 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAVE: A Cognitive Architecture for Legitimate Violation in Generative Agent Societies
May 19, 2026Generative agents based on large language models reproduce believable human behavior in cooperative settings, but how they should reason in situations where rule-breaking may be required, such as fire evacuation or authority-supervised emergency, remains poorly characterized. We propose PAVE (Perception, Assessment, Verdict, Emulation), a novel four-module cognitive architecture that addresses this gap end to end: (i) Perception extracts a structured context with explicit authority distance, peer behaviors, and severity-tagged situational cues; (ii) Assessment scores the context along five scalars including an explicit legitimacy judgment that checks necessity, proportionality, and absence of alternatives; (iii) Verdict decides to comply or violate under a hard legitimacy gate, with a per-agent threshold elicited from the persona; (iv) Emulation enacts the verdict and scopes the violation to the rule the trigger justifies. We instantiate PAVE in Voville, a tile-based traffic environment forked from Smallville, and evaluate across three scenarios, four LLM backbones, and a focused ablation. PAVE agents satisfy four properties simultaneously: legitimate violation (only when a trigger justifies it), authority deference (officer instructions override even high legitimacy), bounded scope (violations confined to the targeted rule), and recovery (baseline restored once the trigger ends). PAVE agents make more structured and interpretable decisions than vanilla across all four properties, and human evaluators rate them as more plausible. Ablating the legitimacy gate reproduces vanilla-like failures. We release Voville, the PAVE prompts and code, and the evaluation pipeline.
EgoTraj: Real-World Egocentric Human Trajectory Dataset for Multimodal Prediction
May 18, 2026Accurately forecasting human trajectories from an egocentric perspective plays a central role in applications such as humanoid robotics, wearable sensing systems, and assistive navigation. However, progress in this direction remains limited due to the scarcity of egocentric trajectory datasets collected in real-world environments. Addressing this need, we introduce EgoTraj, an egocentric multimodal open dataset recorded using Meta Quest Pro (MQPro). EgoTraj contains 75 sequences of human navigation collected from multiple MQPro wearers in real-world urban environments. Each recording provides synchronized RGB video along with ground-truth data, including continuous time-synchronized 6-degree-of-freedom head poses, per-frame 3D eye gaze vectors, scene annotations. To the best of our knowledge, EgoTraj differs from typical egocentric trajectory datasets by capturing long-horizon, self-directed navigation across diverse urban routes with broad participant diversity. To demonstrate the potential of the dataset, we benchmark several state-of-the-art methods for egocentric trajectory prediction and conduct ablation studies to analyze the contributions of gaze, scene, and motion cues. The results highlight the utility of EgoTraj for AR-based perception, navigation, and assistive systems. The EgoTraj dataset, code, and EgoViz Dashboard are publicly available at https://github.com/yehiahmad/EgoTraj.
3D Primitives are a Spatial Language for VLMs
May 12, 2026Vision-language models (VLMs) exhibit a striking paradox: they can generate executable code that reconstructs a 3D scene from geometric primitives with correct object counts, classes, and approximate positions, yet the same models fail at simpler spatial questions on the same image. We show that 3D geometric primitives (cubes, spheres, cylinders, expressed in executable code) serve as a powerful intermediate representation for spatial understanding, and exploit this through three contributions. First, we introduce \textbf{\textsc{SpatialBabel}}, a benchmark evaluating fourteen VLMs on primitive-based 3D scene reconstruction across six \emph{scene-code languages} (programming languages and declarative formats for 3D primitive scenes), revealing that a single model's object-detection F1 can vary by up to $5.7\times$ across languages. Second, we propose \textbf{Code-CoT} (Code Chain-of-Thought), a training-free inference strategy that routes spatial reasoning through primitive-based code generation. Code-CoT lifts the SpatialBabel-QA-Score by up to $+6.4$\% on primitive scenes and real-photo CV-Bench-3D accuracy by $+5.0$\% for VLMs with strong coding capabilities. Third, we propose \textbf{S$^{3}$-FT} (Self-Supervised Spatial Fine-Tuning), which self-supervisedly distills primitive spatial knowledge into general visual reasoning by parsing the model's own Three.js primitive-reconstructions into structured annotations and fine-tuning on the result, with \emph{no human labels and no teacher model}. Training on primitive images alone, S$^3$-FT improves Qwen3-VL-8B by $+4.6$ to $+8.6$\% on SpatialBabel-Primitive-QA, $+9.7$\% on CV-Bench-2D, and $+17$\% on HallusionBench; the recipe transfers across model families. These results establish geometric primitives in code as both a diagnostic and a transferable spatial vocabulary for VLMs. We will release all artifacts upon publication.
LLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
FrameTwin: Curve-Anchored Gaussian Alignment from Sparse Views for Adaptive Wireframe 3D Printing
May 10, 2026We present FrameTwin, a curve-anchored Gaussian alignment framework that uses sparse-view images to close the control loop for adaptive wireframe 3D printing. Our key idea is to capture the deformation of thin wireframe structures from sparse-view images using Gaussian kernels anchored to parametric curves, yielding a compact and geometry-aware encoding that explicitly captures strut topology. Driven by a differentiable rendering pipeline, FrameTwin estimates a neural deformation field that aligns the partially printed target model with the deformed structure observed during fabrication, where the optimized curve-Gaussian representation serves as a digital twin of the evolving wireframe. Unlike general Gaussian-splatting approaches, our formulation constrains kernel placement along parametric curves, substantially reducing the ambiguity inherent in sparse-view observations of thin structures. The resultant deformation-field alignment enforces global consistency across all struts. By using the estimated deformation field to blend the distorted printed geometry with the remaining unprinted geometry, FrameTwin enables adaptive updates to future printing trajectories. We demonstrate that FrameTwin can robustly capture and compensate for deformation in wireframe models fabricated using a robotized 3D printing system.
DUSG-Tomo-Net: A Deep Unfolded Neural Network for Super-Resolving Gridless Spaceborne SAR Tomography via Learned Toeplitz-Structured Covariance Representation
Apr 21, 2026Synthetic aperture radar tomography (TomoSAR) enables 3-D imaging by exploiting multibaseline acquisitions and has become an important tool for urban mapping. To achieve super-resolution inversion, sparse reconstruction methods based on compressive sensing (CS) are widely adopted. However, most CS-based TomoSAR methods rely on grid-based formulations and therefore suffer from off-grid bias. Gridless formulations provide a principled way to alleviate this limitation, whereas classical Toeplitz-Vandermonde atomic norm minimization (ANM) is not directly applicable to spaceborne TomoSAR under nonuniform baselines. Existing gridless methods for nonuniform-baseline TomoSAR avoid the classical uniform linear array (ULA) assumption, but they are usually tightly coupled to handcrafted iterative solvers and solver-specific parameter settings, while robust inversion under limited observations and low-SNR conditions remains challenging. To address this gap, we propose DUSG-Tomo-Net, a deep unfolded gridless framework for single-look spaceborne TomoSAR under nonuniform baselines. The proposed method reformulates the inversion in a Toeplitz-compatible lag domain via a structured single-look approximation and recovers a Hermitian Toeplitz positive-semidefinite structured covariance representation through layerwise learned regularization and projection-based structural enforcement. The actual acquisition geometry is embedded analytically into the data-consistency step via a fixed, signal-independent operator, enabling operator-based adaptation to varying baseline configurations. Scatterer elevations are then estimated by a continuous-domain spectral estimator without elevation discretization.
SqueezeComposer: Temporal Speed-up is A Simple Trick for Long-form Music Composing
Mar 22, 2026Composing coherent long-form music remains a significant challenge due to the complexity of modeling long-range dependencies and the prohibitive memory and computational requirements associated with lengthy audio representations. In this work, we propose a simple yet powerful trick: we assume that AI models can understand and generate time-accelerated (speeded-up) audio at rates such as 2x, 4x, or even 8x. By first generating a high-speed version of the music, we greatly reduce the temporal length and resource requirements, making it feasible to handle long-form music that would otherwise exceed memory or computational limits. The generated audio is then restored to its original speed, recovering the full temporal structure. This temporal speed-up and slow-down strategy naturally follows the principle of hierarchical generation from abstract to detailed content, and can be conveniently applied to existing music generation models to enable long-form music generation. We instantiate this idea in SqueezeComposer, a framework that employs diffusion models for generation in the accelerated domain and refinement in the restored domain. We validate the effectiveness of this approach on two tasks: long-form music generation, which evaluates temporal-wise control (including continuation, completion, and generation from scratch), and whole-song singing accompaniment generation, which evaluates track-wise control. Experimental results demonstrate that our simple temporal speed-up trick enables efficient, scalable, and high-quality long-form music generation. Audio samples are available at https://SqueezeComposer.github.io/.
