 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Outcome Reward: Decoupling Search and Answering Improves LLM Agents
Oct 06, 2025Enabling large language models (LLMs) to utilize search tools offers a promising path to overcoming fundamental limitations such as knowledge cutoffs and hallucinations. Recent work has explored reinforcement learning (RL) for training search-augmented agents that interleave reasoning and retrieval before answering. These approaches usually rely on outcome-based rewards (e.g., exact match), implicitly assuming that optimizing for final answers will also yield effective intermediate search behaviors. Our analysis challenges this assumption: we uncover multiple systematic deficiencies in search that arise under outcome-only training and ultimately degrade final answer quality, including failure to invoke tools, invalid queries, and redundant searches. To address these shortcomings, we introduce DeSA (Decoupling Search-and-Answering), a simple two-stage training framework that explicitly separates search optimization from answer generation. In Stage 1, agents are trained to improve search effectiveness with retrieval recall-based rewards. In Stage 2, outcome rewards are employed to optimize final answer generation. Across seven QA benchmarks, DeSA-trained agents consistently improve search behaviors, delivering substantially higher search recall and answer accuracy than outcome-only baselines. Notably, DeSA outperforms single-stage training approaches that simultaneously optimize recall and outcome rewards, underscoring the necessity of explicitly decoupling the two objectives.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
May 22, 2025While reinforcement learning (RL) has demonstrated remarkable success in enhancing large language models (LLMs), it has primarily focused on single-turn tasks such as solving math problems. Training effective web agents for multi-turn interactions remains challenging due to the complexity of long-horizon decision-making across dynamic web interfaces. In this work, we present WebAgent-R1, a simple yet effective end-to-end multi-turn RL framework for training web agents. It learns directly from online interactions with web environments by asynchronously generating diverse trajectories, entirely guided by binary rewards depending on task success. Experiments on the WebArena-Lite benchmark demonstrate the effectiveness of WebAgent-R1, boosting the task success rate of Qwen-2.5-3B from 6.1% to 33.9% and Llama-3.1-8B from 8.5% to 44.8%, significantly outperforming existing state-of-the-art methods and strong proprietary models such as OpenAI o3. In-depth analyses reveal the effectiveness of the thinking-based prompting strategy and test-time scaling through increased interactions for web tasks. We further investigate different RL initialization policies by introducing two variants, namely WebAgent-R1-Zero and WebAgent-R1-CoT, which highlight the importance of the warm-up training stage (i.e., behavior cloning) and provide insights on incorporating long chain-of-thought (CoT) reasoning in web agents.
Do LLM Evaluators Prefer Themselves for a Reason?
Apr 04, 2025Large language models (LLMs) are increasingly used as automatic evaluators in applications such as benchmarking, reward modeling, and self-refinement. Prior work highlights a potential self-preference bias where LLMs favor their own generated responses, a tendency often intensifying with model size and capability. This raises a critical question: Is self-preference detrimental, or does it simply reflect objectively superior outputs from more capable models? Disentangling these has been challenging due to the usage of subjective tasks in previous studies. To address this, we investigate self-preference using verifiable benchmarks (mathematical reasoning, factual knowledge, code generation) that allow objective ground-truth assessment. This enables us to distinguish harmful self-preference (favoring objectively worse responses) from legitimate self-preference (favoring genuinely superior ones). We conduct large-scale experiments under controlled evaluation conditions across diverse model families (e.g., Llama, Qwen, Gemma, Mistral, Phi, GPT, DeepSeek). Our findings reveal three key insights: (1) Better generators are better judges -- LLM evaluators' accuracy strongly correlates with their task performance, and much of the self-preference in capable models is legitimate. (2) Harmful self-preference persists, particularly when evaluator models perform poorly as generators on specific task instances. Stronger models exhibit more pronounced harmful bias when they err, though such incorrect generations are less frequent. (3) Inference-time scaling strategies, such as generating a long Chain-of-Thought before evaluation, effectively reduce the harmful self-preference. These results provide a more nuanced understanding of LLM-based evaluation and practical insights for improving its reliability.
