 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Index of Noah's Ark
Jun 04, 2026Knowledge benchmarks for LLMs face three issues: scaling-driven designs that do not operationalize disciplinary representativeness; flat-payment annotation that permits lazy consensus; and unaudited ranking instability under bounded test budgets. We introduce KINA, an 899-item benchmark across 261 fine-grained disciplines, with two formal results. First, we cast representativeness as a coverage-style objective over expert-elicited anchors and operationalize disciplinary representativeness through a proxy, yielding a (1-1/e) greedy approximation (Proposition 1); the guarantee applies to the proxy, not to population representativeness. Second, we prove a bonus-on-bar tournament weakly FOSD-dominates flat payment in released-review quality, with incentive-compatibility threshold B > Delta C / Delta p_min (Theorem 1). Evaluating 42 models from 13 labs, the top model, Gemini-3.1-Pro-Preview, reaches 53.17%, followed by Claude-Opus-4.6 at 49.92% and GPT-5.4 at 48.55%, leaving substantial headroom below saturation. The full leaderboard shows a tiered structure rather than a smooth total order: a small frontier tier lies above 48%, a dense strong-model tier spans roughly 38-45%, and low-performing models remain only modestly above the 10% chance baseline. Tool augmentation adds up to 5.17 points across the five tool-use evaluations, with gains varying substantially across models. We report bootstrap ranking-stability statistics to make bounded-budget variance explicit and to discourage over-interpretation of adjacent ranks.
MAD-UV: The 1st INTERSPEECH Mice Autism Detection via Ultrasound Vocalization Challenge
Jan 08, 2025


The Mice Autism Detection via Ultrasound Vocalization (MAD-UV) Challenge introduces the first INTERSPEECH challenge focused on detecting autism spectrum disorder (ASD) in mice through their vocalizations. Participants are tasked with developing models to automatically classify mice as either wild-type or ASD models based on recordings with a high sampling rate. Our baseline system employs a simple CNN-based classification using three different spectrogram features. Results demonstrate the feasibility of automated ASD detection, with the considered audible-range features achieving the best performance (UAR of 0.600 for segment-level and 0.625 for subject-level classification). This challenge bridges speech technology and biomedical research, offering opportunities to advance our understanding of ASD models through machine learning approaches. The findings suggest promising directions for vocalization analysis and highlight the potential value of audible and ultrasound vocalizations in ASD detection.
Self-Supervised Attention Networks and Uncertainty Loss Weighting for Multi-Task Emotion Recognition on Vocal Bursts
Sep 27, 2022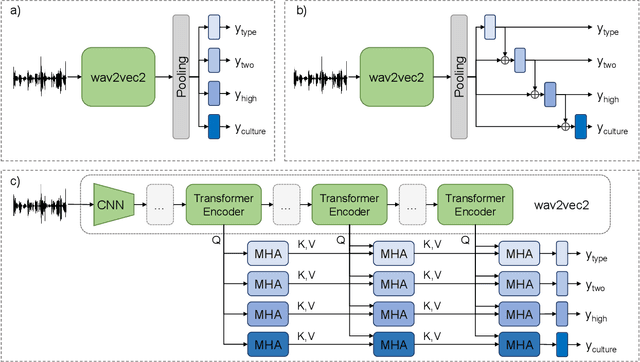
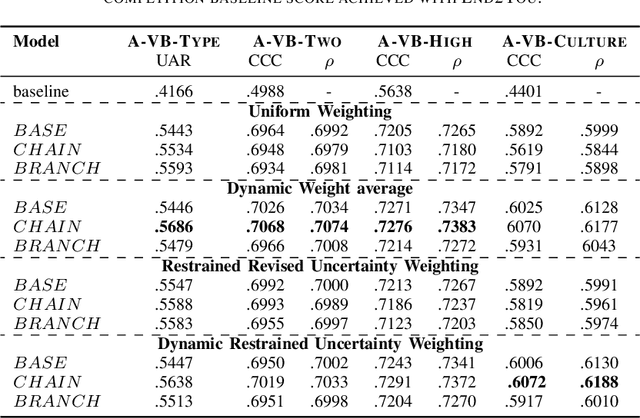

Vocal bursts play an important role in communicating affect, making them valuable for improving speech emotion recognition. Here, we present our approach for classifying vocal bursts and predicting their emotional significance in the ACII Affective Vocal Burst Workshop & Challenge 2022 (A-VB). We use a large self-supervised audio model as shared feature extractor and compare multiple architectures built on classifier chains and attention networks, combined with uncertainty loss weighting strategies. Our approach surpasses the challenge baseline by a wide margin on all four tasks.
