 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Good CREPE needs more than just Sugar: Investigating Biases in Compositional Vision-Language Benchmarks
Jun 09, 2025



We investigate 17 benchmarks (e.g. SugarCREPE, VALSE) commonly used for measuring compositional understanding capabilities of vision-language models (VLMs). We scrutinize design choices in their construction, including data source (e.g. MS-COCO) and curation procedures (e.g. constructing negative images/captions), uncovering several inherent biases across most benchmarks. We find that blind heuristics (e.g. token-length, log-likelihood under a language model) perform on par with CLIP models, indicating that these benchmarks do not effectively measure compositional understanding. We demonstrate that the underlying factor is a distribution asymmetry between positive and negative images/captions, induced by the benchmark construction procedures. To mitigate these issues, we provide a few key recommendations for constructing more robust vision-language compositional understanding benchmarks, that would be less prone to such simple attacks.
A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility
Apr 09, 2025Reasoning has emerged as the next major frontier for language models (LMs), with rapid advances from both academic and industrial labs. However, this progress often outpaces methodological rigor, with many evaluations relying on benchmarking practices that lack transparency, robustness, or statistical grounding. In this work, we conduct a comprehensive empirical study and find that current mathematical reasoning benchmarks are highly sensitive to subtle implementation choices - including decoding parameters, random seeds, prompt formatting, and even hardware and software-framework configurations. Performance gains reported in recent studies frequently hinge on unclear comparisons or unreported sources of variance. To address these issues, we propose a standardized evaluation framework with clearly defined best practices and reporting standards. Using this framework, we reassess recent methods and find that reinforcement learning (RL) approaches yield only modest improvements - far below prior claims - and are prone to overfitting, especially on small-scale benchmarks like AIME24. In contrast, supervised finetuning (SFT) methods show consistently stronger generalization. To foster reproducibility, we release all code, prompts, and model outputs, for reasoning benchmarks, establishing more rigorous foundations for future work.
ONEBench to Test Them All: Sample-Level Benchmarking Over Open-Ended Capabilities
Dec 09, 2024



Traditional fixed test sets fall short in evaluating open-ended capabilities of foundation models. To address this, we propose ONEBench(OpeN-Ended Benchmarking), a new testing paradigm that consolidates individual evaluation datasets into a unified, ever-expanding sample pool. ONEBench allows users to generate custom, open-ended evaluation benchmarks from this pool, corresponding to specific capabilities of interest. By aggregating samples across test sets, ONEBench enables the assessment of diverse capabilities beyond those covered by the original test sets, while mitigating overfitting and dataset bias. Most importantly, it frames model evaluation as a collective process of selecting and aggregating sample-level tests. The shift from task-specific benchmarks to ONEBench introduces two challenges: (1)heterogeneity and (2)incompleteness. Heterogeneity refers to the aggregation over diverse metrics, while incompleteness describes comparing models evaluated on different data subsets. To address these challenges, we explore algorithms to aggregate sparse measurements into reliable model scores. Our aggregation algorithm ensures identifiability(asymptotically recovering ground-truth scores) and rapid convergence, enabling accurate model ranking with less data. On homogenous datasets, we show our aggregation algorithm provides rankings that highly correlate with those produced by average scores. We also demonstrate robustness to ~95% of measurements missing, reducing evaluation cost by up to 20x with little-to-no change in model rankings. We introduce ONEBench-LLM for language models and ONEBench-LMM for vision-language models, unifying evaluations across these domains. Overall, we present a technique for open-ended evaluation, which can aggregate over incomplete, heterogeneous sample-level measurements to continually grow a benchmark alongside the rapidly developing foundation models.
How to Merge Your Multimodal Models Over Time?
Dec 09, 2024



Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches assume that all experts are available simultaneously. In reality, new tasks and domains emerge progressively over time, requiring strategies to integrate the knowledge of expert models as they become available: a process we call temporal model merging. The temporal dimension introduces unique challenges not addressed in prior work, raising new questions such as: when training for a new task, should the expert model start from the merged past experts or from the original base model? Should we merge all models at each time step? Which merging techniques are best suited for temporal merging? Should different strategies be used to initialize the training and deploy the model? To answer these questions, we propose a unified framework called TIME - Temporal Integration of Model Expertise - which defines temporal model merging across three axes: (1) Initialization Phase, (2) Deployment Phase, and (3) Merging Technique. Using TIME, we study temporal model merging across model sizes, compute budgets, and learning horizons on the FoMo-in-Flux benchmark. Our comprehensive suite of experiments across TIME allows us to uncover key insights for temporal model merging, offering a better understanding of current challenges and best practices for effective temporal model merging.
Active Data Curation Effectively Distills Large-Scale Multimodal Models
Nov 27, 2024Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective functions, teacher-ensembles, and weight inheritance. In this work we explore an alternative, yet simple approach -- active data curation as effective distillation for contrastive multimodal pretraining. Our simple online batch selection method, ACID, outperforms strong KD baselines across various model-, data- and compute-configurations. Further, we find such an active data curation strategy to in fact be complementary to standard KD, and can be effectively combined to train highly performant inference-efficient models. Our simple and scalable pretraining framework, ACED, achieves state-of-the-art results across 27 zero-shot classification and retrieval tasks with upto 11% less inference FLOPs. We further demonstrate that our ACED models yield strong vision-encoders for training generative multimodal models in the LiT-Decoder setting, outperforming larger vision encoders for image-captioning and visual question-answering tasks.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
A Practitioner's Guide to Continual Multimodal Pretraining
Aug 26, 2024Multimodal foundation models serve numerous applications at the intersection of vision and language. Still, despite being pretrained on extensive data, they become outdated over time. To keep models updated, research into continual pretraining mainly explores scenarios with either (1) infrequent, indiscriminate updates on large-scale new data, or (2) frequent, sample-level updates. However, practical model deployment often operates in the gap between these two limit cases, as real-world applications often demand adaptation to specific subdomains, tasks or concepts -- spread over the entire, varying life cycle of a model. In this work, we complement current perspectives on continual pretraining through a research test bed as well as provide comprehensive guidance for effective continual model updates in such scenarios. We first introduce FoMo-in-Flux, a continual multimodal pretraining benchmark with realistic compute constraints and practical deployment requirements, constructed over 63 datasets with diverse visual and semantic coverage. Using FoMo-in-Flux, we explore the complex landscape of practical continual pretraining through multiple perspectives: (1) A data-centric investigation of data mixtures and stream orderings that emulate real-world deployment situations, (2) a method-centric investigation ranging from simple fine-tuning and traditional continual learning strategies to parameter-efficient updates and model merging, (3) meta learning rate schedules and mechanistic design choices, and (4) the influence of model and compute scaling. Together, our insights provide a practitioner's guide to continual multimodal pretraining for real-world deployment. Our benchmark and code is here: https://github.com/ExplainableML/fomo_in_flux.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024
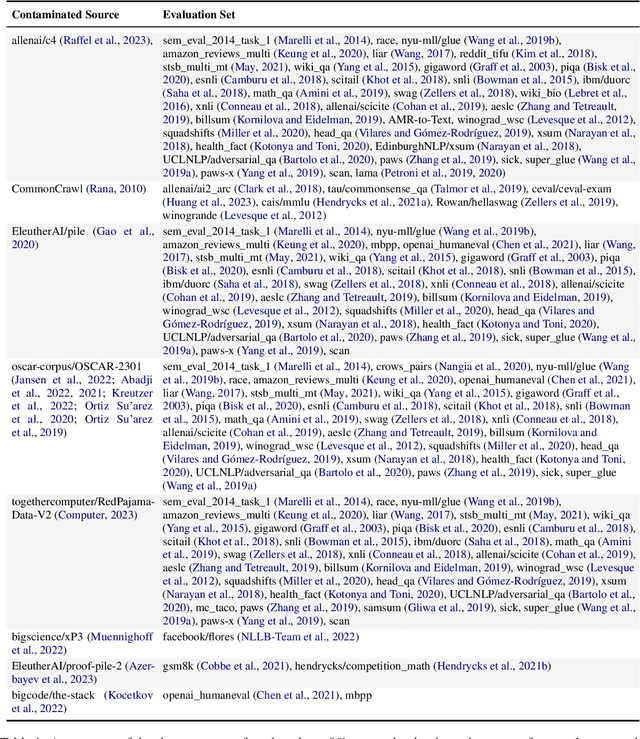
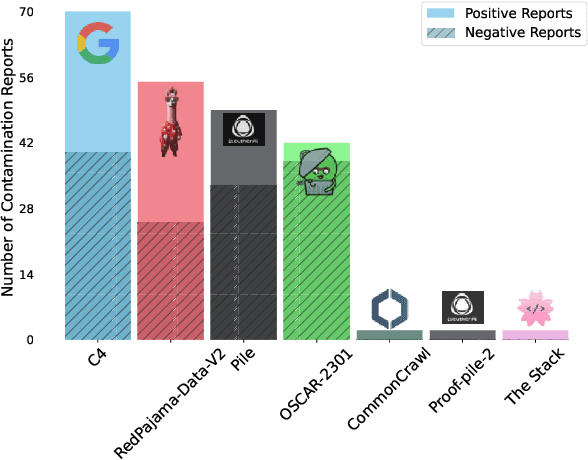
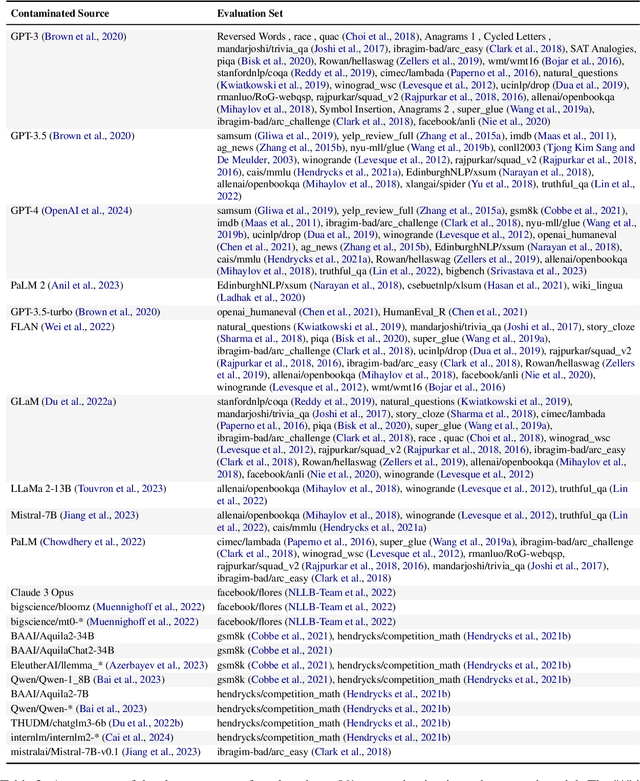
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Apr 08, 2024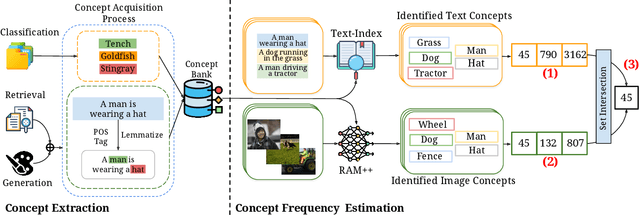


