 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslate-R1: Cost-Aware Translation Tool Use via Reinforcement Learning
Jun 05, 2026The performance gap across languages in LLMs is well documented, and closing it natively requires pretraining or fine-tuning on corpora that, for most languages, do not exist. Translation offers an alternative: converting an input into the model's dominant language unlocks its full capabilities at once. Applying translation to every input, however, is wasteful for languages the model already handles, while leaving the choice to the model fails in the opposite way, as LLMs are overconfident and skip the tool even when they cannot understand the input. Prior work resolves this with language-specific rules, domain heuristics, language identifiers, or external routers, each requiring manual engineering. We instead learn a single policy that decides when to translate from reward alone, developing language- and domain-adaptive introspection that assesses its own comprehension and invokes translation only when it cannot solve a task natively. Using data built by our answer-preserving translation pipeline, we continue RL on the post-trained Qwen3-4B across 22 languages in 3 resource tiers (High, Low, XLow) and 5 domains, and introduce confidence-gated GSPO for cost-sensitive tool use. The gated policy lifts reward over the baseline by +4.6 on High, +23.5 on Low, and +17.5 on XLow. Against an unconstrained policy that almost always translates, it preserves full reward at 63% of the cost and is Pareto-optimal across 87% of the cost-sensitivity range. Additionally, to simulate behavior on a completely unseen language, we create 2 synthetic languages, where our gated policy improves +18.7 over the overconfident baseline that underutilizes the tool even on these incomprehensible inputs. The policy transfers zero-shot to 9 held-out languages, and we analyze how tool use emerges over training, per language and per domain.
Expert Upcycling: Shifting the Compute-Efficient Frontier of Mixture-of-Experts
Apr 21, 2026Mixture-of-Experts (MoE) has become the dominant architecture for scaling large language models: frontier models routinely decouple total parameters from per-token computation through sparse expert routing. Scaling laws show that under fixed active computation, model quality scales predictably with total parameters, and MoEs realize this by increasing expert count. However, training large MoEs is expensive, as memory requirements and inter-device communication both scale with total parameter count. We propose expert upcycling, a method for progressively expanding MoE capacity by increasing the number of experts during continued pre-training (CPT). Given a trained E-expert model, the upcycling operator constructs an mE-expert model through expert duplication and router extension while holding top-K routing fixed, preserving per-token inference cost. Duplication provides a warm initialization: the expanded model inherits the source checkpoint's learned representations, starting from a substantially lower loss than random initialization. Subsequent CPT then breaks the symmetry among duplicated experts to drive specialization. We formalize the upcycling operator and develop a theoretical framework decomposing the quality gap into a capacity term and an initialization term. We further introduce utility-based expert selection, which uses gradient-based importance scores to guide non-uniform duplication, more than tripling gap closure when CPT is limited. In our 7B-13B total parameter experiments, the upcycled model matches the fixed-size baseline on validation loss while saving 32% of GPU hours. Comprehensive ablations across model scales, activation ratios, MoE architectures, and training budgets yield a practical recipe for deploying expert upcycling, establishing it as a principled, compute-efficient alternative to training large MoE models from scratch.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Retraining DistilBERT for a Voice Shopping Assistant by Using Universal Dependencies
Mar 29, 2021
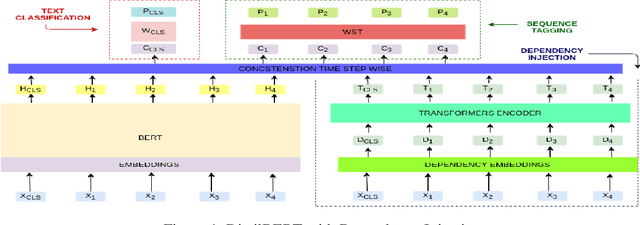

In this work, we retrained the distilled BERT language model for Walmart's voice shopping assistant on retail domain-specific data. We also injected universal syntactic dependencies to improve the performance of the model further. The Natural Language Understanding (NLU) components of the voice assistants available today are heavily dependent on language models for various tasks. The generic language models such as BERT and RoBERTa are useful for domain-independent assistants but have limitations when they cater to a specific domain. For example, in the shopping domain, the token 'horizon' means a brand instead of its literal meaning. Generic models are not able to capture such subtleties. So, in this work, we retrained a distilled version of the BERT language model on retail domain-specific data for Walmart's voice shopping assistant. We also included universal dependency-based features in the retraining process further to improve the performance of the model on downstream tasks. We evaluated the performance of the retrained language model on four downstream tasks, including intent-entity detection, sentiment analysis, voice title shortening and proactive intent suggestion. We observed an increase in the performance of all the downstream tasks of up to 1.31% on average.
