 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MuSe 2024 Multimodal Sentiment Analysis Challenge: Social Perception and Humor Recognition
Jun 11, 2024



The Multimodal Sentiment Analysis Challenge (MuSe) 2024 addresses two contemporary multimodal affect and sentiment analysis problems: In the Social Perception Sub-Challenge (MuSe-Perception), participants will predict 16 different social attributes of individuals such as assertiveness, dominance, likability, and sincerity based on the provided audio-visual data. The Cross-Cultural Humor Detection Sub-Challenge (MuSe-Humor) dataset expands upon the Passau Spontaneous Football Coach Humor (Passau-SFCH) dataset, focusing on the detection of spontaneous humor in a cross-lingual and cross-cultural setting. The main objective of MuSe 2024 is to unite a broad audience from various research domains, including multimodal sentiment analysis, audio-visual affective computing, continuous signal processing, and natural language processing. By fostering collaboration and exchange among experts in these fields, the MuSe 2024 endeavors to advance the understanding and application of sentiment analysis and affective computing across multiple modalities. This baseline paper provides details on each sub-challenge and its corresponding dataset, extracted features from each data modality, and discusses challenge baselines. For our baseline system, we make use of a range of Transformers and expert-designed features and train Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) models on them, resulting in a competitive baseline system. On the unseen test datasets of the respective sub-challenges, it achieves a mean Pearson's Correlation Coefficient ($\rho$) of 0.3573 for MuSe-Perception and an Area Under the Curve (AUC) value of 0.8682 for MuSe-Humor.
Enhancing Suicide Risk Assessment: A Speech-Based Automated Approach in Emergency Medicine
Apr 18, 2024
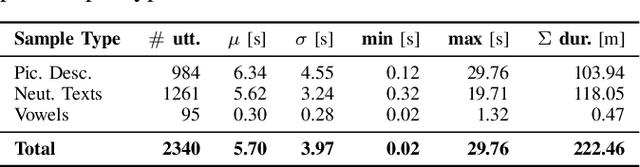
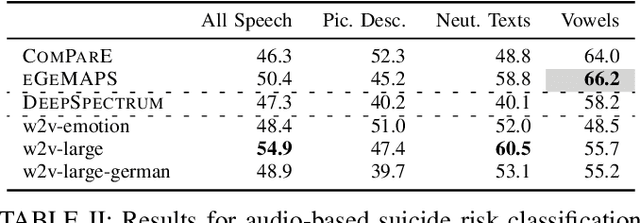
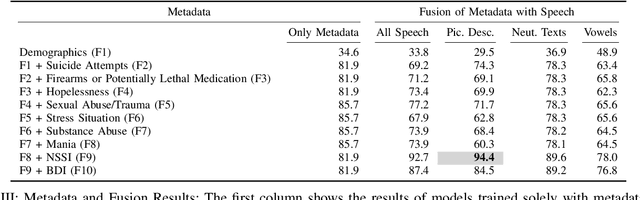
