 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarseSoundNet: Building a reliable model for ecological soundscape analysis
May 21, 2026A soundscape is composed of three types of sound: biophony (sounds made by animals), geophony (natural abiotic sounds) and anthropophony (sounds made by humans). A key research question in the field of soundscape ecology is how these components interact with each other, specifically how biophony responds to geophony and anthropophony. Nevertheless, as of today, there are not many analytical instruments that enable the distinct quantification of these elements. Recent machine learning (ML) approaches aim to support automated analysis but often rely on task-specific or clean data, limiting generalisation to noisy passive acoustic monitoring (PAM) recordings. This study presents a clear and reproducible structure to build ML models for coarse soundscape classification and introduces CoarseSoundNet, a deep learning model trained to distinguish biophony, geophony, and anthropophony under realistic PAM conditions. We systematically investigate model architectures, the influence of an additional training class, data composition, and evaluation strategies. Our findings suggest that model performance improves with additional PAM data, especially when similar to the target domain, and by introducing an explicit silence class during training. Class-specific decision thresholds and duration-based constraints further enhance performance, particularly for anthropophony and geophony. Error analyses exhibit challenges for anthropophony due to masking effects and confusions for silence and insect sounds for geophony and biophony. Finally, we conduct an ecological case study which shows that pre-filtering recordings with CoarseSoundNet yields acoustic index trends comparable to ground-truth filtering, supporting its use as an effective preprocessing tool for ecoacoustic analyses.
How Class Ontology and Data Scale Affect Audio Transfer Learning
Mar 26, 2026Transfer learning is a crucial concept within deep learning that allows artificial neural networks to benefit from a large pre-training data basis when confronted with a task of limited data. Despite its ubiquitous use and clear benefits, there are still many open questions regarding the inner workings of transfer learning and, in particular, regarding the understanding of when and how well it works. To that extent, we perform a rigorous study focusing on audio-to-audio transfer learning, in which we pre-train various model states on (ontology-based) subsets of AudioSet and fine-tune them on three computer audition tasks, namely acoustic scene recognition, bird activity recognition, and speech command recognition. We report that increasing the number of samples and classes in the pre-training data both have a positive impact on transfer learning. This is, however, generally surpassed by similarity between pre-training and the downstream task, which can lead the model to learn comparable features.
ECOSoundSet: a finely annotated dataset for the automated acoustic identification of Orthoptera and Cicadidae in North, Central and temperate Western Europe
Apr 29, 2025Currently available tools for the automated acoustic recognition of European insects in natural soundscapes are limited in scope. Large and ecologically heterogeneous acoustic datasets are currently needed for these algorithms to cross-contextually recognize the subtle and complex acoustic signatures produced by each species, thus making the availability of such datasets a key requisite for their development. Here we present ECOSoundSet (European Cicadidae and Orthoptera Sound dataSet), a dataset containing 10,653 recordings of 200 orthopteran and 24 cicada species (217 and 26 respective taxa when including subspecies) present in North, Central, and temperate Western Europe (Andorra, Belgium, Denmark, mainland France and Corsica, Germany, Ireland, Luxembourg, Monaco, Netherlands, United Kingdom, Switzerland), collected partly through targeted fieldwork in South France and Catalonia and partly through contributions from various European entomologists. The dataset is composed of a combination of coarsely labeled recordings, for which we can only infer the presence, at some point, of their target species (weak labeling), and finely annotated recordings, for which we know the specific time and frequency range of each insect sound present in the recording (strong labeling). We also provide a train/validation/test split of the strongly labeled recordings, with respective approximate proportions of 0.8, 0.1 and 0.1, in order to facilitate their incorporation in the training and evaluation of deep learning algorithms. This dataset could serve as a meaningful complement to recordings already available online for the training of deep learning algorithms for the acoustic classification of orthopterans and cicadas in North, Central, and temperate Western Europe.
Computer Audition: From Task-Specific Machine Learning to Foundation Models
Jul 22, 2024Foundation models (FMs) are increasingly spearheading recent advances on a variety of tasks that fall under the purview of computer audition -- the use of machines to understand sounds. They feature several advantages over traditional pipelines: among others, the ability to consolidate multiple tasks in a single model, the option to leverage knowledge from other modalities, and the readily-available interaction with human users. Naturally, these promises have created substantial excitement in the audio community, and have led to a wave of early attempts to build new, general-purpose foundation models for audio. In the present contribution, we give an overview of computational audio analysis as it transitions from traditional pipelines towards auditory foundation models. Our work highlights the key operating principles that underpin those models, and showcases how they can accommodate multiple tasks that the audio community previously tackled separately.