Intent Detection for code-mix utterances in task oriented dialogue systems
Dec 07, 2018
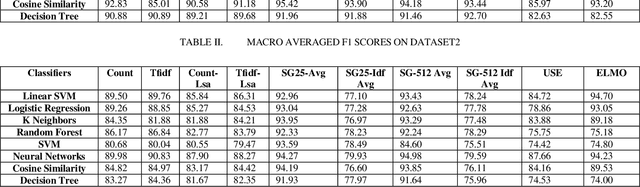
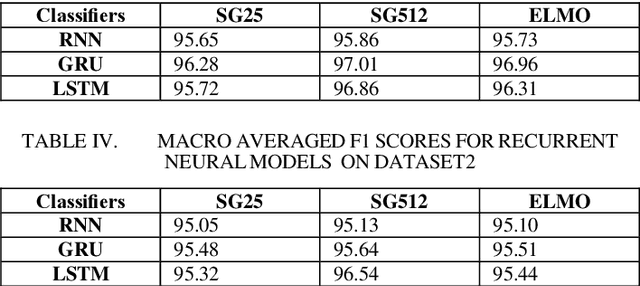
Intent detection is an essential component of task oriented dialogue systems. Over the years, extensive research has been conducted resulting in many state of the art models directed towards resolving user's intents in dialogue. A variety of vector representations foruser utterances have been explored for the same. However, these models and vectorization approaches have more so been evaluated in a single language environment. Dialogude systems generally have to deal with queries in different languages. We thus conduct experiments across combinations of models and various vectors representations for Code Mix as well as multi language utterances and evaluate how these models scale to a multi language environment. Our aim is to find the best suitable combination of vector representation and models for the process of intent detection for Code Mix utterances. we have evaluated the experiments on two different datasets consisting of only Code Mix utterances and the other dataset consisting of English, Hindi and Code Mix English Hindi utterances.
Exploring the importance of context and embeddings in neural NER models for task-oriented dialogue systems
Dec 06, 2018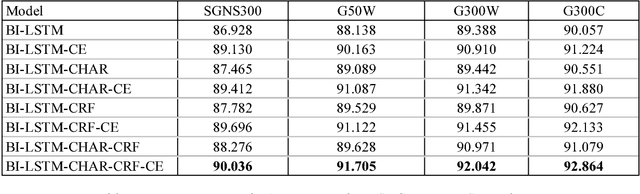
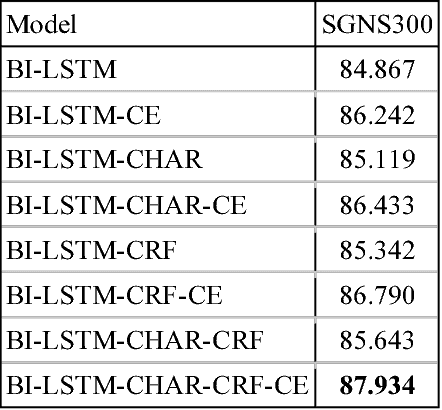
Named Entity Recognition (NER), a classic sequence labelling task, is an essential component of natural language understanding (NLU) systems in task-oriented dialog systems for slot filling. For well over a decade, different methods from lookup using gazetteers and domain ontology, classifiers over handcrafted features to end-to-end systems involving neural network architectures have been evaluated mostly in language-independent non-conversational settings. In this paper, we evaluate a modified version of the recent state of the art neural architecture in a conversational setting where messages are often short and noisy. We perform an array of experiments with different combinations of including the previous utterance in the dialogue as a source of additional features and using word and character level embeddings trained on a larger external corpus. All methods are evaluated on a combined dataset formed from two public English task-oriented conversational datasets belonging to travel and restaurant domains respectively. For additional evaluation, we also repeat some of our experiments after adding automatically translated and transliterated (from translated) versions to the English only dataset.