 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnintended Negative Impacts of Promotional Language in Patent Evaluation
May 06, 2026Promotional language has been increasingly used to aid the communication of innovative ideas in science. Yet, less is known about its role in the context of technological innovation. Here, we use a validated and domain-diagnosed lexicon of 135 promotional words to study the association between promotional language and patent evaluation outcomes among 2.7 million USPTO patent applications. Our large-scale study reveals three unexpected findings. First, in contrast to scientific evaluation, we find that a higher frequency of promotional words is negatively associated with the probability of an application being (i) granted a patent, (ii) transferred ownership, and (iii) successfully appealed. This promotional penalty holds even after accounting for a range of confounding factors and is largely robust across different technological areas. Among matched samples, the difference in the success rate between the lowest and highest promotional density quintile is 5.5, 5.9, and 5.3 percentage points for patentability, transferability, and rejection reversal. Second, contrary to institutional skepticism, we show that promotional language is not a mask of weak technology, but objectively reflects the degree of combinatorial novelty and future citation impact. Third, digging into the mechanisms, we find that the tolerance to promotional framing is strongly moderated by human factors, with men and experienced examiners showing a higher acceptance of promotional narratives than women and novice examiners. By revealing an emerging paradox in the patent system, our study offers theoretical and practical implications for improving patent evaluation through more objective scrutiny of linguistic patterns in patent filings.
T$^2$PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
May 04, 2026Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse. We argue that this instability stems from inefficient exploration in multi-turn settings, where policies continue to generate low-information actions that neither reduce uncertainty nor advance task progress. To address this issue, we propose Token- and Turn-level Policy Optimization (T$^2$PO), an uncertainty-aware framework that explicitly controls exploration at fine-grained levels. At the token level, T$^2$PO monitors uncertainty dynamics and triggers a thinking intervention once the marginal uncertainty change falls below a threshold. At the turn level, T$^2$PO identifies interactions with negligible exploration progress and dynamically resamples such turns to avoid wasted rollouts. We evaluate T$^2$PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency. Code is available at: https://github.com/WillDreamer/T2PO.
SynPlanResearch-R1: Encouraging Tool Exploration for Deep Research with Synthetic Plans
Mar 09, 2026Research Agents enable models to gather information from the web using tools to answer user queries, requiring them to dynamically interleave internal reasoning with tool use. While such capabilities can in principle be learned via reinforcement learning with verifiable rewards (RLVR), we observe that agents often exhibit poor exploration behaviors, including premature termination and biased tool usage. As a result, RLVR alone yields limited improvements. We propose SynPlanResearch-R1, a framework that synthesizes tool-use trajectories that encourage deeper exploration to shape exploration during cold-start supervised fine-tuning, providing a strong initialization for subsequent RL. Across seven multi-hop and open-web benchmarks, \framework improves performance by up to 6.0% on Qwen3-8B and 5.8% on Qwen3-4B backbones respectively compared to SOTA baselines. Further analyses of tool-use patterns and training dynamics compared to baselines shed light on the factors underlying these gains. Our code is publicly available at https://github.com/HansiZeng/syn-plan-research.