Redundancy Reduction Twins Network: A Training framework for Multi-output Emotion Regression
Jun 28, 2022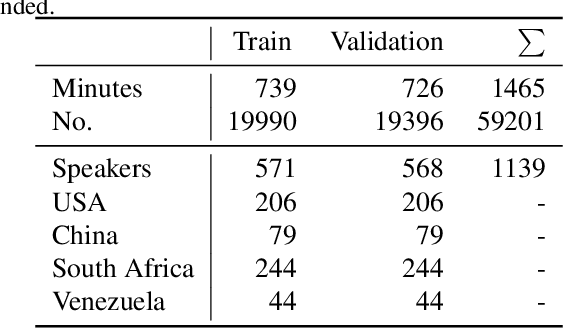
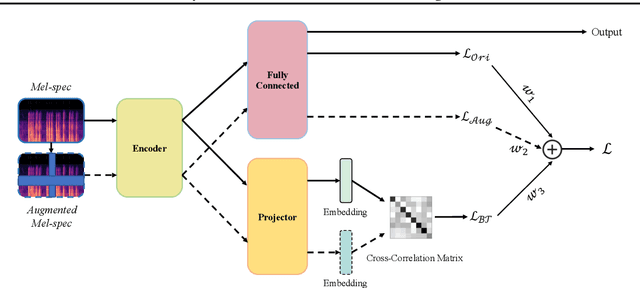
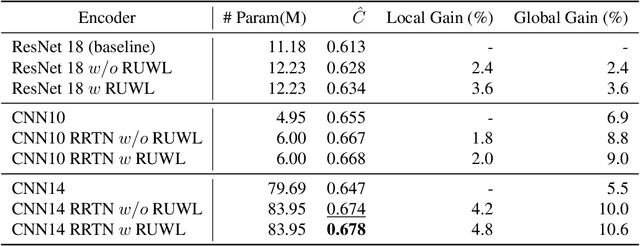
In this paper, we propose the Redundancy Reduction Twins Network (RRTN), a redundancy reduction training framework that minimizes redundancy by measuring the cross-correlation matrix between the outputs of the same network fed with distorted versions of a sample and bringing it as close to the identity matrix as possible. RRTN also applies a new loss function, the Barlow Twins loss function, to help maximize the similarity of representations obtained from different distorted versions of a sample. However, as the distribution of losses can cause performance fluctuations in the network, we also propose the use of a Restrained Uncertainty Weight Loss (RUWL) or joint training to identify the best weights for the loss function. Our best approach on CNN14 with the proposed methodology obtains a CCC over emotion regression of 0.678 on the ExVo Multi-task dev set, a 4.8% increase over a vanilla CNN 14 CCC of 0.647, which achieves a significant difference at the 95% confidence interval (2-tailed).
Dynamic Restrained Uncertainty Weighting Loss for Multitask Learning of Vocal Expression
Jun 27, 2022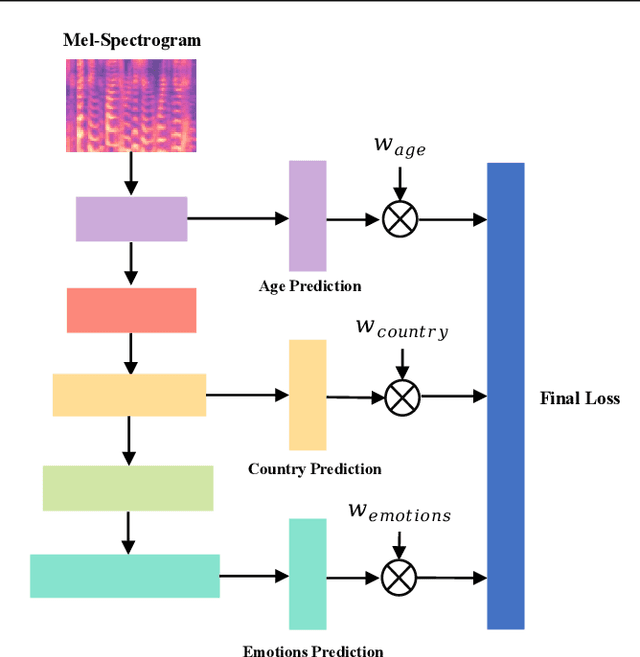
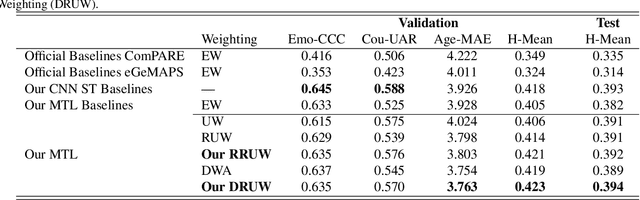
We propose a novel Dynamic Restrained Uncertainty Weighting Loss to experimentally handle the problem of balancing the contributions of multiple tasks on the ICML ExVo 2022 Challenge. The multitask aims to recognize expressed emotions and demographic traits from vocal bursts jointly. Our strategy combines the advantages of Uncertainty Weight and Dynamic Weight Average, by extending weights with a restraint term to make the learning process more explainable. We use a lightweight multi-exit CNN architecture to implement our proposed loss approach. The experimental H-Mean score (0.394) shows a substantial improvement over the baseline H-Mean score (0.335).