EvoSchema: Towards Text-to-SQL Robustness Against Schema Evolution
Mar 11, 2026Neural text-to-SQL models, which translate natural language questions (NLQs) into SQL queries given a database schema, have achieved remarkable performance. However, database schemas frequently evolve to meet new requirements. Such schema evolution often leads to performance degradation for models trained on static schemas. Existing work either mainly focuses on simply paraphrasing some syntactic or semantic mappings among NLQ, DB and SQL, or lacks a comprehensive and controllable way to investigate the model robustness issue under the schema evolution, which is insufficient when facing the increasingly complex and rich database schema changes in reality, especially in the LLM era. To address the challenges posed by schema evolution, we present EvoSchema, a comprehensive benchmark designed to assess and enhance the robustness of text-to-SQL systems under real-world schema changes. EvoSchema introduces a novel schema evolution taxonomy, encompassing ten perturbation types across columnlevel and table-level modifications, systematically simulating the dynamic nature of database schemas. Through EvoSchema, we conduct an in-depth evaluation spanning different open source and closed-source LLMs, revealing that table-level perturbations have a significantly greater impact on model performance compared to column-level changes. Furthermore, EvoSchema inspires the development of more resilient text-to-SQL systems, in terms of both model training and database design. The models trained on EvoSchema's diverse schema designs can force the model to distinguish the schema difference for the same questions to avoid learning spurious patterns, which demonstrate remarkable robustness compared to those trained on unperturbed data on average. This benchmark offers valuable insights into model behavior and a path forward for designing systems capable of thriving in dynamic, real-world environments.
Human-AI Co-reasoning for Clinical Diagnosis with Evidence-Integrated Language Agent
Mar 11, 2026We present PULSE, a medical reasoning agent that combines a domain-tuned large language model with scientific literature retrieval to support diagnostic decision-making in complex real-world cases. To evaluate its capabilities, we curated a benchmark of 82 authentic endocrinology case reports encompassing a broad spectrum of disease types and incidence levels. In controlled experiments, we compared PULSE's performance against physicians with varying levels of expertise-from residents to senior specialists-and examined how AI assistance influenced human diagnostic reasoning. PULSE attained expert-competitive accuracy, outperforming residents and junior specialists while matching senior specialist performance at both Top@1 and Top@4 thresholds. Unlike physicians, whose accuracy declined with disease rarity, PULSE maintained stable performance across incidence tiers. The agent also exhibited adaptive reasoning, increasing output length with case difficulty in a manner analogous to the longer deliberation observed among expert clinicians. When used collaboratively, PULSE enabled physicians to correct initial errors and broaden diagnostic hypotheses, but also introduced risks of automation bias. The study explores both serial and concurrent collaboration workflows, revealing that PULSE offers robust support across common and rare presentations. These findings underscore both the promise and the limitations of language model-based agents in clinical diagnosis, and offer a framework for evaluating their role in real-world decision-making.