The delayed access to specialized psychiatric assessments and care for patients at risk of suicidal tendencies in emergency departments creates a notable gap in timely intervention, hindering the provision of adequate mental health support during critical situations. To address this, we present a non-invasive, speech-based approach for automatic suicide risk assessment. For our study, we have collected a novel dataset of speech recordings from $20$ patients from which we extract three sets of features, including wav2vec, interpretable speech and acoustic features, and deep learning-based spectral representations. We proceed by conducting a binary classification to assess suicide risk in a leave-one-subject-out fashion. Our most effective speech model achieves a balanced accuracy of $66.2\,\%$. Moreover, we show that integrating our speech model with a series of patients' metadata, such as the history of suicide attempts or access to firearms, improves the overall result. The metadata integration yields a balanced accuracy of $94.4\,\%$, marking an absolute improvement of $28.2\,\%$, demonstrating the efficacy of our proposed approaches for automatic suicide risk assessment in emergency medicine.
Exploring Meta Information for Audio-based Zero-shot Bird Classification
Sep 15, 2023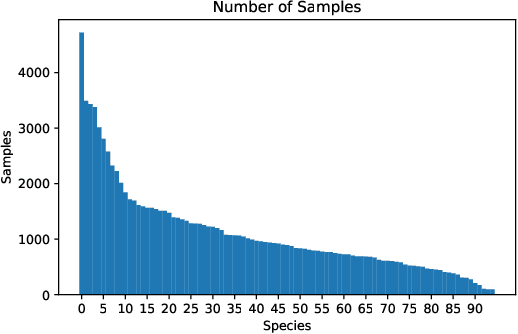
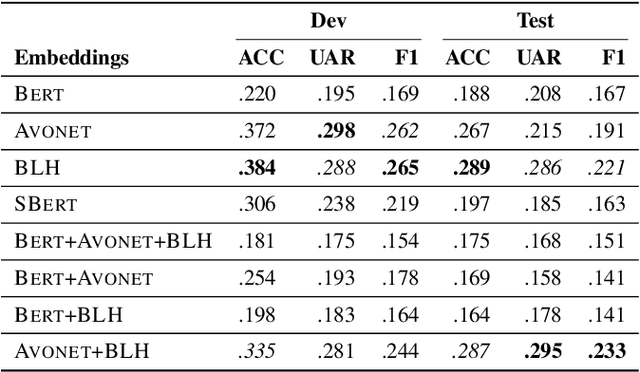
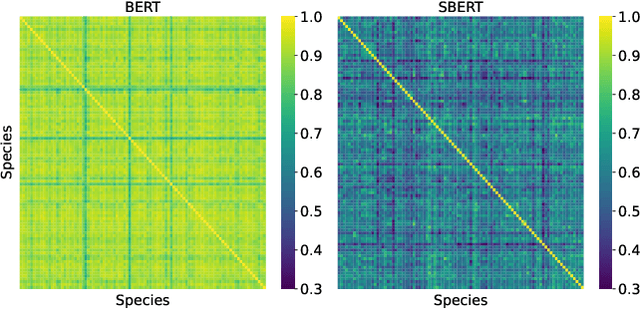
Advances in passive acoustic monitoring and machine learning have led to the procurement of vast datasets for computational bioacoustic research. Nevertheless, data scarcity is still an issue for rare and underrepresented species. This study investigates how meta-information can improve zero-shot audio classification, utilising bird species as an example case study due to the availability of rich and diverse metadata. We investigate three different sources of metadata: textual bird sound descriptions encoded via (S)BERT, functional traits (AVONET), and bird life-history (BLH) characteristics. As audio features, we extract audio spectrogram transformer (AST) embeddings and project them to the dimension of the auxiliary information by adopting a single linear layer. Then, we employ the dot product as compatibility function and a standard zero-shot learning ranking hinge loss to determine the correct class. The best results are achieved by concatenating the AVONET and BLH features attaining a mean F1-score of .233 over five different test sets with 8 to 10 classes.
Executive Voiced Laughter and Social Approval: An Explorative Machine Learning Study
May 20, 2023