COVYT: Introducing the Coronavirus YouTube and TikTok speech dataset featuring the same speakers with and without infection
Jun 20, 2022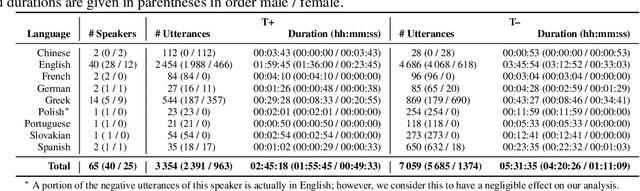
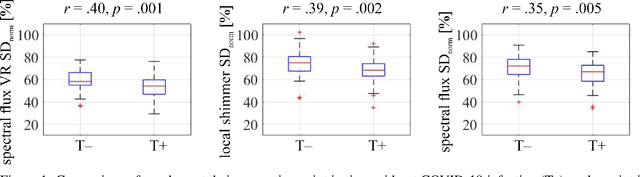
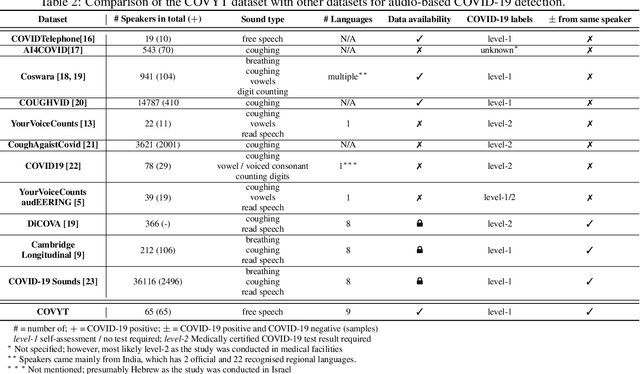
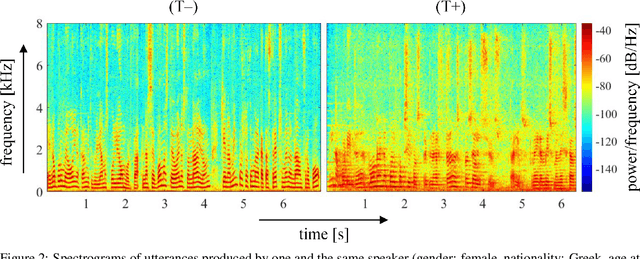
More than two years after its outbreak, the COVID-19 pandemic continues to plague medical systems around the world, putting a strain on scarce resources, and claiming human lives. From the very beginning, various AI-based COVID-19 detection and monitoring tools have been pursued in an attempt to stem the tide of infections through timely diagnosis. In particular, computer audition has been suggested as a non-invasive, cost-efficient, and eco-friendly alternative for detecting COVID-19 infections through vocal sounds. However, like all AI methods, also computer audition is heavily dependent on the quantity and quality of available data, and large-scale COVID-19 sound datasets are difficult to acquire -- amongst other reasons -- due to the sensitive nature of such data. To that end, we introduce the COVYT dataset -- a novel COVID-19 dataset collected from public sources containing more than 8 hours of speech from 65 speakers. As compared to other existing COVID-19 sound datasets, the unique feature of the COVYT dataset is that it comprises both COVID-19 positive and negative samples from all 65 speakers. We analyse the acoustic manifestation of COVID-19 on the basis of these perfectly speaker characteristic balanced `in-the-wild' data using interpretable audio descriptors, and investigate several classification scenarios that shed light into proper partitioning strategies for a fair speech-based COVID-19 detection.