Adaptation of Agentic AI
Dec 22, 2025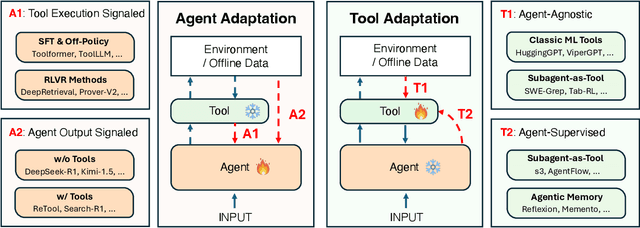
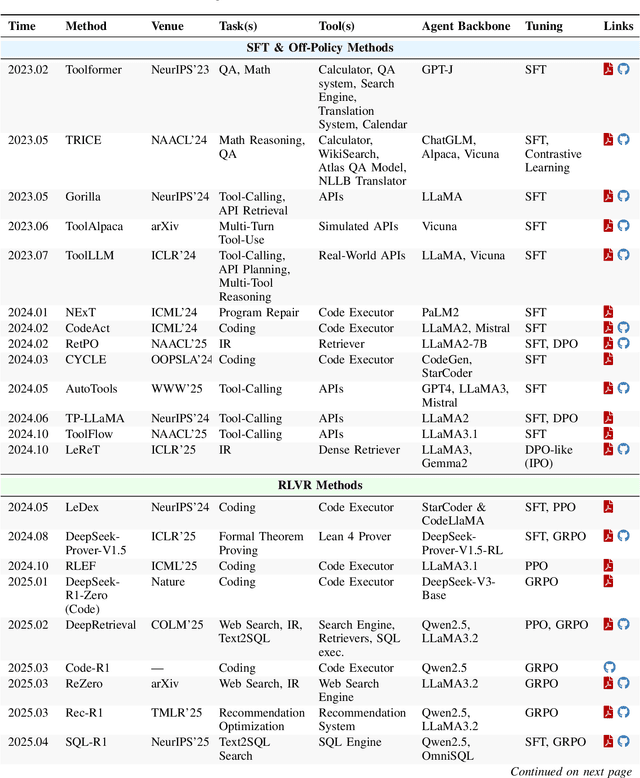
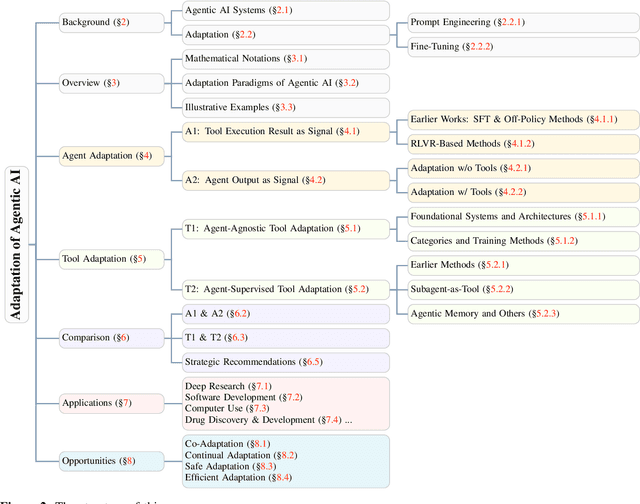
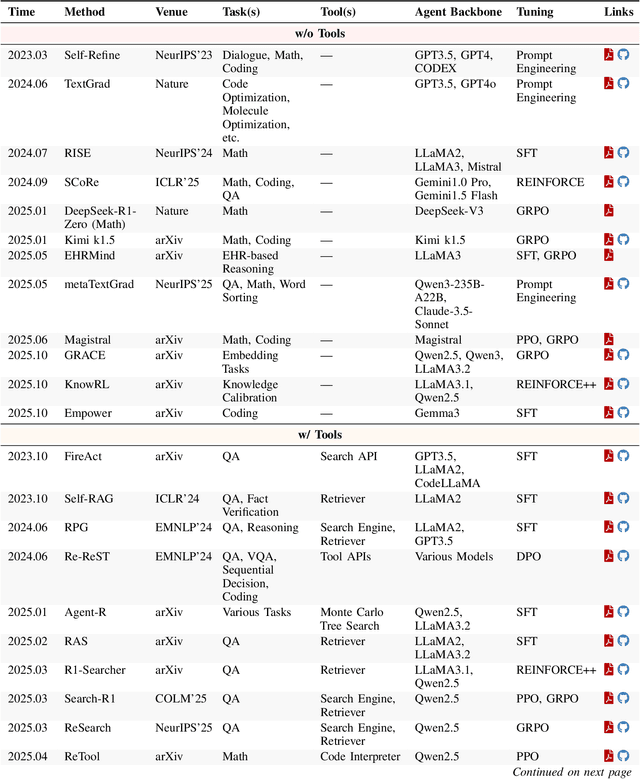
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.