 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up Synthesis of Knowledge-Grounded Task-Oriented Dialogues with Iteratively Self-Refined Prompts
Apr 19, 2025Training conversational question-answering (QA) systems requires a substantial amount of in-domain data, which is often scarce in practice. A common solution to this challenge is to generate synthetic data. Traditional methods typically follow a top-down approach, where a large language model (LLM) generates multi-turn dialogues from a broad prompt. Although this method produces coherent conversations, it offers limited fine-grained control over the content and is susceptible to hallucinations. We introduce a bottom-up conversation synthesis approach, where QA pairs are generated first and then combined into a coherent dialogue. This method offers greater control and precision by dividing the process into two distinct steps, allowing refined instructions and validations to be handled separately. Additionally, this structure allows the use of non-local models in stages that do not involve proprietary knowledge, enhancing the overall quality of the generated data. Both human and automated evaluations demonstrate that our approach produces more realistic and higher-quality dialogues compared to top-down methods.
Retraining DistilBERT for a Voice Shopping Assistant by Using Universal Dependencies
Mar 29, 2021
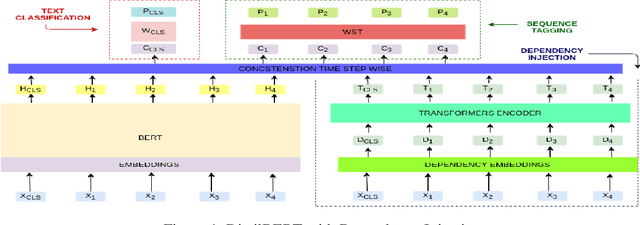

In this work, we retrained the distilled BERT language model for Walmart's voice shopping assistant on retail domain-specific data. We also injected universal syntactic dependencies to improve the performance of the model further. The Natural Language Understanding (NLU) components of the voice assistants available today are heavily dependent on language models for various tasks. The generic language models such as BERT and RoBERTa are useful for domain-independent assistants but have limitations when they cater to a specific domain. For example, in the shopping domain, the token 'horizon' means a brand instead of its literal meaning. Generic models are not able to capture such subtleties. So, in this work, we retrained a distilled version of the BERT language model on retail domain-specific data for Walmart's voice shopping assistant. We also included universal dependency-based features in the retraining process further to improve the performance of the model on downstream tasks. We evaluated the performance of the retrained language model on four downstream tasks, including intent-entity detection, sentiment analysis, voice title shortening and proactive intent suggestion. We observed an increase in the performance of all the downstream tasks of up to 1.31% on average.
Using Answer Set Programming for Commonsense Reasoning in the Winograd Schema Challenge
Jul 25, 2019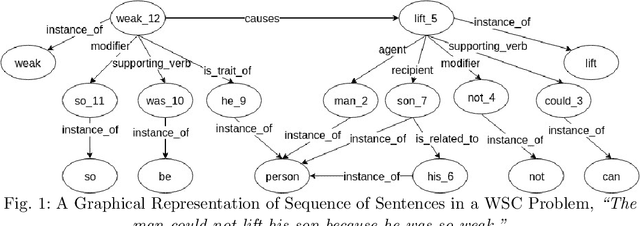
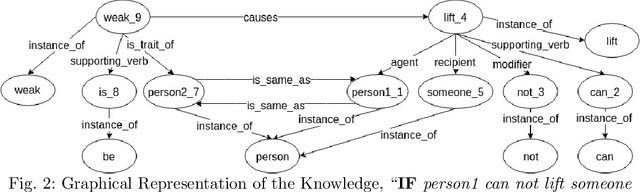
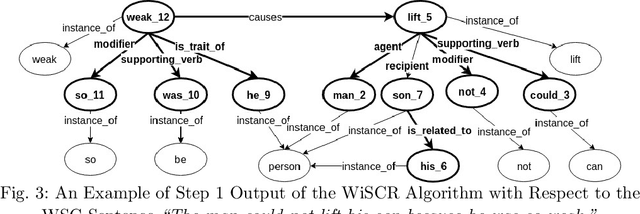
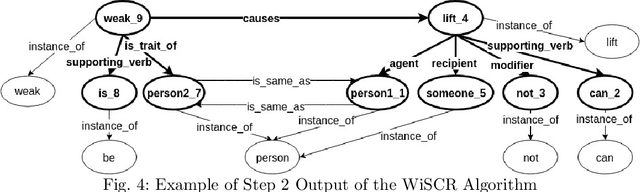
The Winograd Schema Challenge (WSC) is a natural language understanding task proposed as an alternative to the Turing test in 2011. In this work we attempt to solve WSC problems by reasoning with additional knowledge. By using an approach built on top of graph-subgraph isomorphism encoded using Answer Set Programming (ASP) we were able to handle 240 out of 291 WSC problems. The ASP encoding allows us to add additional constraints in an elaboration tolerant manner. In the process we present a graph based representation of WSC problems as well as relevant commonsense knowledge. This paper is under consideration for acceptance in TPLP.