DB3V: A Dialect Dominated Dataset of Bird Vocalisation for Cross-corpus Bird Species Recognition
Jun 11, 2024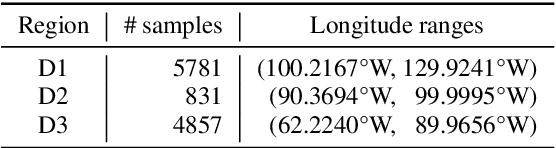
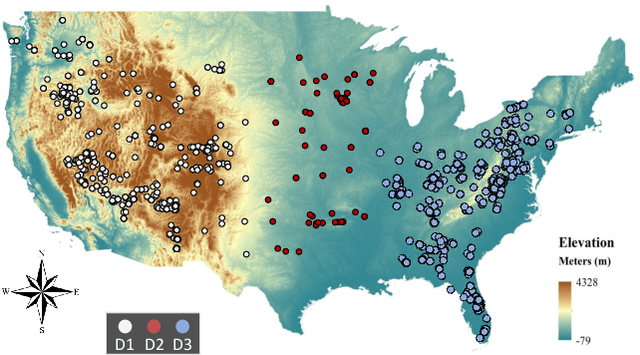
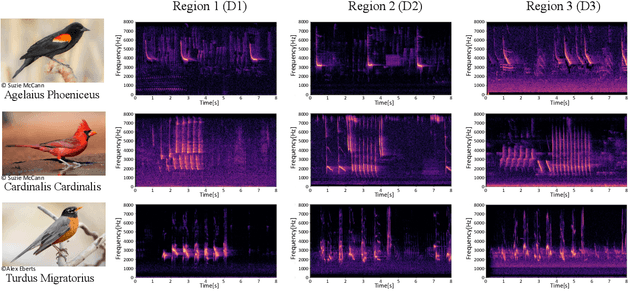
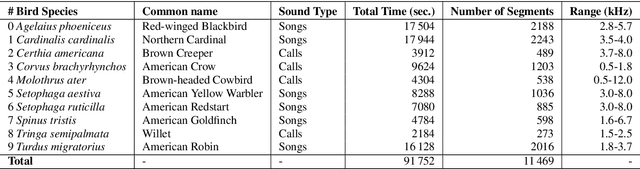
In ornithology, bird species are known to have variedit's widely acknowledged that bird species display diverse dialects in their calls across different regions. Consequently, computational methods to identify bird species onsolely through their calls face critsignificalnt challenges. There is growing interest in understanding the impact of species-specific dialects on the effectiveness of bird species recognition methods. Despite potential mitigation through the expansion of dialect datasets, the absence of publicly available testing data currently impedes robust benchmarking efforts. This paper presents the Dialect Dominated Dataset of Bird Vocalisation, the first cross-corpus dataset that focuses on dialects in bird vocalisations. The DB3V comprises more than 25 hours of audio recordings from 10 bird species distributed across three distinct regions in the contiguous United States (CONUS). In addition to presenting the dataset, we conduct analyses and establish baseline models for cross-corpus bird recognition. The data and code are publicly available online: https://zenodo.org/records/11544734
An automatic analysis of ultrasound vocalisations for the prediction of interaction context in captive Egyptian fruit bats
Jun 10, 2024Prior work in computational bioacoustics has mostly focused on the detection of animal presence in a particular habitat. However, animal sounds contain much richer information than mere presence; among others, they encapsulate the interactions of those animals with other members of their species. Studying these interactions is almost impossible in a naturalistic setting, as the ground truth is often lacking. The use of animals in captivity instead offers a viable alternative pathway. However, most prior works follow a traditional, statistics-based approach to analysing interactions. In the present work, we go beyond this standard framework by attempting to predict the underlying context in interactions between captive \emph{Rousettus Aegyptiacus} using deep neural networks. We reach an unweighted average recall of over 30\% -- more than thrice the chance level -- and show error patterns that differ from our statistical analysis. This work thus represents an important step towards the automatic analysis of states in animals from sound.
Audio-based Step-count Estimation for Running -- Windowing and Neural Network Baselines
Jun 10, 2024In recent decades, running has become an increasingly popular pastime activity due to its accessibility, ease of practice, and anticipated health benefits. However, the risk of running-related injuries is substantial for runners of different experience levels. Several common forms of injuries result from overuse -- extending beyond the recommended running time and intensity. Recently, audio-based tracking has emerged as yet another modality for monitoring running behaviour and performance, with previous studies largely concentrating on predicting runner fatigue. In this work, we investigate audio-based step count estimation during outdoor running, achieving a mean absolute error of 1.098 in window-based step-count differences and a Pearson correlation coefficient of 0.479 when predicting the number of steps in a 5-second window of audio. Our work thus showcases the feasibility of audio-based monitoring for estimating important physiological variables and lays the foundations for further utilising audio sensors for a more thorough characterisation of runner behaviour.
