 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothCLAP: Soft-Target Enhanced Contrastive Language\--Audio Pretraining for Affective Computing
Jan 18, 2026The ambiguity of human emotions poses several challenges for machine learning models, as they often overlap and lack clear delineating boundaries. Contrastive language-audio pretraining (CLAP) has emerged as a key technique for generalisable emotion recognition. However, as conventional CLAP enforces a strict one-to-one alignment between paired audio-text samples, it overlooks intra-modal similarity and treats all non-matching pairs as equally negative. This conflicts with the fuzzy boundaries between different emotions. To address this limitation, we propose SmoothCLAP, which introduces softened targets derived from intra-modal similarity and paralinguistic features. By combining these softened targets with conventional contrastive supervision, SmoothCLAP learns embeddings that respect graded emotional relationships, while retaining the same inference pipeline as CLAP. Experiments on eight affective computing tasks across English and German demonstrate that SmoothCLAP is consistently achieving superior performance. Our results highlight that leveraging soft supervision is a promising strategy for building emotion-aware audio-text models.
Reading Smiles: Proxy Bias in Foundation Models for Facial Emotion Recognition
Jun 23, 2025Foundation Models (FMs) are rapidly transforming Affective Computing (AC), with Vision Language Models (VLMs) now capable of recognising emotions in zero shot settings. This paper probes a critical but underexplored question: what visual cues do these models rely on to infer affect, and are these cues psychologically grounded or superficially learnt? We benchmark varying scale VLMs on a teeth annotated subset of AffectNet dataset and find consistent performance shifts depending on the presence of visible teeth. Through structured introspection of, the best-performing model, i.e., GPT-4o, we show that facial attributes like eyebrow position drive much of its affective reasoning, revealing a high degree of internal consistency in its valence-arousal predictions. These patterns highlight the emergent nature of FMs behaviour, but also reveal risks: shortcut learning, bias, and fairness issues especially in sensitive domains like mental health and education.
MELT: Towards Automated Multimodal Emotion Data Annotation by Leveraging LLM Embedded Knowledge
May 30, 2025Although speech emotion recognition (SER) has advanced significantly with deep learning, annotation remains a major hurdle. Human annotation is not only costly but also subject to inconsistencies annotators often have different preferences and may lack the necessary contextual knowledge, which can lead to varied and inaccurate labels. Meanwhile, Large Language Models (LLMs) have emerged as a scalable alternative for annotating text data. However, the potential of LLMs to perform emotional speech data annotation without human supervision has yet to be thoroughly investigated. To address these problems, we apply GPT-4o to annotate a multimodal dataset collected from the sitcom Friends, using only textual cues as inputs. By crafting structured text prompts, our methodology capitalizes on the knowledge GPT-4o has accumulated during its training, showcasing that it can generate accurate and contextually relevant annotations without direct access to multimodal inputs. Therefore, we propose MELT, a multimodal emotion dataset fully annotated by GPT-4o. We demonstrate the effectiveness of MELT by fine-tuning four self-supervised learning (SSL) backbones and assessing speech emotion recognition performance across emotion datasets. Additionally, our subjective experiments\' results demonstrate a consistence performance improvement on SER.
ECOSoundSet: a finely annotated dataset for the automated acoustic identification of Orthoptera and Cicadidae in North, Central and temperate Western Europe
Apr 29, 2025Currently available tools for the automated acoustic recognition of European insects in natural soundscapes are limited in scope. Large and ecologically heterogeneous acoustic datasets are currently needed for these algorithms to cross-contextually recognize the subtle and complex acoustic signatures produced by each species, thus making the availability of such datasets a key requisite for their development. Here we present ECOSoundSet (European Cicadidae and Orthoptera Sound dataSet), a dataset containing 10,653 recordings of 200 orthopteran and 24 cicada species (217 and 26 respective taxa when including subspecies) present in North, Central, and temperate Western Europe (Andorra, Belgium, Denmark, mainland France and Corsica, Germany, Ireland, Luxembourg, Monaco, Netherlands, United Kingdom, Switzerland), collected partly through targeted fieldwork in South France and Catalonia and partly through contributions from various European entomologists. The dataset is composed of a combination of coarsely labeled recordings, for which we can only infer the presence, at some point, of their target species (weak labeling), and finely annotated recordings, for which we know the specific time and frequency range of each insect sound present in the recording (strong labeling). We also provide a train/validation/test split of the strongly labeled recordings, with respective approximate proportions of 0.8, 0.1 and 0.1, in order to facilitate their incorporation in the training and evaluation of deep learning algorithms. This dataset could serve as a meaningful complement to recordings already available online for the training of deep learning algorithms for the acoustic classification of orthopterans and cicadas in North, Central, and temperate Western Europe.
