to human expert annotators? To this end, we evaluate both individual LLMs and multi-agent approaches across three highly specialized domains: finance, biomedicine, and law. Specifically, we propose a multi-agent discussion framework to simulate a group of human annotators, where LLMs are tasked to engage in discussions by considering others' annotations and justifications before finalizing their labels. Additionally, we incorporate reasoning models (e.g., o3-mini) to enable a more comprehensive comparison. Our empirical results reveal that: (1) Individual LLMs equipped with inference-time techniques (e.g., chain-of-thought (CoT), self-consistency) show only marginal or even negative performance gains, contrary to prior literature suggesting their broad effectiveness. (2) Overall, reasoning models do not demonstrate statistically significant improvements over non-reasoning models in most settings. This suggests that extended long CoT provides relatively limited benefits for data annotation in specialized domains. (3) Certain model behaviors emerge in the multi-agent discussion environment. For instance, Claude 3.7 Sonnet with thinking rarely changes its initial annotations, even when other agents provide correct annotations or valid reasoning.
Do LLM Evaluators Prefer Themselves for a Reason?
Apr 04, 2025Large language models (LLMs) are increasingly used as automatic evaluators in applications such as benchmarking, reward modeling, and self-refinement. Prior work highlights a potential self-preference bias where LLMs favor their own generated responses, a tendency often intensifying with model size and capability. This raises a critical question: Is self-preference detrimental, or does it simply reflect objectively superior outputs from more capable models? Disentangling these has been challenging due to the usage of subjective tasks in previous studies. To address this, we investigate self-preference using verifiable benchmarks (mathematical reasoning, factual knowledge, code generation) that