 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogy making as amortised model construction
Jul 22, 2025Humans flexibly construct internal models to navigate novel situations. To be useful, these internal models must be sufficiently faithful to the environment that resource-limited planning leads to adequate outcomes; equally, they must be tractable to construct in the first place. We argue that analogy plays a central role in these processes, enabling agents to reuse solution-relevant structure from past experiences and amortise the computational costs of both model construction (construal) and planning. Formalising analogies as partial homomorphisms between Markov decision processes, we sketch a framework in which abstract modules, derived from previous construals, serve as composable building blocks for new ones. This modular reuse allows for flexible adaptation of policies and representations across domains with shared structural essence.
Concept-Guided Interpretability via Neural Chunking
May 16, 2025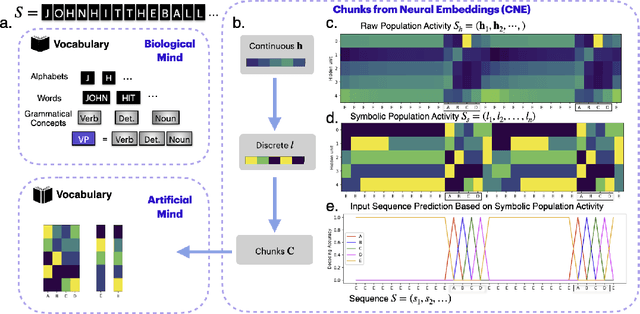
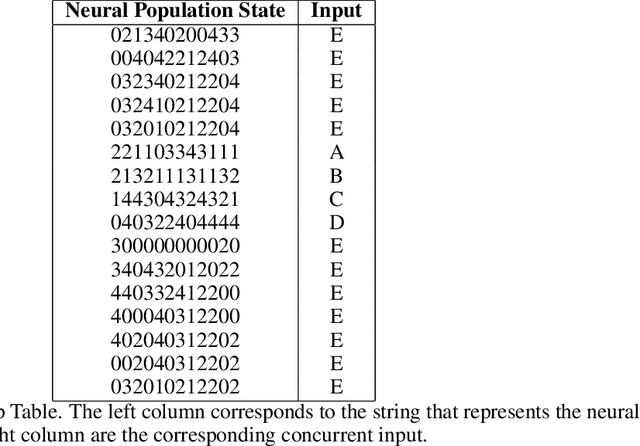
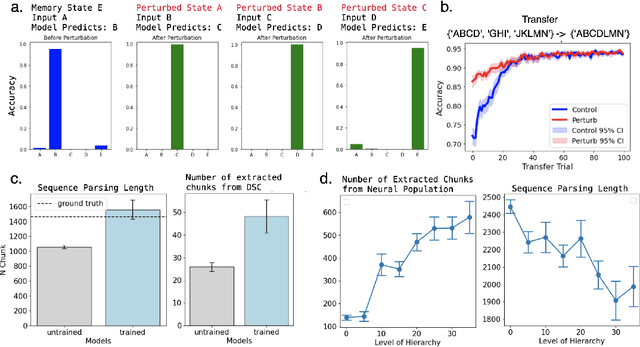
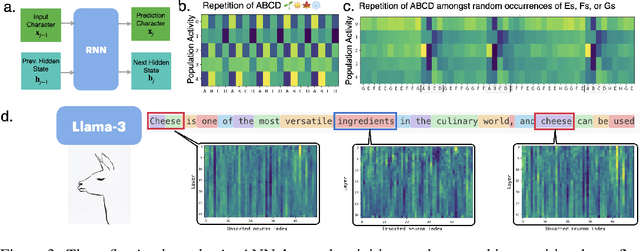
Neural networks are often black boxes, reflecting the significant challenge of understanding their internal workings. We propose a different perspective that challenges the prevailing view: rather than being inscrutable, neural networks exhibit patterns in their raw population activity that mirror regularities in the training data. We refer to this as the Reflection Hypothesis and provide evidence for this phenomenon in both simple recurrent neural networks (RNNs) and complex large language models (LLMs). Building on this insight, we propose to leverage cognitively-inspired methods of chunking to segment high-dimensional neural population dynamics into interpretable units that reflect underlying concepts. We propose three methods to extract these emerging entities, complementing each other based on label availability and dimensionality. Discrete sequence chunking (DSC) creates a dictionary of entities; population averaging (PA) extracts recurring entities that correspond to known labels; and unsupervised chunk discovery (UCD) can be used when labels are absent. We demonstrate the effectiveness of these methods in extracting entities across varying model sizes, ranging from inducing compositionality in RNNs to uncovering recurring neural population states in large models with diverse architectures, and illustrate their advantage over other methods. Throughout, we observe a robust correspondence between the extracted entities and concrete or abstract concepts. Artificially inducing the extracted entities in neural populations effectively alters the network's generation of associated concepts. Our work points to a new direction for interpretability, one that harnesses both cognitive principles and the structure of naturalistic data to reveal the hidden computations of complex learning systems, gradually transforming them from black boxes into systems we can begin to understand.