We study voiced laughter in executive communication and its effect on social approval. Integrating research on laughter, affect-as-information, and infomediaries' social evaluations of firms, we hypothesize that voiced laughter in executive communication positively affects social approval, defined as audience perceptions of affinity towards an organization. We surmise that the effect of laughter is especially strong for joint laughter, i.e., the number of instances in a given communication venue for which the focal executive and the audience laugh simultaneously. Finally, combining the notions of affect-as-information and negativity bias in human cognition, we hypothesize that the positive effect of laughter on social approval increases with bad organizational performance. We find partial support for our ideas when testing them on panel data comprising 902 German Bundesliga soccer press conferences and media tenor, applying state-of-the-art machine learning approaches for laughter detection as well as sentiment analysis. Our findings contribute to research at the nexus of executive communication, strategic leadership, and social evaluations, especially by introducing laughter as a highly consequential potential, but understudied social lubricant at the executive-infomediary interface. Our research is unique by focusing on reflexive microprocesses of social evaluations, rather than the infomediary-routines perspectives in infomediaries' evaluations. We also make methodological contributions.
The MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023



The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.
HEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023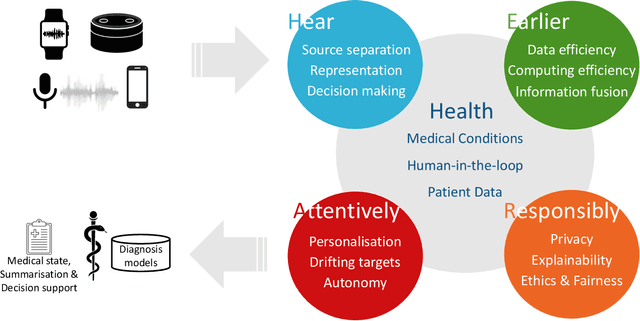

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
Computational Charisma -- A Brick by Brick Blueprint for Building Charismatic Artificial Intelligence
Dec 31, 2022


Charisma is considered as one's ability to attract and potentially also influence others. Clearly, there can be considerable interest from an artificial intelligence's (AI) perspective to provide it with such skill. Beyond, a plethora of use cases opens up for computational measurement of human charisma, such as for tutoring humans in the acquisition of charisma, mediating human-to-human conversation, or identifying charismatic individuals in big social data. A number of models exist that base charisma on various dimensions, often following the idea that charisma is given if someone could and would help others. Examples include influence (could help) and affability (would help) in scientific studies or power (could help), presence, and warmth (both would help) as a popular concept. Modelling high levels in these dimensions for humanoid robots or virtual agents, seems accomplishable. Beyond, also automatic measurement appears quite feasible with the recent advances in the related fields of Affective Computing and Social Signal Processing. Here, we, thereforem present a blueprint for building machines that can appear charismatic, but also analyse the charisma of others. To this end, we first provide the psychological perspective including different models of charisma and behavioural cues of it. We then switch to conversational charisma in spoken language as an exemplary modality that is essential for human-human and human-computer conversations. The computational perspective then deals with the recognition and generation of charismatic behaviour by AI. This includes an overview of the state of play in the field and the aforementioned blueprint. We then name exemplary use cases of computational charismatic skills before switching to ethical aspects and concluding this overview and perspective on building charisma-enabled AI.
Multimodal Prediction of Spontaneous Humour: A Novel Dataset and First Results
Sep 28, 2022
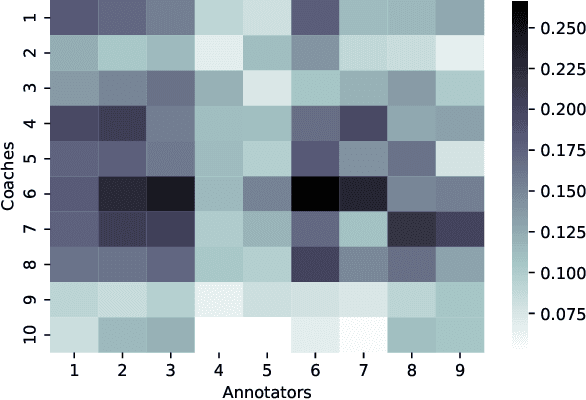

Humour is a substantial element of human affect and cognition. Its automatic understanding can facilitate a more naturalistic human-device interaction and the humanisation of artificial intelligence. Current methods of humour detection are solely based on staged data making them inadequate for 'real-world' applications. We address this deficiency by introducing the novel Passau-Spontaneous Football Coach Humour (Passau-SFCH) dataset, comprising of about 11 hours of recordings. The Passau-SFCH dataset is annotated for the presence of humour and its dimensions (sentiment and direction) as proposed in Martin's Humor Style Questionnaire. We conduct a series of experiments, employing pretrained Transformers, convolutional neural networks, and expert-designed features. The performance of each modality (text, audio, video) for spontaneous humour recognition is analysed and their complementarity is investigated. Our findings suggest that for the automatic analysis of humour and its sentiment, facial expressions are most promising, while humour direction can be best modelled via text-based features. The results reveal considerable differences among various subjects, highlighting the individuality of humour usage and style. Further, we observe that a decision-level fusion yields the best recognition result. Finally, we make our code publicly available at https://www.github.com/EIHW/passau-sfch. The Passau-SFCH dataset is available upon request.
Depression Diagnosis and Forecast based on Mobile Phone Sensor Data
May 10, 2022
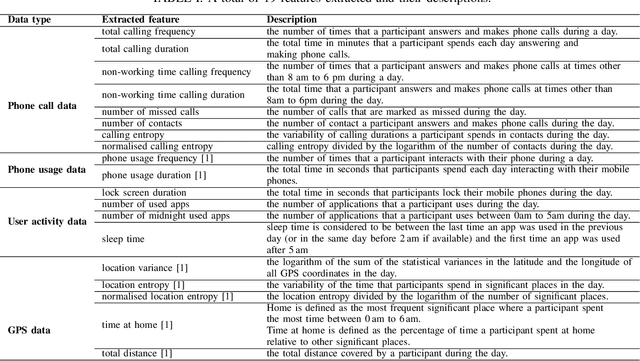

