 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Class Ontology and Data Scale Affect Audio Transfer Learning
Mar 26, 2026Transfer learning is a crucial concept within deep learning that allows artificial neural networks to benefit from a large pre-training data basis when confronted with a task of limited data. Despite its ubiquitous use and clear benefits, there are still many open questions regarding the inner workings of transfer learning and, in particular, regarding the understanding of when and how well it works. To that extent, we perform a rigorous study focusing on audio-to-audio transfer learning, in which we pre-train various model states on (ontology-based) subsets of AudioSet and fine-tune them on three computer audition tasks, namely acoustic scene recognition, bird activity recognition, and speech command recognition. We report that increasing the number of samples and classes in the pre-training data both have a positive impact on transfer learning. This is, however, generally surpassed by similarity between pre-training and the downstream task, which can lead the model to learn comparable features.
autrainer: A Modular and Extensible Deep Learning Toolkit for Computer Audition Tasks
Dec 16, 2024
This work introduces the key operating principles for autrainer, our new deep learning training framework for computer audition tasks. autrainer is a PyTorch-based toolkit that allows for rapid, reproducible, and easily extensible training on a variety of different computer audition tasks. Concretely, autrainer offers low-code training and supports a wide range of neural networks as well as preprocessing routines. In this work, we present an overview of its inner workings and key capabilities.
Does the Definition of Difficulty Matter? Scoring Functions and their Role for Curriculum Learning
Nov 01, 2024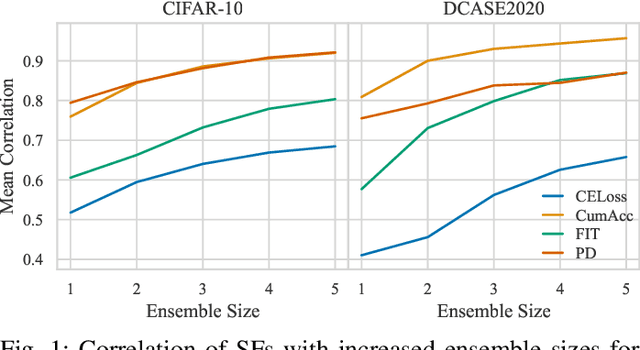
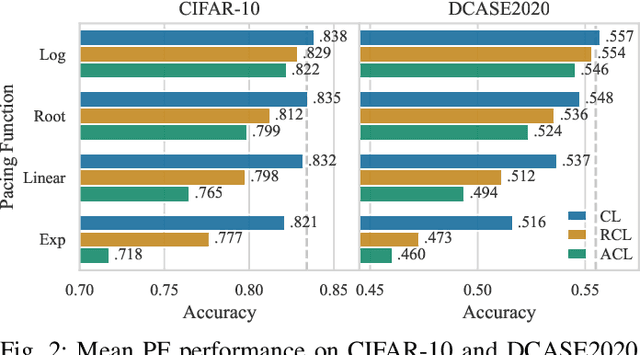
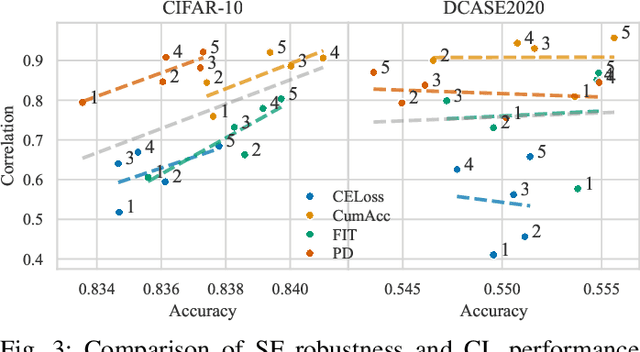
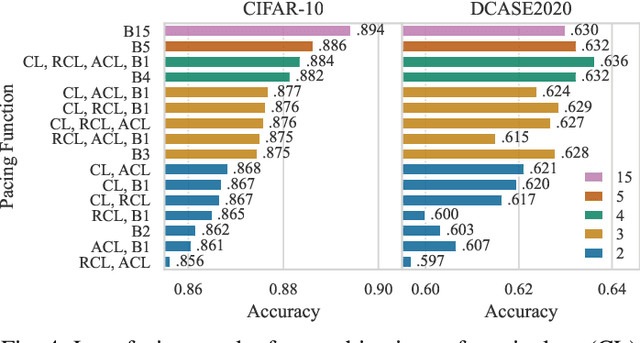
Curriculum learning (CL) describes a machine learning training strategy in which samples are gradually introduced into the training process based on their difficulty. Despite a partially contradictory body of evidence in the literature, CL finds popularity in deep learning research due to its promise of leveraging human-inspired curricula to achieve higher model performance. Yet, the subjectivity and biases that follow any necessary definition of difficulty, especially for those found in orderings derived from models or training statistics, have rarely been investigated. To shed more light on the underlying