A Data-Centric Approach: Dimensions of Visual Complexity and How to find Them
Jan 27, 2025


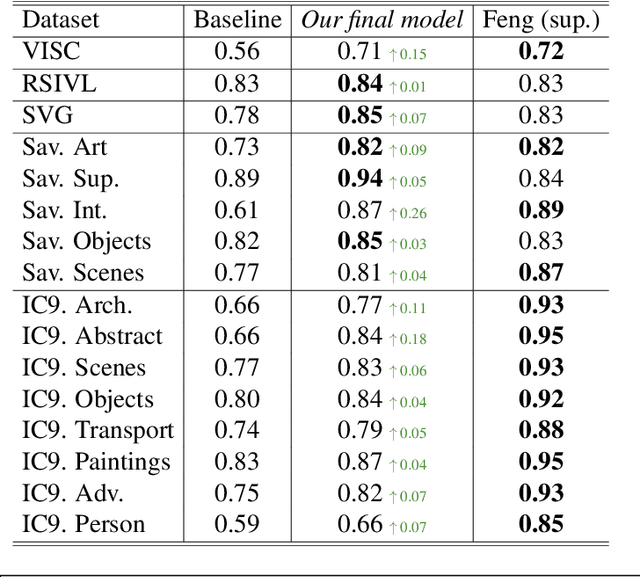
Understanding how humans perceive visual complexity is a key area of study in visual cognition. Previous approaches to modeling visual complexity have often resulted in intricate, difficult-to-interpret solutions that employ numerous features or sophisticated deep learning architectures. While these complex models achieve high performance on specific datasets, they often sacrifice interpretability, making it challenging to understand the factors driving human perception of complexity. A recent model based on image segmentations showed promise in addressing this challenge; however, it presented limitations in capturing structural and semantic aspects of visual complexity. In this paper, we propose viable and effective features to overcome these shortcomings. Specifically, we develop multiscale features for the structural aspect of complexity, including the Multiscale Sobel Gradient (MSG), which captures spatial intensity variations across scales, and Multiscale Unique Colors (MUC), which quantifies image colorfulness by indexing quantized RGB values. We also introduce a new dataset SVG based on Visual Genome to explore the semantic aspect of visual complexity, obtaining surprise scores based on the element of surprise in images, which we demonstrate significantly contributes to perceived complexity. Overall, we suggest that the nature of the data is fundamental to understanding and modeling visual complexity, highlighting the importance of both structural and semantic dimensions in providing a comprehensive, interpretable assessment. The code for our analysis, experimental setup, and dataset will be made publicly available upon acceptance.