DFingerNet: Noise-Adaptive Speech Enhancement for Hearing Aids
Jan 17, 2025The \textbf{DeepFilterNet} (\textbf{DFN}) architecture was recently proposed as a deep learning model suited for hearing aid devices. Despite its competitive performance on numerous benchmarks, it still follows a `one-size-fits-all' approach, which aims to train a single, monolithic architecture that generalises across different noises and environments. However, its limited size and computation budget can hamper its generalisability. Recent work has shown that in-context adaptation can improve performance by conditioning the denoising process on additional information extracted from background recordings to mitigate this. These recordings can be offloaded outside the hearing aid, thus improving performance while adding minimal computational overhead. We introduce these principles to the \textbf{DFN} model, thus proposing the \textbf{DFingerNet} (\textbf{DFiN}) model, which shows superior performance on various benchmarks inspired by the DNS Challenge.
autrainer: A Modular and Extensible Deep Learning Toolkit for Computer Audition Tasks
Dec 16, 2024This work introduces the key operating principles for autrainer, our new deep learning training framework for computer audition tasks. autrainer is a PyTorch-based toolkit that allows for rapid, reproducible, and easily extensible training on a variety of different computer audition tasks. Concretely, autrainer offers low-code training and supports a wide range of neural networks as well as preprocessing routines. In this work, we present an overview of its inner workings and key capabilities.
Does the Definition of Difficulty Matter? Scoring Functions and their Role for Curriculum Learning
Nov 01, 2024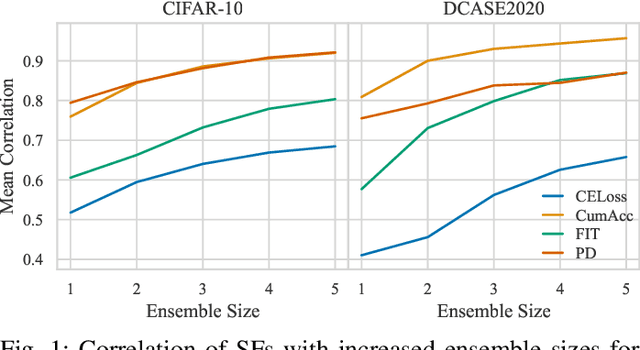
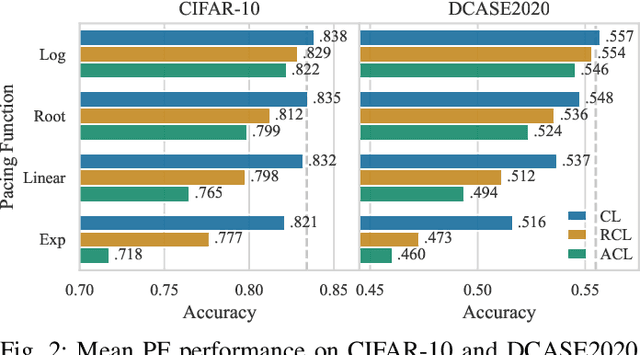
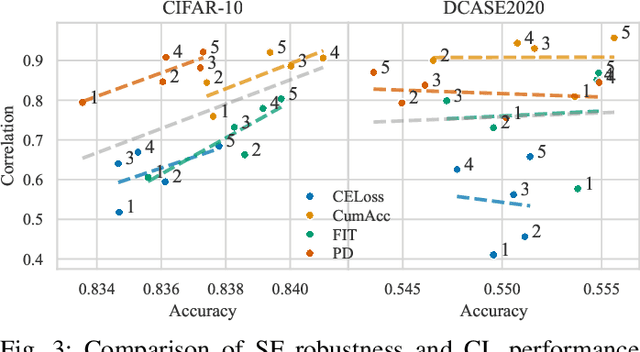
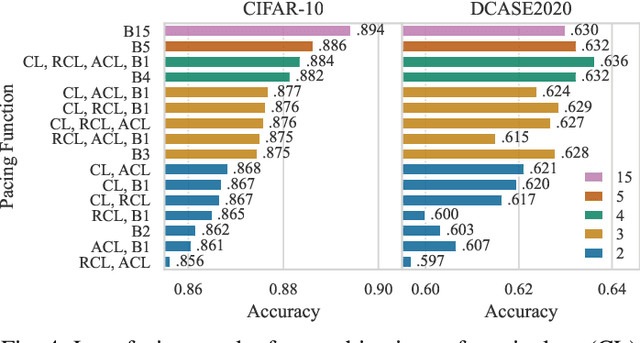
Curriculum learning (CL) describes a machine learning training strategy in which samples are gradually introduced into the training process based on their difficulty. Despite a partially contradictory body of evidence in the literature, CL finds popularity in deep learning research due to its promise of leveraging human-inspired curricula to achieve higher model performance. Yet, the subjectivity and biases that follow any necessary definition of difficulty, especially for those found in orderings derived from models or training statistics, have rarely been investigated. To shed more