unanswered questions, we conduct an extensive study on the robustness and similarity of the most common scoring functions for sample difficulty estimation, as well as their potential benefits in CL, using the popular benchmark dataset CIFAR-10 and the acoustic scene classification task from the DCASE2020 challenge as representatives of computer vision and computer audition, respectively. We report a strong dependence of scoring functions on the training setting, including randomness, which can partly be mitigated through ensemble scoring. While we do not find a general advantage of CL over uniform sampling, we observe that the ordering in which data is presented for CL-based training plays an important role in model performance. Furthermore, we find that the robustness of scoring functions across random seeds positively correlates with CL performance. Finally, we uncover that models trained with different CL strategies complement each other by boosting predictive power through late fusion, likely due to differences in the learnt concepts. Alongside our findings, we release the aucurriculum toolkit (https://github.com/autrainer/aucurriculum), implementing sample difficulty and CL-based training in a modular fashion.
INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
Jun 10, 2024
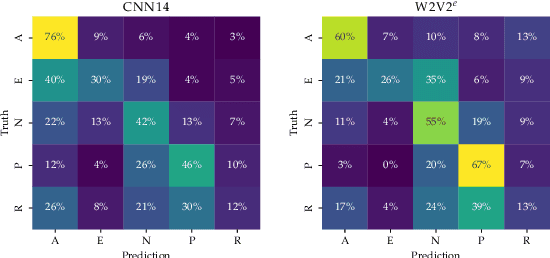
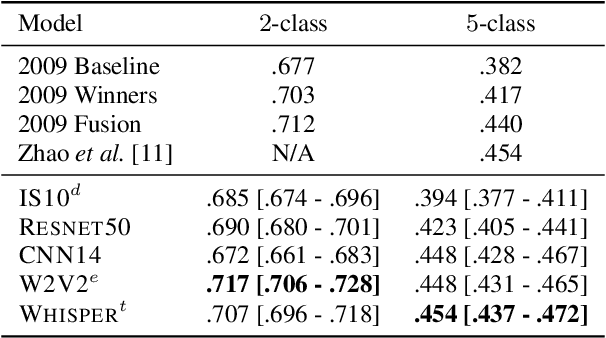
We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
An automatic analysis of ultrasound vocalisations for the prediction of interaction context in captive Egyptian fruit bats
Jun 10, 2024Prior work in computational bioacoustics has mostly focused on the detection of animal presence in a particular habitat. However, animal sounds contain much richer information than mere presence; among others, they encapsulate the interactions of those animals with other members of their species. Studying these interactions is almost impossible in a naturalistic setting, as the ground truth is often lacking. The use of animals in captivity instead offers a viable alternative pathway. However, most prior works follow a traditional, statistics-based approach to analysing interactions. In the present work, we go beyond this standard framework by attempting to predict the underlying context in interactions between captive \emph{Rousettus Aegyptiacus} using deep neural networks. We reach an unweighted average recall of over 30\% -- more than thrice the chance level -- and show error patterns that differ from our statistical analysis. This work thus represents an important step towards the automatic analysis of states in animals from sound.