 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NeurIPS 2023 Machine Learning for Audio Workshop: Affective Audio Benchmarks and Novel Data
Mar 21, 2024


The NeurIPS 2023 Machine Learning for Audio Workshop brings together machine learning (ML) experts from various audio domains. There are several valuable audio-driven ML tasks, from speech emotion recognition to audio event detection, but the community is sparse compared to other ML areas, e.g., computer vision or natural language processing. A major limitation with audio is the available data; with audio being a time-dependent modality, high-quality data collection is time-consuming and costly, making it challenging for academic groups to apply their often state-of-the-art strategies to a larger, more generalizable dataset. In this short white paper, to encourage researchers with limited access to large-datasets, the organizers first outline several open-source datasets that are available to the community, and for the duration of the workshop are making several propriety datasets available. Namely, three vocal datasets, Hume-Prosody, Hume-VocalBurst, an acted emotional speech dataset Modulate-Sonata, and an in-game streamer dataset Modulate-Stream. We outline the current baselines on these datasets but encourage researchers from across audio to utilize them outside of the initial baseline tasks.
The 6th Affective Behavior Analysis in-the-wild Competition
Mar 12, 2024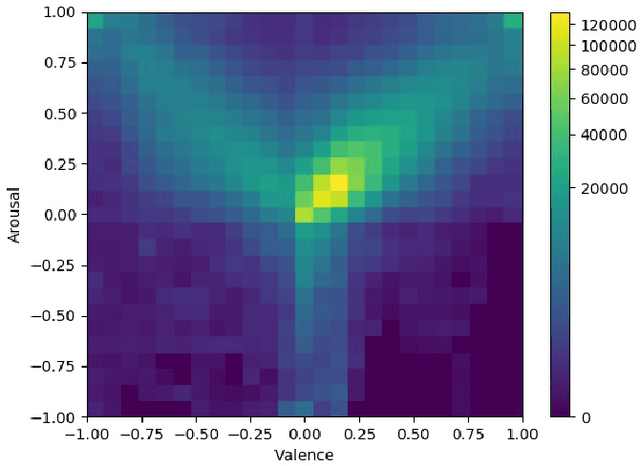
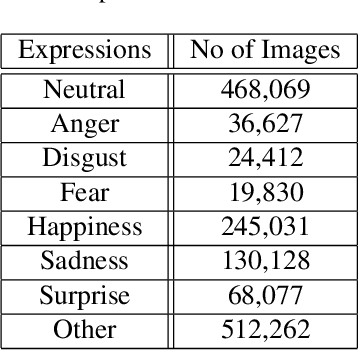
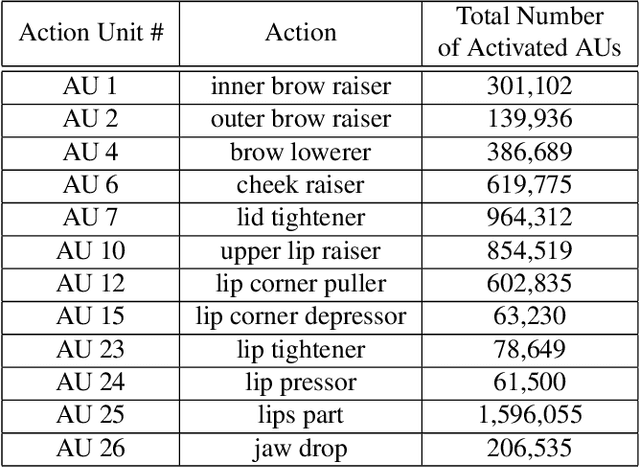
This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: https://affective-behavior-analysis-in-the-wild.github.io/6th.