allow objective ground-truth assessment. This enables us to distinguish harmful self-preference (favoring objectively worse responses) from legitimate self-preference (favoring genuinely superior ones). We conduct large-scale experiments under controlled evaluation conditions across diverse model families (e.g., Llama, Qwen, Gemma, Mistral, Phi, GPT, DeepSeek). Our findings reveal three key insights: (1) Better generators are better judges -- LLM evaluators' accuracy strongly correlates with their task performance, and much of the self-preference in capable models is legitimate. (2) Harmful self-preference persists, particularly when evaluator models perform poorly as generators on specific task instances. Stronger models exhibit more pronounced harmful bias when they err, though such incorrect generations are less frequent. (3) Inference-time scaling strategies, such as generating a long Chain-of-Thought before evaluation, effectively reduce the harmful self-preference. These results provide a more nuanced understanding of LLM-based evaluation and practical insights for improving its reliability.
Are Expert-Level Language Models Expert-Level Annotators?
Oct 04, 2024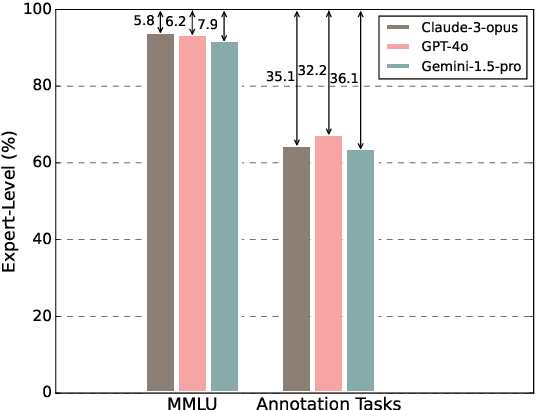
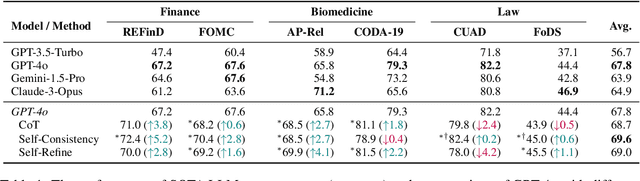
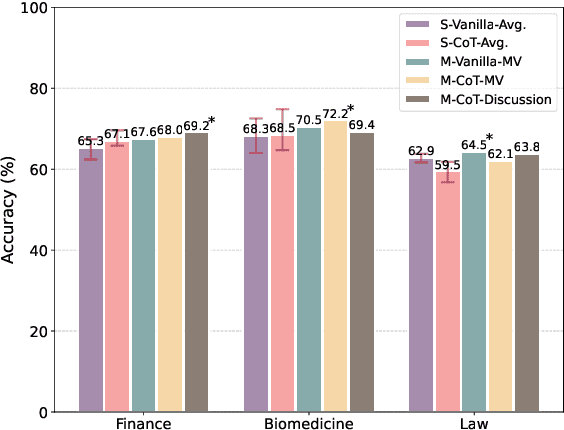
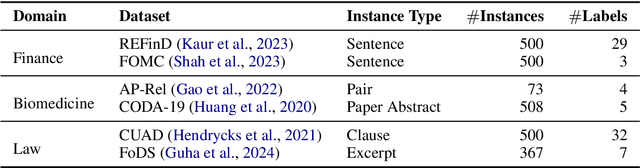
Data annotation refers to the labeling or tagging of textual data with relevant information. A large body of works have reported positive results on leveraging LLMs as an alternative to human annotators. However, existing studies focus on classic NLP tasks, and the extent to which LLMs as data annotators perform in domains requiring expert knowledge remains underexplored. In this work, we investigate comprehensive approaches across three highly specialized domains and discuss practical suggestions from a cost-effectiveness perspective. To the best of our knowledge, we present the first systematic evaluation of LLMs as expert-level data annotators.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024