Exploring speaker enrolment for few-shot personalisation in emotional vocalisation prediction
Jun 20, 2022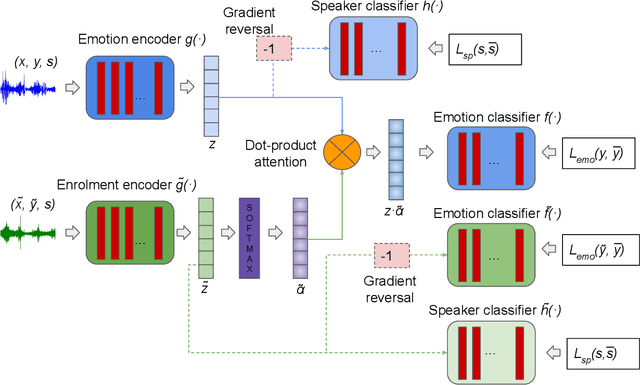
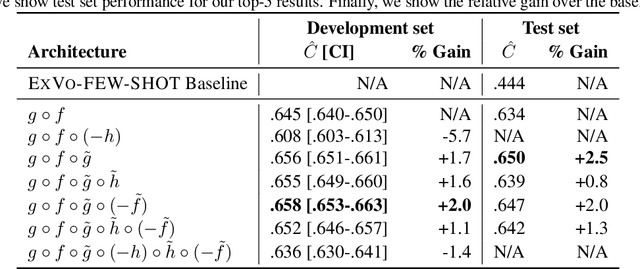
In this work, we explore a novel few-shot personalisation architecture for emotional vocalisation prediction. The core contribution is an `enrolment' encoder which utilises two unlabelled samples of the target speaker to adjust the output of the emotion encoder; the adjustment is based on dot-product attention, thus effectively functioning as a form of `soft' feature selection. The emotion and enrolment encoders are based on two standard audio architectures: CNN14 and CNN10. The two encoders are further guided to forget or learn auxiliary emotion and/or speaker information. Our best approach achieves a CCC of $.650$ on the ExVo Few-Shot dev set, a $2.5\%$ increase over our baseline CNN14 CCC of $.634$.
A Temporal-oriented Broadcast ResNet for COVID-19 Detection
Mar 31, 2022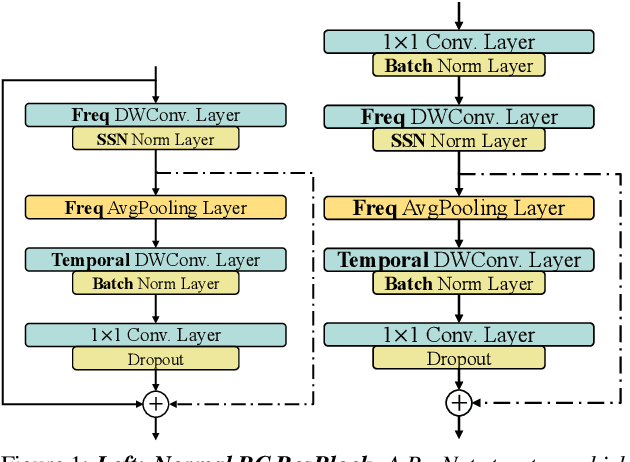


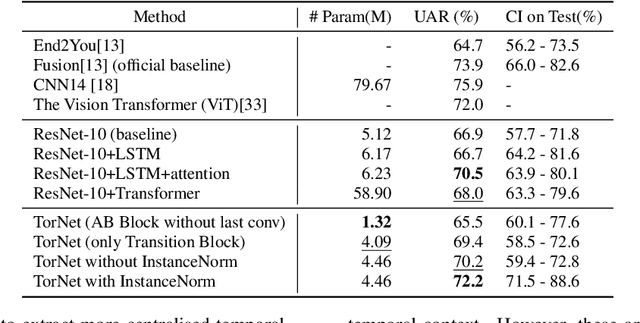
Detecting COVID-19 from audio signals, such as breathing and coughing, can be used as a fast and efficient pre-testing method to reduce the virus transmission. Due to the promising results of deep learning networks in modelling time sequences, and since applications to rapidly identify COVID in-the-wild should require low computational effort, we present a temporal-oriented broadcasting residual learning method that achieves efficient computation and high accuracy with a small model size. Based on the EfficientNet architecture, our novel network, named Temporal-oriented ResNet~(TorNet), constitutes of a broadcasting learning block, i.e. the Alternating Broadcast (AB) Block, which contains several Broadcast Residual Blocks (BC ResBlocks) and a convolution layer. With the AB Block, the network obtains useful audio-temporal features and higher level embeddings effectively with much less computation than Recurrent Neural Networks~(RNNs), typically used to model temporal information. TorNet achieves 72.2% Unweighted Average Recall (UAR) on the INTERPSEECH 2021 Computational Paralinguistics Challenge COVID-19 cough Sub-Challenge, by this showing competitive results with a higher computational efficiency than other state-of-the-art alternatives.