Previous studies have shown the correlation between sensor data collected from mobile phones and human depression states. Compared to the traditional self-assessment questionnaires, the passive data collected from mobile phones is easier to access and less time-consuming. In particular, passive mobile phone data can be collected on a flexible time interval, thus detecting moment-by-moment psychological changes and helping achieve earlier interventions. Moreover, while previous studies mainly focused on depression diagnosis using mobile phone data, depression forecasting has not received sufficient attention. In this work, we extract four types of passive features from mobile phone data, including phone call, phone usage, user activity, and GPS features. We implement a long short-term memory (LSTM) network in a subject-independent 10-fold cross-validation setup to model both a diagnostic and a forecasting tasks. Experimental results show that the forecasting task achieves comparable results with the diagnostic task, which indicates the possibility of forecasting depression from mobile phone sensor data. Our model achieves an accuracy of 77.0 % for major depression forecasting (binary), an accuracy of 53.7 % for depression severity forecasting (5 classes), and a best RMSE score of 4.094 (PHQ-9, range from 0 to 27).
Journaling Data for Daily PHQ-2 Depression Prediction and Forecasting
May 06, 2022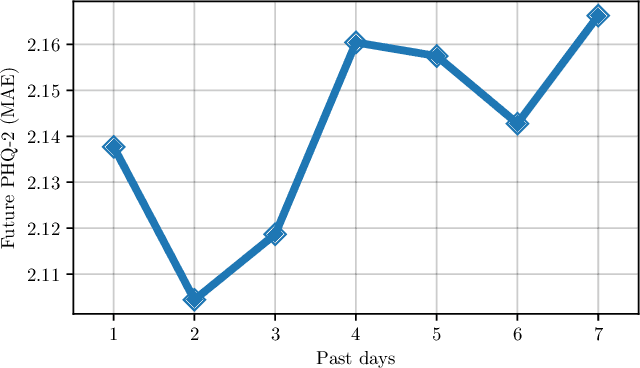
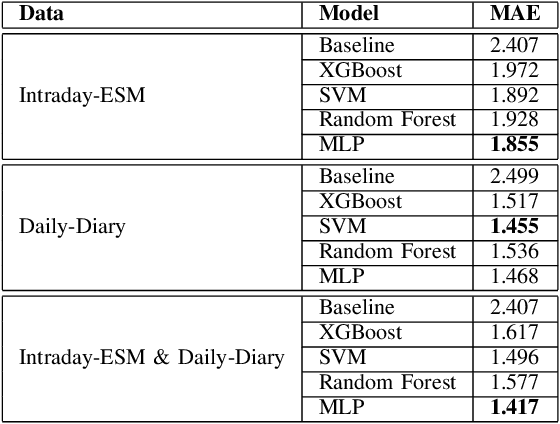

Digital health applications are becoming increasingly important for assessing and monitoring the wellbeing of people suffering from mental health conditions like depression. A common target of said applications is to predict the results of self-assessed Patient-Health-Questionnaires (PHQ), indicating current symptom severity of depressive individuals. In this work, we explore the potential of using actively-collected data to predict and forecast daily PHQ-2 scores on a newly-collected longitudinal dataset. We obtain a best MAE of 1.417 for daily prediction of PHQ-2 scores, which specifically in the used dataset have a range of 0 to 12, using leave-one-subject-out cross-validation, as well as a best MAE of 1.914 for forecasting PHQ-2 scores using data from up to the last 7 days. This illustrates the additive value that can be obtained by incorporating actively-collected data in a depression monitoring application.