Not All Candidates are Created Equal: A Heterogeneity-Aware Approach to Pre-ranking in Recommender Systems
Mar 04, 2026Most large-scale recommender systems follow a multi-stage cascade of retrieval, pre-ranking, ranking, and re-ranking. A key challenge at the pre-ranking stage arises from the heterogeneity of training instances sampled from coarse-grained retrieval results, fine-grained ranking signals, and exposure feedback. Our analysis reveals that prevailing pre-ranking methods, which indiscriminately mix heterogeneous samples, suffer from gradient conflicts: hard samples dominate training while easy ones remain underutilized, leading to suboptimal performance. We further show that the common practice of uniformly scaling model complexity across all samples is inefficient, as it overspends computation on easy cases and slows training without proportional gains. To address these limitations, this paper presents Heterogeneity-Aware Adaptive Pre-ranking (HAP), a unified framework that mitigates gradient conflicts through conflict-sensitive sampling coupled with tailored loss design, while adaptively allocating computational budgets across candidates. Specifically, HAP disentangles easy and hard samples, directing each subset along dedicated optimization paths. Building on this separation, it first applies lightweight models to all candidates for efficient coverage, and further engages stronger models on the hard ones, maintaining accuracy while reducing cost. This approach not only improves pre-ranking effectiveness but also provides a practical perspective on scaling strategies in industrial recommender systems. HAP has been deployed in the Toutiao production system for 9 months, yielding up to 0.4% improvement in user app usage duration and 0.05% in active days, without additional computational cost. We also release a large-scale industrial hybrid-sample dataset to enable the systematic study of source-driven candidate heterogeneity in pre-ranking.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
CryoSAMU: Enhancing 3D Cryo-EM Density Maps of Protein Structures at Intermediate Resolution with Structure-Aware Multimodal U-Nets
Mar 26, 2025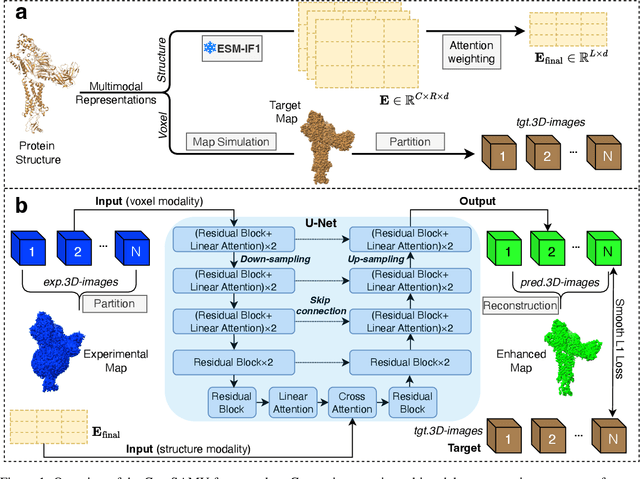


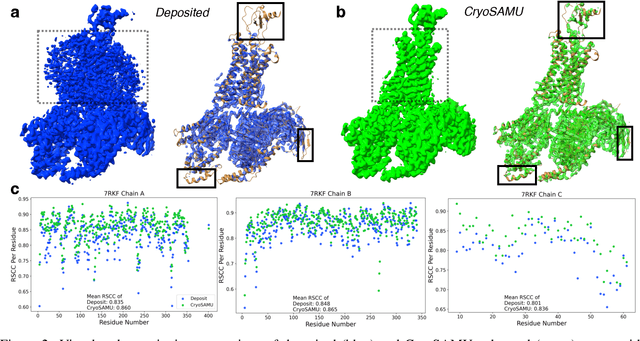
Enhancing cryogenic electron microscopy (cryo-EM) 3D density maps at intermediate resolution (4-8 {\AA}) is crucial in protein structure determination. Recent advances in deep learning have led to the development of automated approaches for enhancing experimental cryo-EM density maps. Yet, these methods are not optimized for intermediate-resolution maps and rely on map density features alone. To address this, we propose CryoSAMU, a novel method designed to enhance 3D cryo-EM density maps of protein structures using structure-aware multimodal U-Nets and trained on curated intermediate-resolution density maps. We comprehensively evaluate CryoSAMU across various metrics and demonstrate its competitive performance compared to state-of-the-art methods. Notably, CryoSAMU achieves significantly faster processing speed, showing promise for future practical applications. Our code is available at https://github.com/chenwei-zhang/CryoSAMU.