The Inner Sentiments of a Thought
Jul 04, 2023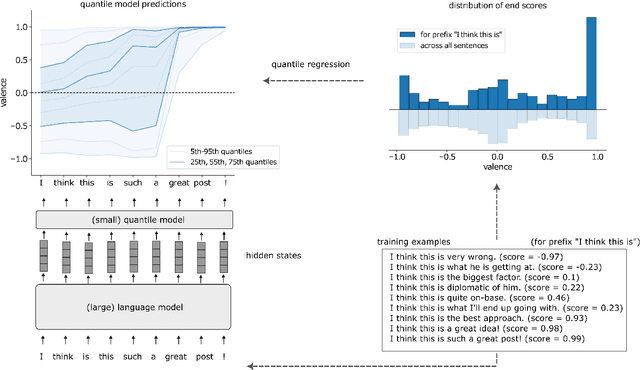
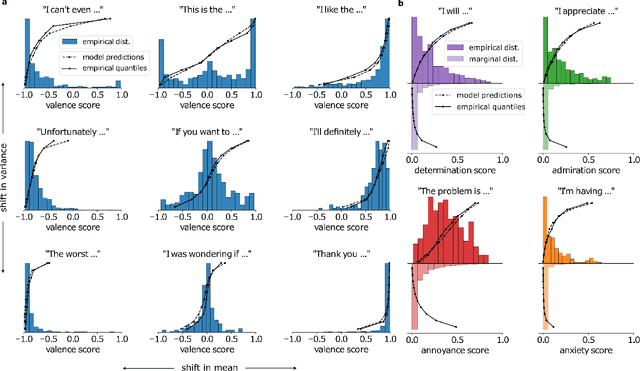
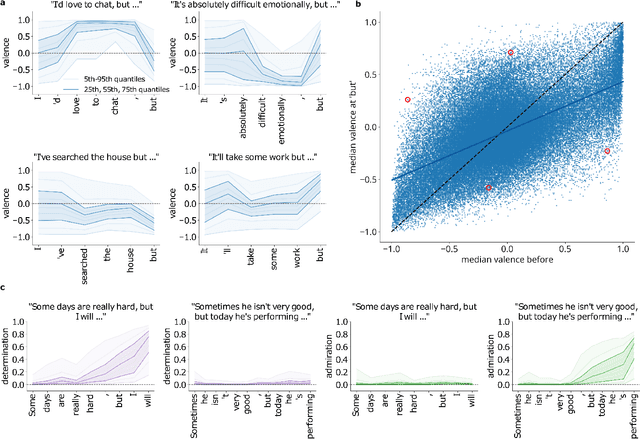
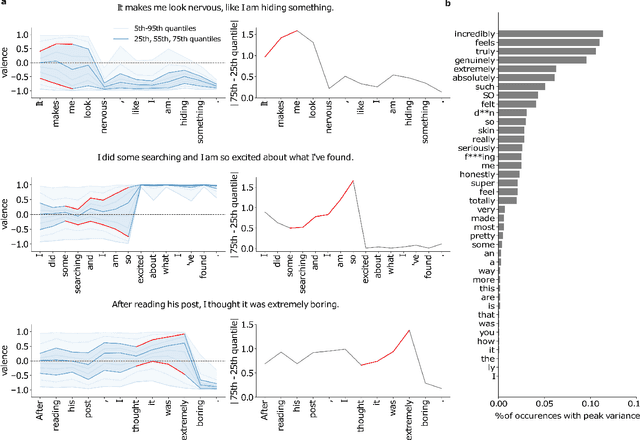
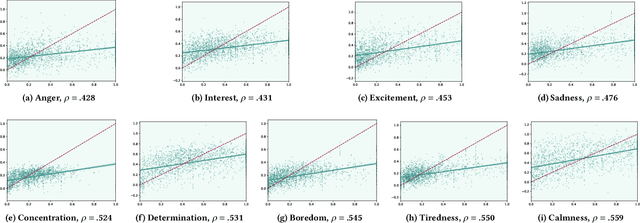
Transformer-based large-scale language models (LLMs) are able to generate highly realistic text. They are duly able to express, and at least implicitly represent, a wide range of sentiments and color, from the obvious, such as valence and arousal to the subtle, such as determination and admiration. We provide a first exploration of these representations and how they can be used for understanding the inner sentimental workings of single sentences. We train predictors of the quantiles of the distributions of final sentiments of sentences from the hidden representations of an LLM applied to prefixes of increasing lengths. After showing that predictors of distributions of valence, determination, admiration, anxiety and annoyance are well calibrated, we provide examples of using these predictors for analyzing sentences, illustrating, for instance, how even ordinary conjunctions (e.g., "but") can dramatically alter the emotional trajectory of an utterance. We then show how to exploit the distributional predictions to generate sentences with sentiments in the tails of distributions. We discuss the implications of our results for the inner workings of thoughts, for instance for psychiatric dysfunction.
The MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023



The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.
The ACM Multimedia 2023 Computational Paralinguistics Challenge: Emotion Share & Requests
May 01, 2023
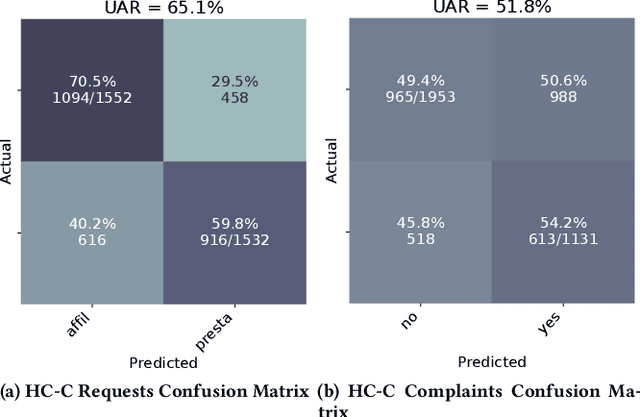

The ACM Multimedia 2023 Computational Paralinguistics Challenge addresses two different problems for the first time in a research competition under well-defined conditions: In the Emotion Share Sub-Challenge, a regression on speech has to be made; and in the Requests Sub-Challenges, requests and complaints need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, wav2vec2 models are used.