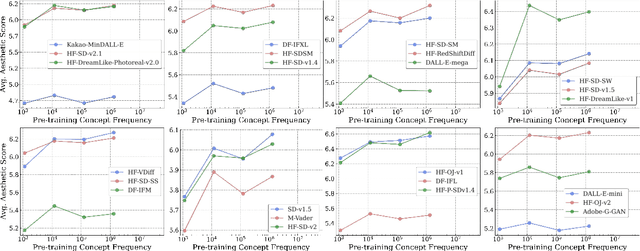
Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets? We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the "Let it Wag!" benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training paradigms remains to be found.
Lifelong Benchmarks: Efficient Model Evaluation in an Era of Rapid Progress
Feb 29, 2024



Standardized benchmarks drive progress in machine learning. However, with repeated testing, the risk of overfitting grows as algorithms over-exploit benchmark idiosyncrasies. In our work, we seek to mitigate this challenge by compiling ever-expanding large-scale benchmarks called Lifelong Benchmarks. As exemplars of our approach, we create Lifelong-CIFAR10 and Lifelong-ImageNet, containing (for now) 1.69M and 1.98M test samples, respectively. While reducing overfitting, lifelong benchmarks introduce a key challenge: the high cost of evaluating a growing number of models across an ever-expanding sample set. To address this challenge, we also introduce an efficient evaluation framework: Sort \& Search (S&S), which reuses previously evaluated models by leveraging dynamic programming algorithms to selectively rank and sub-select test samples, enabling cost-effective lifelong benchmarking. Extensive empirical evaluations across 31,000 models demonstrate that S&S achieves highly-efficient approximate accuracy measurement, reducing compute cost from 180 GPU days to 5 GPU hours (1000x reduction) on a single A100 GPU, with low approximation error. As such, lifelong benchmarks offer a robust, practical solution to the "benchmark exhaustion" problem.