light on the underlying unanswered questions, we conduct an extensive study on the robustness and similarity of the most common scoring functions for sample difficulty estimation, as well as their potential benefits in CL, using the popular benchmark dataset CIFAR-10 and the acoustic scene classification task from the DCASE2020 challenge as representatives of computer vision and computer audition, respectively. We report a strong dependence of scoring functions on the training setting, including randomness, which can partly be mitigated through ensemble scoring. While we do not find a general advantage of CL over uniform sampling, we observe that the ordering in which data is presented for CL-based training plays an important role in model performance. Furthermore, we find that the robustness of scoring functions across random seeds positively correlates with CL performance. Finally, we uncover that models trained with different CL strategies complement each other by boosting predictive power through late fusion, likely due to differences in the learnt concepts. Alongside our findings, we release the aucurriculum toolkit (https://github.com/autrainer/aucurriculum), implementing sample difficulty and CL-based training in a modular fashion.
Enhancing Emotional Text-to-Speech Controllability with Natural Language Guidance through Contrastive Learning and Diffusion Models
Sep 10, 2024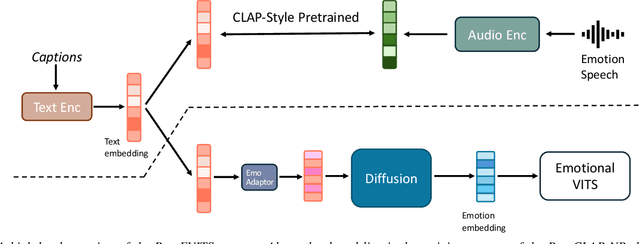
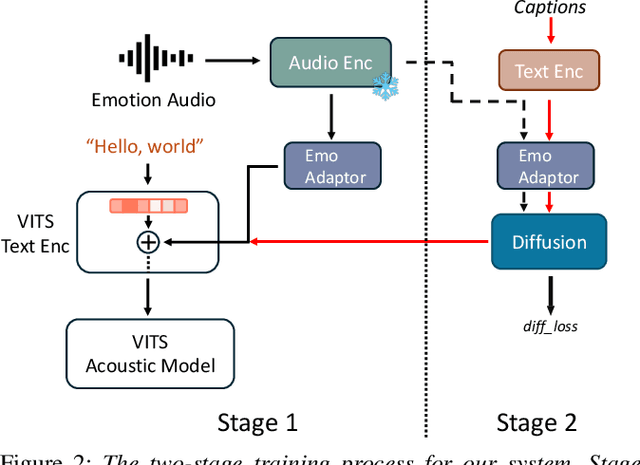

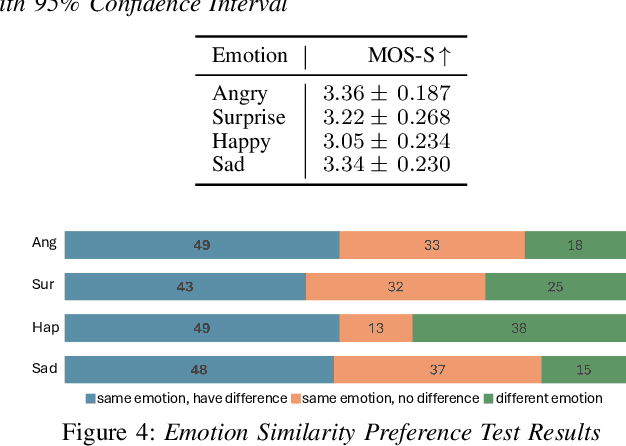
While current emotional text-to-speech (TTS) systems can generate highly intelligible emotional speech, achieving fine control over emotion rendering of the output speech still remains a significant challenge. In this paper, we introduce ParaEVITS, a novel emotional TTS framework that leverages the compositionality of natural language to enhance control over emotional rendering. By incorporating a text-audio encoder inspired by ParaCLAP, a contrastive language-audio pretraining (CLAP) model for computational paralinguistics, the diffusion model is trained to generate emotional embeddings based on textual emotional style descriptions. Our framework first trains on reference audio using the audio encoder, then fine-tunes a diffusion model to process textual inputs from ParaCLAP's text encoder. During inference, speech attributes such as pitch, jitter, and loudness are manipulated using only textual conditioning. Our experiments demonstrate that ParaEVITS effectively control emotion rendering without compromising speech quality. Speech demos are publicly available.