An Overview & Analysis of Sequence-to-Sequence Emotional Voice Conversion
Mar 29, 2022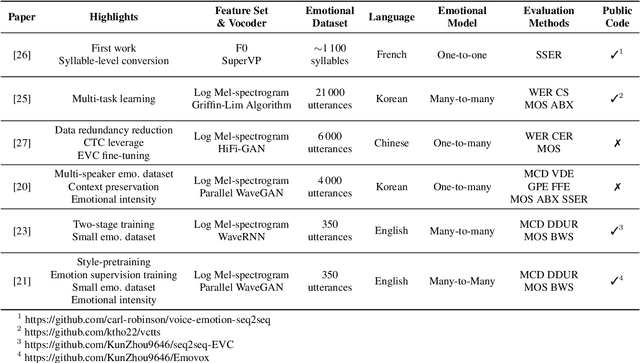
Emotional voice conversion (EVC) focuses on converting a speech utterance from a source to a target emotion; it can thus be a key enabling technology for human-computer interaction applications and beyond. However, EVC remains an unsolved research problem with several challenges. In particular, as speech rate and rhythm are two key factors of emotional conversion, models have to generate output sequences of differing length. Sequence-to-sequence modelling is recently emerging as a competitive paradigm for models that can overcome those challenges. In an attempt to stimulate further research in this promising new direction, recent sequence-to-sequence EVC papers were systematically investigated and reviewed from six perspectives: their motivation, training strategies, model architectures, datasets, model inputs, and evaluation methods. This information is organised to provide the research community with an easily digestible overview of the current state-of-the-art. Finally, we discuss existing challenges of sequence-to-sequence EVC.
An Early Study on Intelligent Analysis of Speech under COVID-19: Severity, Sleep Quality, Fatigue, and Anxiety
May 14, 2020
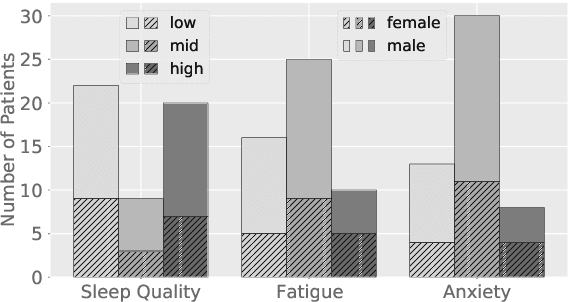

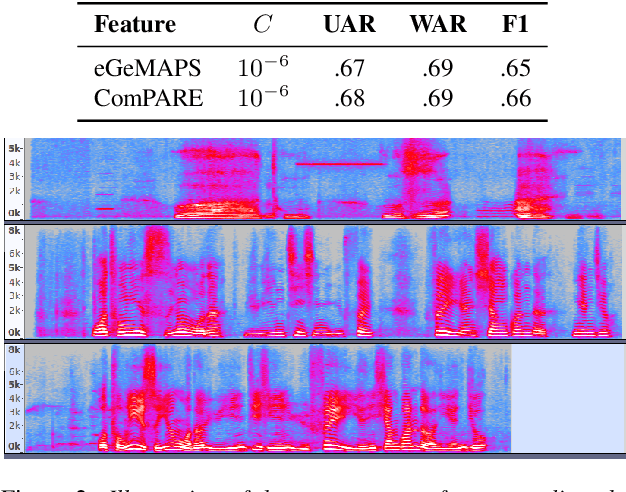
The COVID-19 outbreak was announced as a global pandemic by the World Health Organisation in March 2020 and has affected a growing number of people in the past few weeks. In this context, advanced artificial intelligence techniques are brought to the fore in responding to fight against and reduce the impact of this global health crisis. In this study, we focus on developing some potential use-cases of intelligent speech analysis for COVID-19 diagnosed patients. In particular, by analysing speech recordings from these patients, we construct audio-only-based models to automatically categorise the health state of patients from four aspects, including the severity of illness, sleep quality, fatigue, and anxiety. For this purpose, two established acoustic feature sets and support vector machines are utilised. Our experiments show that an average accuracy of .69 obtained estimating the severity of illness, which is derived from the number of days in hospitalisation. We hope that this study can foster an extremely fast, low-cost, and convenient way to automatically detect the COVID-19 disease.