Building, Reusing, and Generalizing Abstract Representations from Concrete Sequences
Oct 27, 2024



Humans excel at learning abstract patterns across different sequences, filtering out irrelevant details, and transferring these generalized concepts to new sequences. In contrast, many sequence learning models lack the ability to abstract, which leads to memory inefficiency and poor transfer. We introduce a non-parametric hierarchical variable learning model (HVM) that learns chunks from sequences and abstracts contextually similar chunks as variables. HVM efficiently organizes memory while uncovering abstractions, leading to compact sequence representations. When learning on language datasets such as babyLM, HVM learns a more efficient dictionary than standard compression algorithms such as Lempel-Ziv. In a sequence recall task requiring the acquisition and transfer of variables embedded in sequences, we demonstrate HVM's sequence likelihood correlates with human recall times. In contrast, large language models (LLMs) struggle to transfer abstract variables as effectively as humans. From HVM's adjustable layer of abstraction, we demonstrate that the model realizes a precise trade-off between compression and generalization. Our work offers a cognitive model that captures the learning and transfer of abstract representations in human cognition and differentiates itself from the behavior of large language models.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Next state prediction gives rise to entangled, yet compositional representations of objects
Oct 07, 2024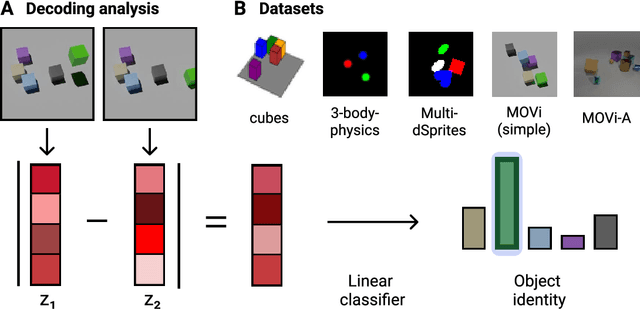
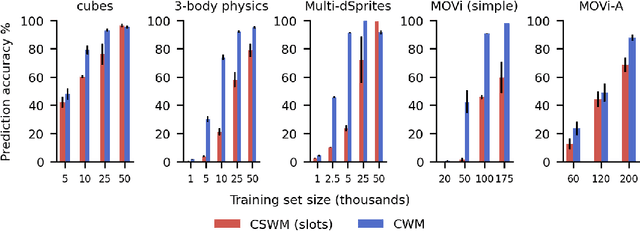

Compositional representations are thought to enable humans to generalize across combinatorially vast state spaces. Models with learnable object slots, which encode information about objects in separate latent codes, have shown promise for this type of generalization but rely on strong architectural priors. Models with distributed representations, on the other hand, use overlapping, potentially entangled neural codes, and their ability to support compositional generalization remains underexplored. In this paper we examine whether distributed models can develop linearly separable representations of objects, like slotted models, through unsupervised training on videos of object interactions. We show that, surprisingly, models with distributed representations often match or outperform models with object slots in downstream prediction tasks. Furthermore, we find that linearly separable object representations can emerge without object-centric priors, with auxiliary objectives like next-state prediction playing a key role. Finally, we observe that distributed models' object representations are never fully disentangled, even if they are linearly separable: Multiple objects can be encoded through partially overlapping neural populations while still being highly separable with a linear classifier. We hypothesize that maintaining partially shared codes enables distributed models to better compress object dynamics, potentially enhancing generalization.
Characterising the Creative Process in Humans and Large Language Models
May 01, 2024


Large language models appear quite creative, often performing on par with the average human on creative tasks. However, research on LLM creativity has focused solely on \textit{products}, with little attention on the creative \textit{process}. Process analyses of human creativity often require hand-coded categories or exploit response times, which do not apply to LLMs. We provide an automated method to characterise how humans and LLMs explore semantic spaces on the Alternate Uses Task, and contrast with behaviour in a Verbal Fluency Task. We use sentence embeddings to identify response categories and compute semantic similarities, which we use to generate jump profiles. Our results corroborate earlier work in humans reporting both persistent (deep search in few semantic spaces) and flexible (broad search across multiple semantic spaces) pathways to creativity, where both pathways lead to similar creativity scores. LLMs were found to be biased towards either persistent or flexible paths, that varied across tasks. Though LLMs as a population match human profiles, their relationship with creativity is different, where the more flexible models score higher on creativity. Our dataset and scripts are available on \href{https://github.com/surabhisnath/Creative_Process}{GitHub}.