InstructRAG: Instructing Retrieval-Augmented Generation with Explicit Denoising
Jun 19, 2024Retrieval-augmented generation (RAG) has shown promising potential to enhance the accuracy and factuality of language models (LMs). However, imperfect retrievers or noisy corpora can introduce misleading or even erroneous information to the retrieved contents, posing a significant challenge to the generation quality. Existing RAG methods typically address this challenge by directly predicting final answers despite potentially noisy inputs, resulting in an implicit denoising process that is difficult to interpret and verify. On the other hand, the acquisition of explicit denoising supervision is often costly, involving significant human efforts. In this work, we propose InstructRAG, where LMs explicitly learn the denoising process through self-synthesized rationales -- First, we instruct the LM to explain how the ground-truth answer is derived from retrieved documents. Then, these rationales can be used either as demonstrations for in-context learning of explicit denoising or as supervised fine-tuning data to train the model. Compared to standard RAG approaches, InstructRAG requires no additional supervision, allows for easier verification of the predicted answers, and effectively improves generation accuracy. Experiments show InstructRAG consistently outperforms existing RAG methods in both training-free and trainable scenarios, achieving a relative improvement of 8.3% over the best baseline method on average across five knowledge-intensive benchmarks. Extensive analysis indicates that InstructRAG scales well with increased numbers of retrieved documents and consistently exhibits robust denoising ability even in out-of-domain datasets, demonstrating strong generalizability.
Incentivized Truthful Communication for Federated Bandits
Feb 07, 2024To enhance the efficiency and practicality of federated bandit learning, recent advances have introduced incentives to motivate communication among clients, where a client participates only when the incentive offered by the server outweighs its participation cost. However, existing incentive mechanisms naively assume the clients are truthful: they all report their true cost and thus the higher cost one participating client claims, the more the server has to pay. Therefore, such mechanisms are vulnerable to strategic clients aiming to optimize their own utility by misreporting. To address this issue, we propose an incentive compatible (i.e., truthful) communication protocol, named Truth-FedBan, where the incentive for each participant is independent of its self-reported cost, and reporting the true cost is the only way to achieve the best utility. More importantly, Truth-FedBan still guarantees the sub-linear regret and communication cost without any overheads. In other words, the core conceptual contribution of this paper is, for the first time, demonstrating the possibility of simultaneously achieving incentive compatibility and nearly optimal regret in federated bandit learning. Extensive numerical studies further validate the effectiveness of our proposed solution.
Incentivized Communication for Federated Bandits
Sep 21, 2023Most existing works on federated bandits take it for granted that all clients are altruistic about sharing their data with the server for the collective good whenever needed. Despite their compelling theoretical guarantee on performance and communication efficiency, this assumption is overly idealistic and oftentimes violated in practice, especially when the algorithm is operated over self-interested clients, who are reluctant to share data without explicit benefits. Negligence of such self-interested behaviors can significantly affect the learning efficiency and even the practical operability of federated bandit learning. In light of this, we aim to spark new insights into this under-explored research area by formally introducing an incentivized communication problem for federated bandits, where the server shall motivate clients to share data by providing incentives. Without loss of generality, we instantiate this bandit problem with the contextual linear setting and propose the first incentivized communication protocol, namely, Inc-FedUCB, that achieves near-optimal regret with provable communication and incentive cost guarantees. Extensive empirical experiments on both synthetic and real-world datasets further validate the effectiveness of the proposed method across various environments.
