 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Characterising the Creative Process in Humans and Large Language Models
May 01, 2024


Large language models appear quite creative, often performing on par with the average human on creative tasks. However, research on LLM creativity has focused solely on \textit{products}, with little attention on the creative \textit{process}. Process analyses of human creativity often require hand-coded categories or exploit response times, which do not apply to LLMs. We provide an automated method to characterise how humans and LLMs explore semantic spaces on the Alternate Uses Task, and contrast with behaviour in a Verbal Fluency Task. We use sentence embeddings to identify response categories and compute semantic similarities, which we use to generate jump profiles. Our results corroborate earlier work in humans reporting both persistent (deep search in few semantic spaces) and flexible (broad search across multiple semantic spaces) pathways to creativity, where both pathways lead to similar creativity scores. LLMs were found to be biased towards either persistent or flexible paths, that varied across tasks. Though LLMs as a population match human profiles, their relationship with creativity is different, where the more flexible models score higher on creativity. Our dataset and scripts are available on \href{https://github.com/surabhisnath/Creative_Process}{GitHub}.
It's LeVAsa not LevioSA! Latent Encodings for Valence-Arousal Structure Alignment
Jul 20, 2020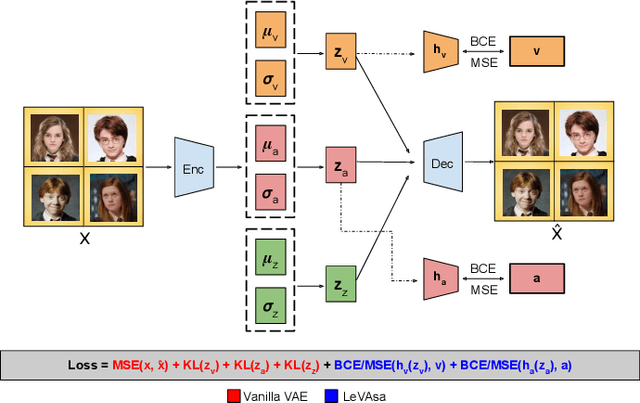
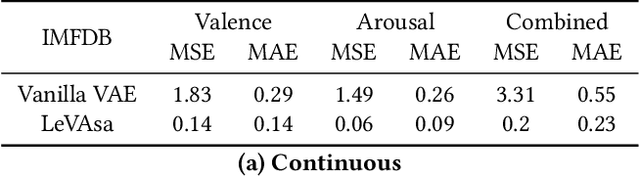

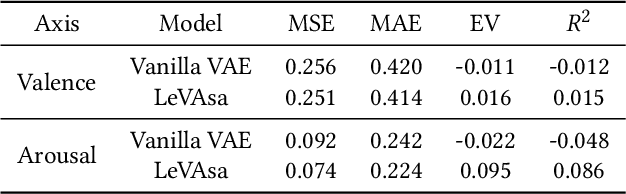
In recent years, great strides have been made in the field of affective computing. Several models have been developed to represent and quantify emotions. Two popular ones include (i) categorical models which represent emotions as discrete labels, and (ii) dimensional models which represent emotions in a Valence-Arousal (VA) circumplex domain. However, there is no standard for annotation mapping between the two labelling methods. We build a novel algorithm for mapping categorical and dimensional model labels using annotation transfer across affective facial image datasets. Further, we utilize the transferred annotations to learn rich and interpretable data representations using a variational autoencoder (VAE). We present "LeVAsa", a VAE model that learns implicit structure by aligning the latent space with the VA space. We evaluate the efficacy of LeVAsa by comparing performance with the Vanilla VAE using quantitative and qualitative analysis on two benchmark affective image datasets. Our results reveal that LeVAsa achieves high latent-circumplex alignment which leads to improved downstream categorical emotion prediction. The work also demonstrates the trade-off between degree of alignment and quality of reconstructions.