Simplicity in Complexity
Mar 05, 2024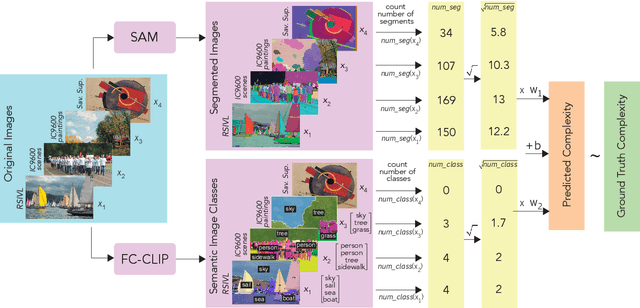
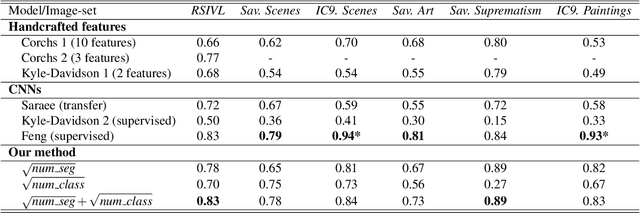
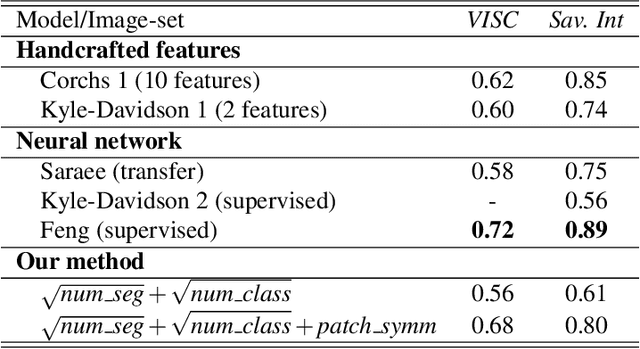

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
Predicting the Future with Simple World Models
Jan 31, 2024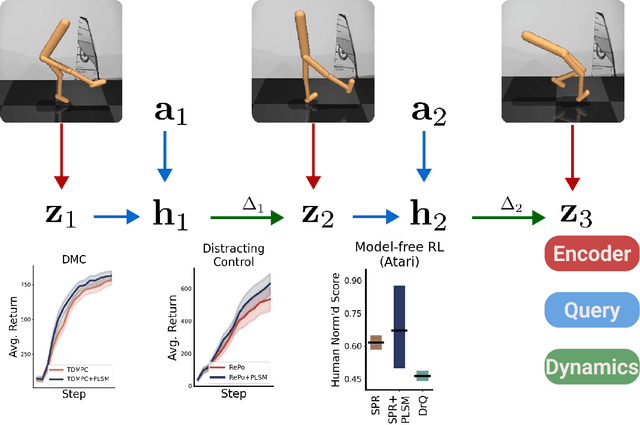
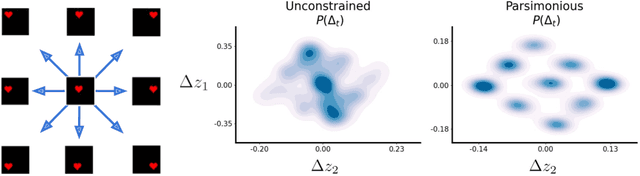
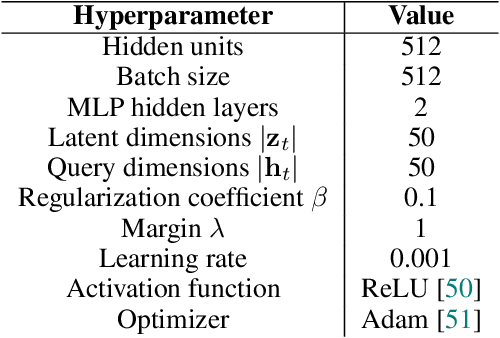
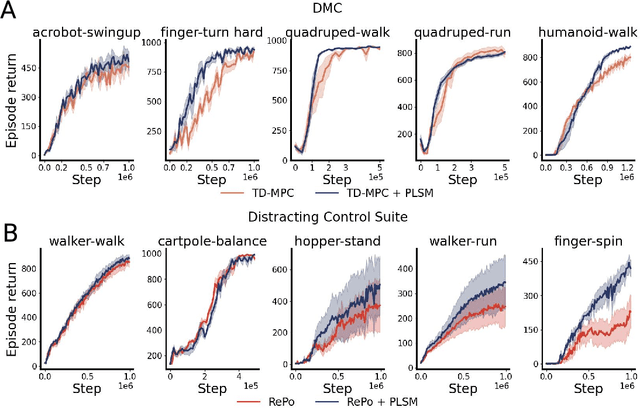
World models can represent potentially high-dimensional pixel observations in compact latent spaces, making it tractable to model the dynamics of the environment. However, the latent dynamics inferred by these models may still be highly complex. Abstracting the dynamics of the environment with simple models can have several benefits. If the latent dynamics are simple, the model may generalize better to novel transitions, and discover useful latent representations of environment states. We propose a regularization scheme that simplifies the world model's latent dynamics. Our model, the Parsimonious Latent Space Model (PLSM), minimizes the mutual information between latent states and the dynamics that arise between them. This makes the dynamics softly state-invariant, and the effects of the agent's actions more predictable. We combine the PLSM with three different model classes used for i) future latent state prediction, ii) video prediction, and iii) planning. We find that our regularization improves accuracy, generalization, and performance in downstream tasks.