Learning Semantic Textual Similarity via Topic-informed Discrete Latent Variables
Nov 07, 2022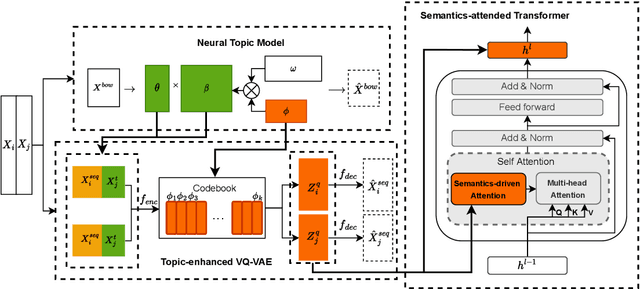
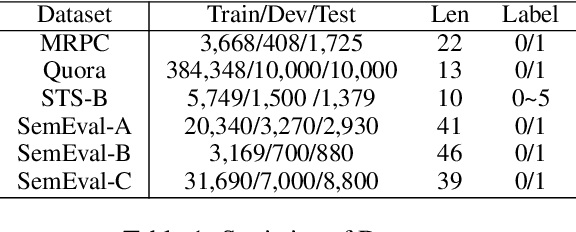
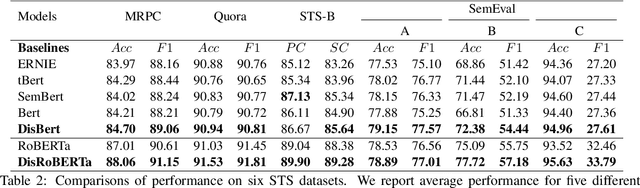
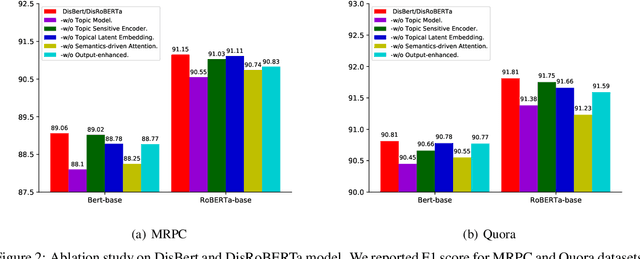
Recently, discrete latent variable models have received a surge of interest in both Natural Language Processing (NLP) and Computer Vision (CV), attributed to their comparable performance to the continuous counterparts in representation learning, while being more interpretable in their predictions. In this paper, we develop a topic-informed discrete latent variable model for semantic textual similarity, which learns a shared latent space for sentence-pair representation via vector quantization. Compared with previous models limited to local semantic contexts, our model can explore richer semantic information via topic modeling. We further boost the performance of semantic similarity by injecting the quantized representation into a transformer-based language model with a well-designed semantic-driven attention mechanism. We demonstrate, through extensive experiments across various English language datasets, that our model is able to surpass several strong neural baselines in semantic textual similarity tasks.
Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning
Nov 24, 2021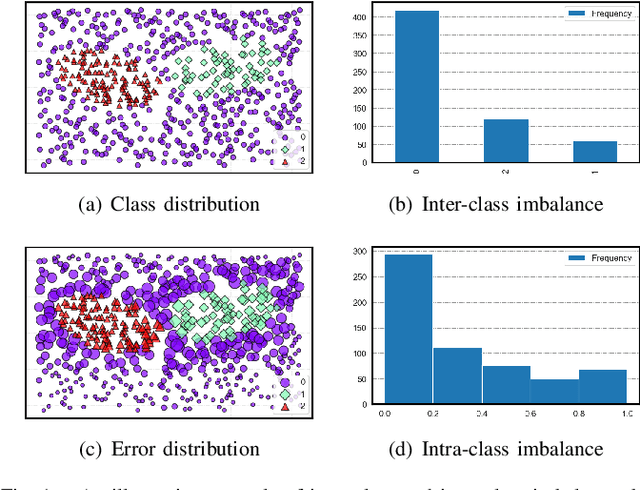
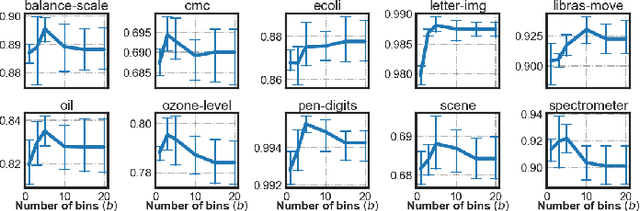
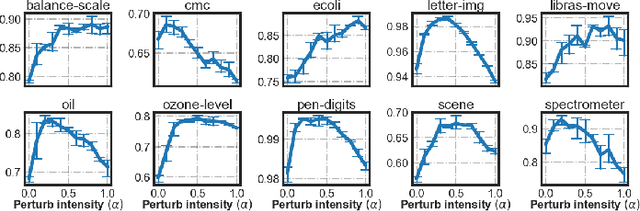
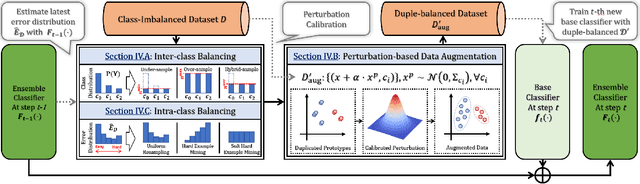