Exploring Meta Information for Audio-based Zero-shot Bird Classification
Sep 15, 2023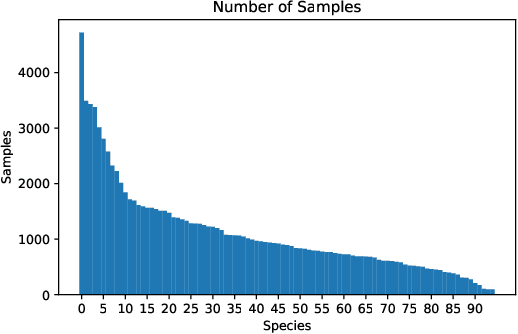
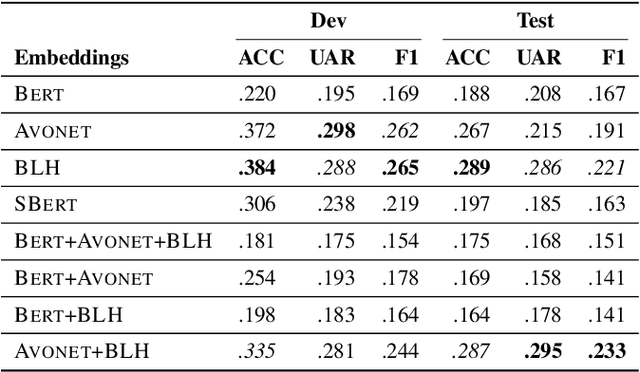
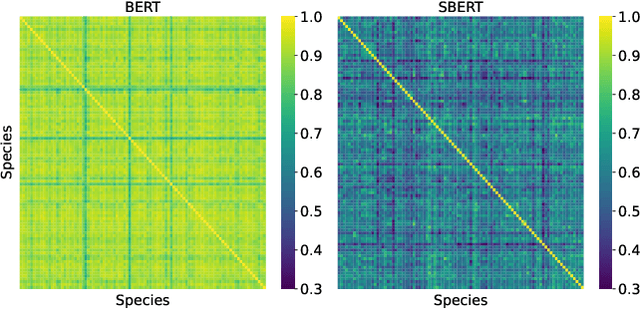
Advances in passive acoustic monitoring and machine learning have led to the procurement of vast datasets for computational bioacoustic research. Nevertheless, data scarcity is still an issue for rare and underrepresented species. This study investigates how meta-information can improve zero-shot audio classification, utilising bird species as an example case study due to the availability of rich and diverse metadata. We investigate three different sources of metadata: textual bird sound descriptions encoded via (S)BERT, functional traits (AVONET), and bird life-history (BLH) characteristics. As audio features, we extract audio spectrogram transformer (AST) embeddings and project them to the dimension of the auxiliary information by adopting a single linear layer. Then, we employ the dot product as compatibility function and a standard zero-shot learning ranking hinge loss to determine the correct class. The best results are achieved by concatenating the AVONET and BLH features attaining a mean F1-score of .233 over five different test sets with 8 to 10 classes.
HEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023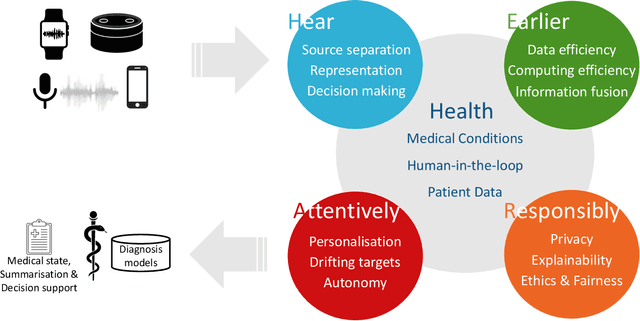

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
Computational Charisma -- A Brick by Brick Blueprint for Building Charismatic Artificial Intelligence
Dec 31, 2022


Charisma is considered as one's ability to attract and potentially also influence others. Clearly, there can be considerable interest from an artificial intelligence's (AI) perspective to provide it with such skill. Beyond, a plethora of use cases opens up for computational measurement of human charisma, such as for tutoring humans in the acquisition of charisma, mediating human-to-human conversation, or identifying charismatic individuals in big social data. A number of models exist that base charisma on various dimensions, often following the idea that charisma is given if someone could and would help others. Examples include influence (could help) and affability (would help) in scientific studies or power (could help), presence, and warmth (both would help) as a popular concept. Modelling high levels in these dimensions for humanoid robots or virtual agents, seems accomplishable. Beyond, also automatic measurement appears quite feasible with the recent advances in the related fields of Affective Computing and Social Signal Processing. Here, we, thereforem present a blueprint for building machines that can appear charismatic, but also analyse the charisma of others. To this end, we first provide the psychological perspective including different models of charisma and behavioural cues of it. We then switch to conversational charisma in spoken language as an exemplary modality that is essential for human-human and human-computer conversations. The computational perspective then deals with the recognition and generation of charismatic behaviour by AI. This includes an overview of the state of play in the field and the aforementioned blueprint. We then name exemplary use cases of computational charismatic skills before switching to ethical aspects and concluding this overview and perspective on building charisma-enabled AI.