The Inner Sentiments of a Thought
Jul 04, 2023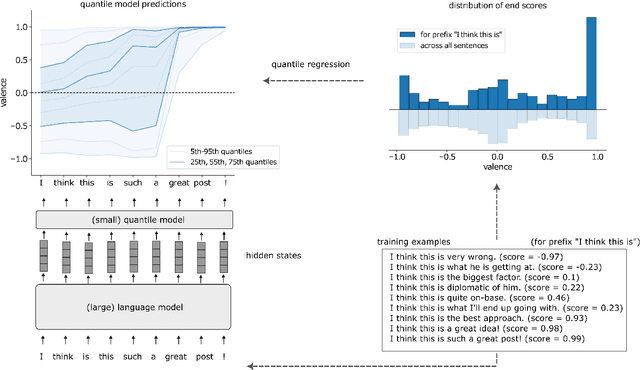
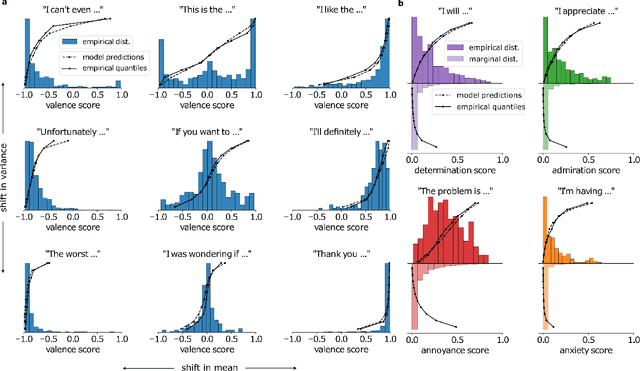
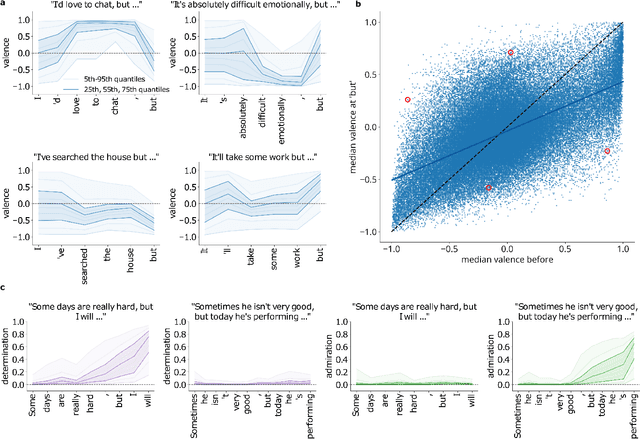
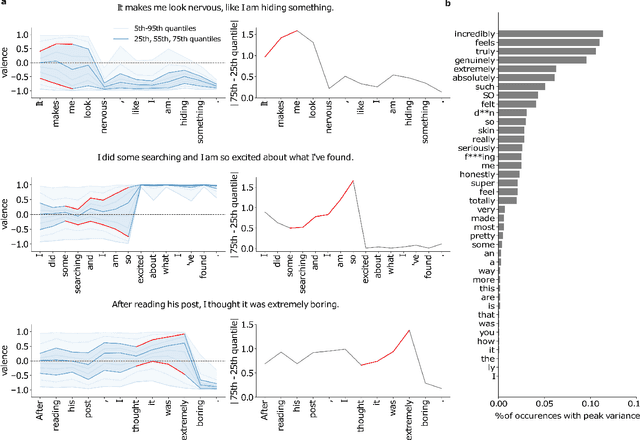
Transformer-based large-scale language models (LLMs) are able to generate highly realistic text. They are duly able to express, and at least implicitly represent, a wide range of sentiments and color, from the obvious, such as valence and arousal to the subtle, such as determination and admiration. We provide a first exploration of these representations and how they can be used for understanding the inner sentimental workings of single sentences. We train predictors of the quantiles of the distributions of final sentiments of sentences from the hidden representations of an LLM applied to prefixes of increasing lengths. After showing that predictors of distributions of valence, determination, admiration, anxiety and annoyance are well calibrated, we provide examples of using these predictors for analyzing sentences, illustrating, for instance, how even ordinary conjunctions (e.g., "but") can dramatically alter the emotional trajectory of an utterance. We then show how to exploit the distributional predictions to generate sentences with sentiments in the tails of distributions. We discuss the implications of our results for the inner workings of thoughts, for instance for psychiatric dysfunction.