Imbalanced Learning (IL) is an important problem that widely exists in data mining applications. Typical IL methods utilize intuitive class-wise resampling or reweighting to directly balance the training set. However, some recent research efforts in specific domains show that class-imbalanced learning can be achieved without class-wise manipulation. This prompts us to think about the relationship between the two different IL strategies and the nature of the class imbalance. Fundamentally, they correspond to two essential imbalances that exist in IL: the difference in quantity between examples from different classes as well as between easy and hard examples within a single class, i.e., inter-class and intra-class imbalance. Existing works fail to explicitly take both imbalances into account and thus suffer from suboptimal performance. In light of this, we present Duple-Balanced Ensemble, namely DUBE , a versatile ensemble learning framework. Unlike prevailing methods, DUBE directly performs inter-class and intra-class balancing without relying on heavy distance-based computation, which allows it to achieve competitive performance while being computationally efficient. We also present a detailed discussion and analysis about the pros and cons of different inter/intra-class balancing strategies based on DUBE . Extensive experiments validate the effectiveness of the proposed method. Code and examples are available at https://github.com/ICDE2022Sub/duplebalance.
IMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021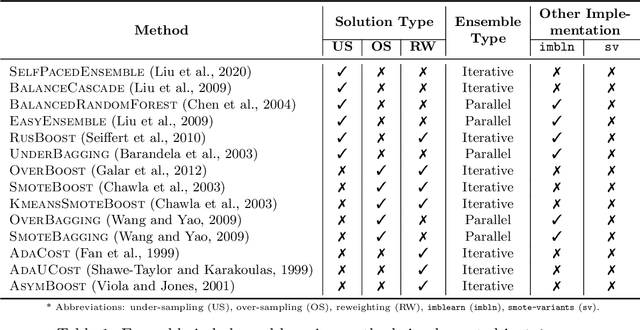
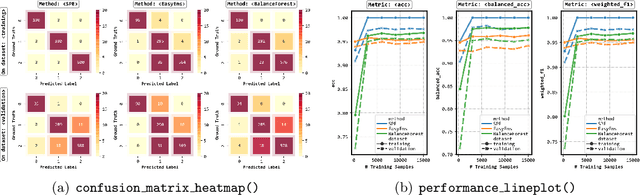
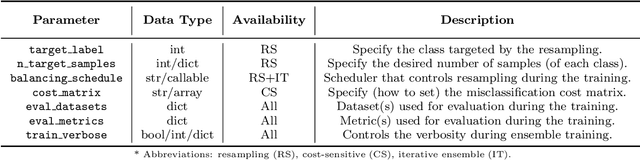
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.