Audio Enhancement for Computer Audition -- An Iterative Training Paradigm Using Sample Importance
Aug 12, 2024Neural network models for audio tasks, such as automatic speech recognition (ASR) and acoustic scene classification (ASC), are susceptible to noise contamination for real-life applications. To improve audio quality, an enhancement module, which can be developed independently, is explicitly used at the front-end of the target audio applications. In this paper, we present an end-to-end learning solution to jointly optimise the models for audio enhancement (AE) and the subsequent applications. To guide the optimisation of the AE module towards a target application, and especially to overcome difficult samples, we make use of the sample-wise performance measure as an indication of sample importance. In experiments, we consider four representative applications to evaluate our training paradigm, i.e., ASR, speech command recognition (SCR), speech emotion recognition (SER), and ASC. These applications are associated with speech and non-speech tasks concerning semantic and non-semantic features, transient and global information, and the experimental results indicate that our proposed approach can considerably boost the noise robustness of the models, especially at low signal-to-noise ratios (SNRs), for a wide range of computer audition tasks in everyday-life noisy environments.
Abusive Speech Detection in Indic Languages Using Acoustic Features
Jul 30, 2024



Abusive content in online social networks is a well-known problem that can cause serious psychological harm and incite hatred. The ability to upload audio data increases the importance of developing methods to detect abusive content in speech recordings. However, simply transferring the mechanisms from written abuse detection would ignore relevant information such as emotion and tone. In addition, many current algorithms require training in the specific language for which they are being used. This paper proposes to use acoustic and prosodic features to classify abusive content. We used the ADIMA data set, which contains recordings from ten Indic languages, and trained different models in multilingual and cross-lingual settings. Our results show that it is possible to classify abusive and non-abusive content using only acoustic and prosodic features. The most important and influential features are discussed.