SCKD: Semi-Supervised Cross-Modality Knowledge Distillation for 4D Radar Object Detection
Dec 19, 20243D object detection is one of the fundamental perception tasks for autonomous vehicles. Fulfilling such a task with a 4D millimeter-wave radar is very attractive since the sensor is able to acquire 3D point clouds similar to Lidar while maintaining robust measurements under adverse weather. However, due to the high sparsity and noise associated with the radar point clouds, the performance of the existing methods is still much lower than expected. In this paper, we propose a novel Semi-supervised Cross-modality Knowledge Distillation (SCKD) method for 4D radar-based 3D object detection. It characterizes the capability of learning the feature from a Lidar-radar-fused teacher network with semi-supervised distillation. We first propose an adaptive fusion module in the teacher network to boost its performance. Then, two feature distillation modules are designed to facilitate the cross-modality knowledge transfer. Finally, a semi-supervised output distillation is proposed to increase the effectiveness and flexibility of the distillation framework. With the same network structure, our radar-only student trained by SCKD boosts the mAP by 10.38% over the baseline and outperforms the state-of-the-art works on the VoD dataset. The experiment on ZJUODset also shows 5.12% mAP improvements on the moderate difficulty level over the baseline when extra unlabeled data are available. Code is available at https://github.com/Ruoyu-Xu/SCKD.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Synthetic High-resolution Cryo-EM Density Maps with Generative Adversarial Networks
Jul 24, 2024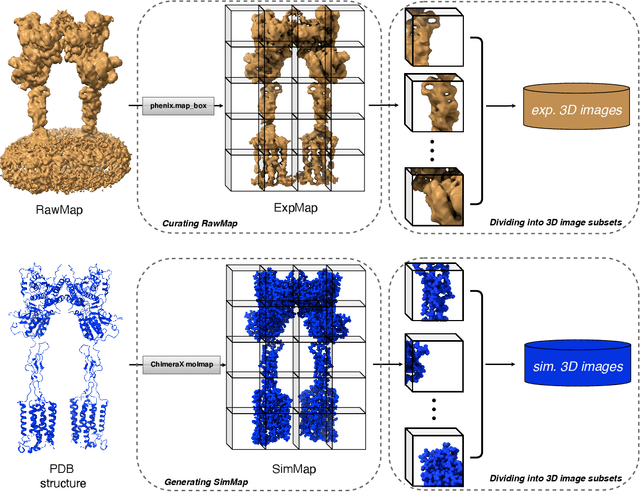

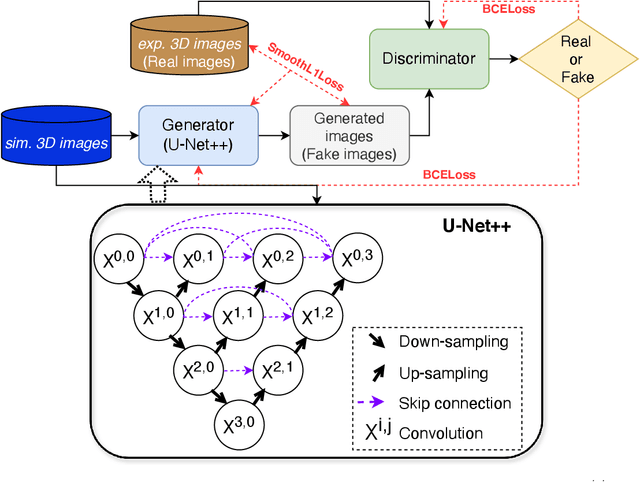
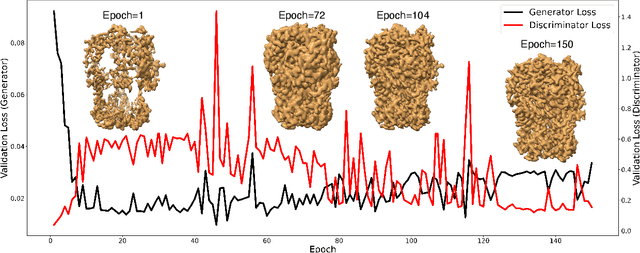
Generating synthetic cryogenic electron microscopy (cryo-EM) 3D density maps from molecular structures has potential important applications in structural biology. Yet existing simulation-based methods cannot mimic all the complex features present in experimental maps, such as secondary structure elements. As an alternative, we propose struc2mapGAN, a novel data-driven method that employs a generative adversarial network (GAN) to produce high-resolution experimental-like density maps from molecular structures. More specifically, struc2mapGAN uses a U-Net++ architecture as the generator, with an additional L1 loss term and further processing of raw experimental maps to enhance learning efficiency. While struc2mapGAN can promptly generate maps after training, we demonstrate that it outperforms existing simulation-based methods for a wide array of tested maps and across various evaluation metrics. Our code is available at https://github.com/chenwei-zhang/struc2mapGAN.