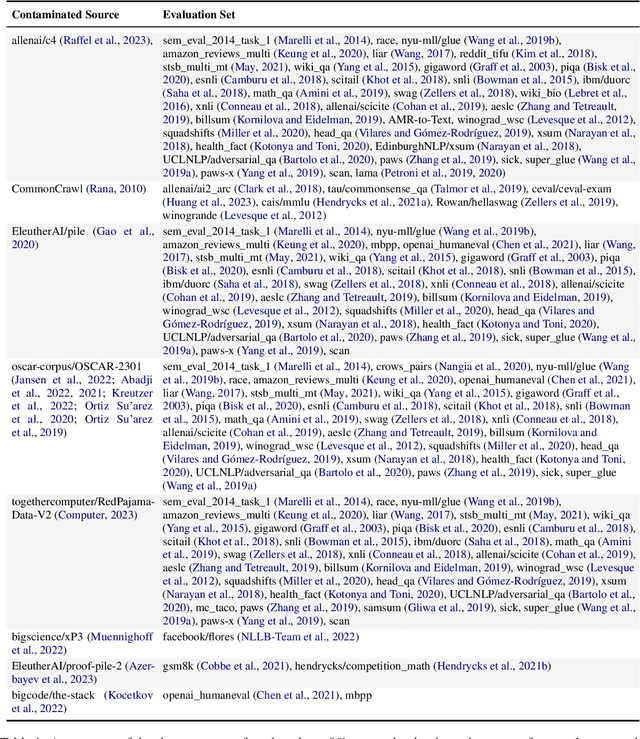
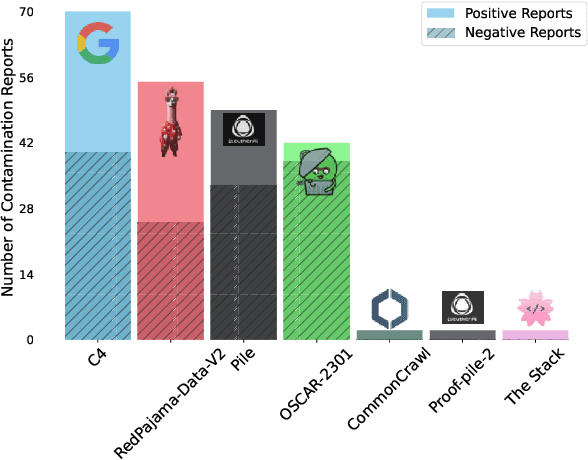
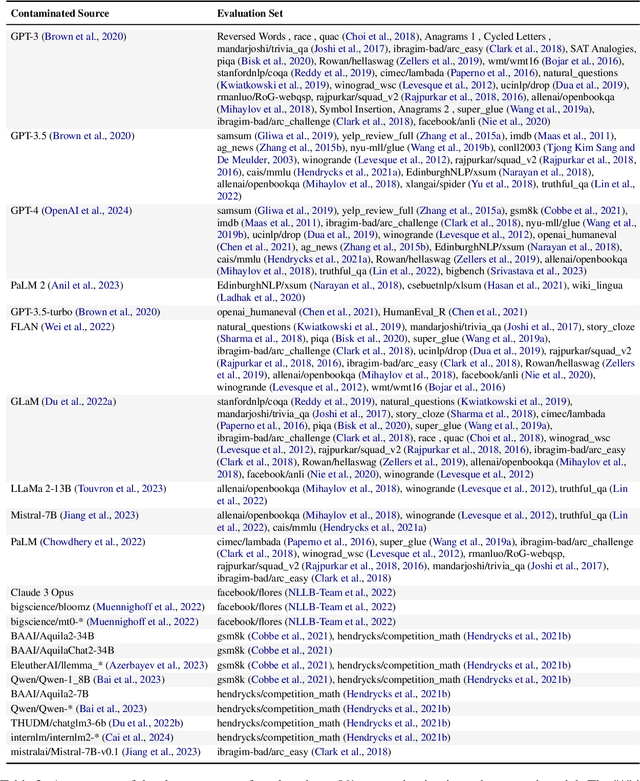
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
InstructRAG: Instructing Retrieval-Augmented Generation with Explicit Denoising
Jun 19, 2024Retrieval-augmented generation (RAG) has shown promising potential to enhance the accuracy and factuality of language models (LMs). However, imperfect retrievers or noisy corpora can introduce misleading or even erroneous information to the retrieved contents, posing a significant challenge to the generation quality. Existing RAG methods typically address this challenge by directly predicting final answers despite potentially noisy inputs, resulting in an implicit denoising process that is difficult to interpret and verify. On the other hand, the acquisition of explicit denoising supervision is often costly, involving significant human efforts. In this work, we propose InstructRAG, where LMs explicitly learn the denoising process through self-synthesized rationales -- First, we instruct the LM to explain how the ground-truth answer is derived from retrieved documents. Then, these rationales can be used either as demonstrations for in-context learning of explicit denoising or as supervised fine-tuning data to train the model. Compared to standard RAG approaches, InstructRAG requires no additional supervision, allows for easier verification of the predicted answers, and effectively improves generation accuracy. Experiments show InstructRAG consistently outperforms existing RAG methods in both training-free and trainable scenarios, achieving a relative improvement of 8.3% over the best baseline method on average across five knowledge-intensive benchmarks. Extensive analysis indicates that InstructRAG scales well with increased numbers of retrieved documents and consistently exhibits robust denoising ability even in out-of-domain datasets, demonstrating strong generalizability.
