Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring speaker enrolment for few-shot personalisation in emotional vocalisation prediction
Paper and Code
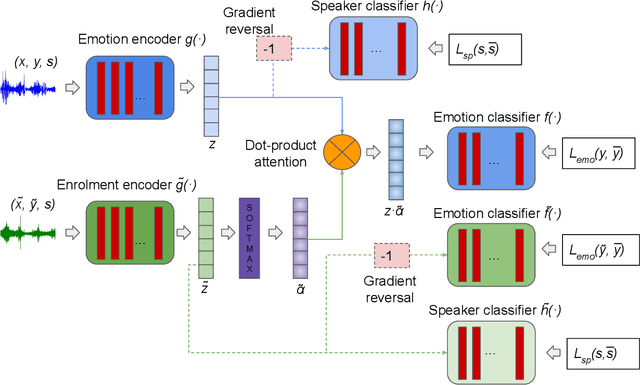
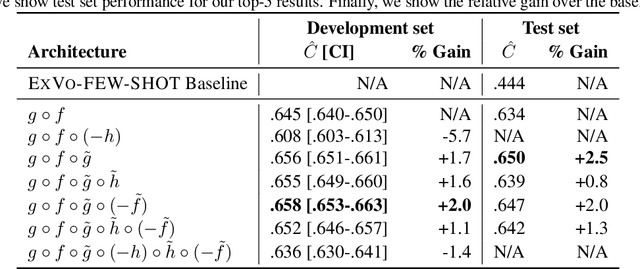
In this work, we explore a novel few-shot personalisation architecture for emotional vocalisation prediction. The core contribution is an `enrolment' encoder which utilises two unlabelled samples of the target speaker to adjust the output of the emotion encoder; the adjustment is based on dot-product attention, thus effectively functioning as a form of `soft' feature selection. The emotion and enrolment encoders are based on two standard audio architectures: CNN14 and CNN10. The two encoders are further guided to forget or learn auxiliary emotion and/or speaker information. Our best approach achieves a CCC of $.650$ on the ExVo Few-Shot dev set, a $2.5\%$ increase over our baseline CNN14 CCC of $.634$.
* Proceedings of the ICML Expressive Vocalizations Workshop and
Competition held in conjunction with the $\mathit{39}^{th}$ International
Conference on Machine Learning, Copyright 2022 by the author(s)
View paper on