Catastrophe, Compounding & Consistency in Choice
Nov 12, 2021
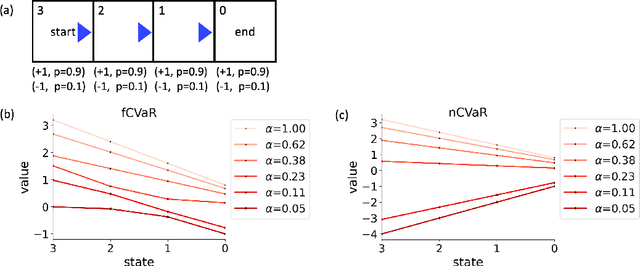
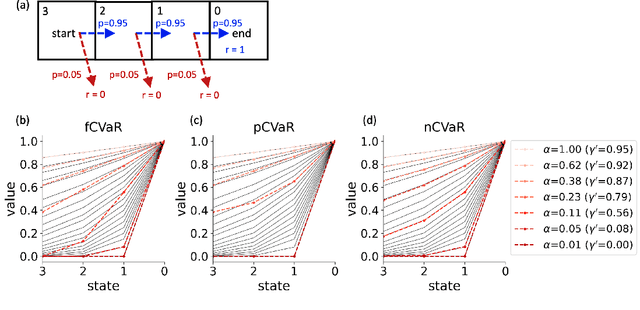
Conditional value-at-risk (CVaR) precisely characterizes the influence that rare, catastrophic events can exert over decisions. Such characterizations are important for both normal decision-making and for psychiatric conditions such as anxiety disorders -- especially for sequences of decisions that might ultimately lead to disaster. CVaR, like other well-founded risk measures, compounds in complex ways over such sequences -- and we recently formalized three structurally different forms in which risk either averages out or multiplies. Unfortunately, existing cognitive tasks fail to discriminate these approaches well; here, we provide examples that highlight their unique characteristics, and make formal links to temporal discounting for the two of the approaches that are time consistent. These examples can ground future experiments with the broader aim of characterizing risk attitudes, especially for longer horizon problems and in psychopathological populations.
Two steps to risk sensitivity
Nov 12, 2021
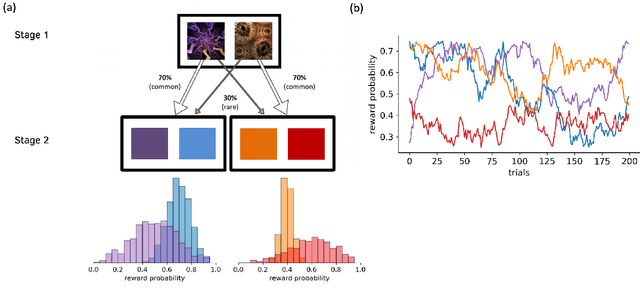
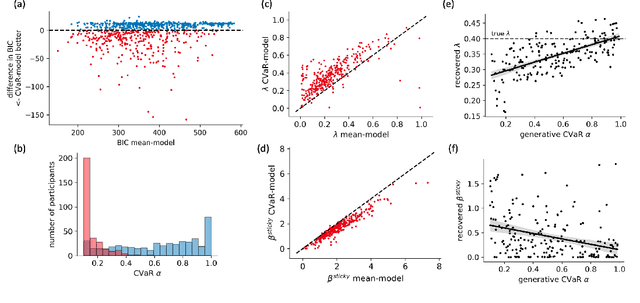
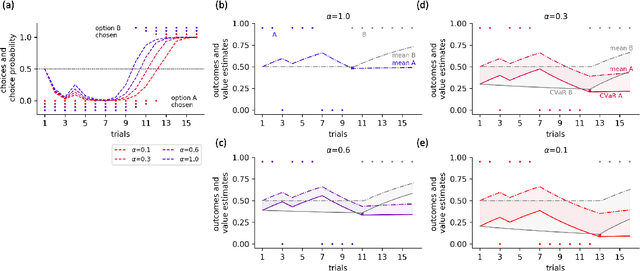
Distributional reinforcement learning (RL) -- in which agents learn about all the possible long-term consequences of their actions, and not just the expected value -- is of great recent interest. One of the most important affordances of a distributional view is facilitating a modern, measured, approach to risk when outcomes are not completely certain. By contrast, psychological and neuroscientific investigations into decision making under risk have utilized a variety of more venerable theoretical models such as prospect theory that lack axiomatically desirable properties such as coherence. Here, we consider a particularly relevant risk measure for modeling human and animal planning, called conditional value-at-risk (CVaR), which quantifies worst-case outcomes (e.g., vehicle accidents or predation). We first adopt a conventional distributional approach to CVaR in a sequential setting and reanalyze the choices of human decision-makers in the well-known two-step task, revealing substantial risk aversion that had been lurking under stickiness and perseveration. We then consider a further critical property of risk sensitivity, namely time consistency, showing alternatives to this form of CVaR that enjoy this desirable characteristic. We use simulations to examine settings in which the various forms differ in ways that have implications for human and animal planning and behavior.