Measuring Taiwanese Mandarin Language Understanding
Mar 29, 2024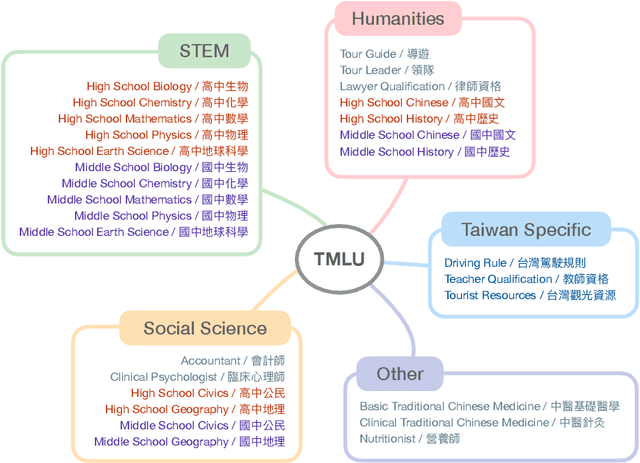

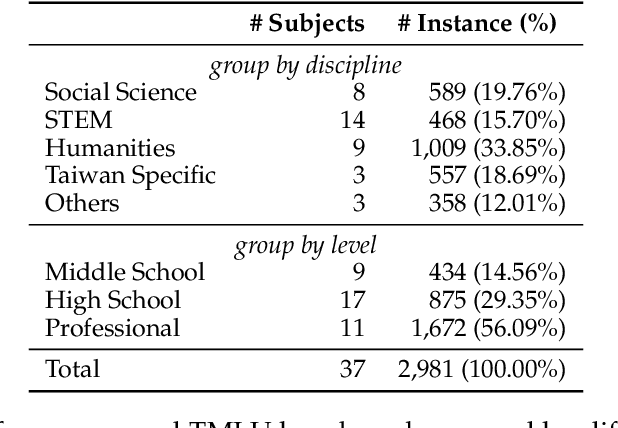

The evaluation of large language models (LLMs) has drawn substantial attention in the field recently. This work focuses on evaluating LLMs in a Chinese context, specifically, for Traditional Chinese which has been largely underrepresented in existing benchmarks. We present TMLU, a holistic evaluation suit tailored for assessing the advanced knowledge and reasoning capability in LLMs, under the context of Taiwanese Mandarin. TMLU consists of an array of 37 subjects across social science, STEM, humanities, Taiwan-specific content, and others, ranging from middle school to professional levels. In addition, we curate chain-of-thought-like few-shot explanations for each subject to facilitate the evaluation of complex reasoning skills. To establish a comprehensive baseline, we conduct extensive experiments and analysis on 24 advanced LLMs. The results suggest that Chinese open-weight models demonstrate inferior performance comparing to multilingual proprietary ones, and open-weight models tailored for Taiwanese Mandarin lag behind the Simplified-Chinese counterparts. The findings indicate great headrooms for improvement, and emphasize the goal of TMLU to foster the development of localized Taiwanese-Mandarin LLMs. We release the benchmark and evaluation scripts for the community to promote future research.
Fidelity-Enriched Contrastive Search: Reconciling the Faithfulness-Diversity Trade-Off in Text Generation
Oct 23, 2023In this paper, we address the hallucination problem commonly found in natural language generation tasks. Language models often generate fluent and convincing content but can lack consistency with the provided source, resulting in potential inaccuracies. We propose a new decoding method called Fidelity-Enriched Contrastive Search (FECS), which augments the contrastive search framework with context-aware regularization terms. FECS promotes tokens that are semantically similar to the provided source while penalizing repetitiveness in the generated text. We demonstrate its effectiveness across two tasks prone to hallucination: abstractive summarization and dialogue generation. Results show that FECS consistently enhances faithfulness across various language model sizes while maintaining output diversity comparable to well-performing decoding algorithms.
Large Language Models Perform Diagnostic Reasoning
Jul 18, 2023We explore the extension of chain-of-thought (CoT) prompting to medical reasoning for the task of automatic diagnosis. Motivated by doctors' underlying reasoning process, we present Diagnostic-Reasoning CoT (DR-CoT). Empirical results demonstrate that by simply prompting large language models trained only on general text corpus with two DR-CoT exemplars, the diagnostic accuracy improves by 15% comparing to standard prompting. Moreover, the gap reaches a pronounced 18% in out-domain settings. Our findings suggest expert-knowledge reasoning in large language models can be elicited through proper promptings.