 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Video Masked Autoencoders
Dec 15, 2025We present Recurrent Video Masked-Autoencoders (RVM): a novel video representation learning approach that uses a transformer-based recurrent neural network to aggregate dense image features over time, effectively capturing the spatio-temporal structure of natural video data. RVM learns via an asymmetric masked prediction task requiring only a standard pixel reconstruction objective. This design yields a highly efficient ``generalist'' encoder: RVM achieves competitive performance with state-of-the-art video models (e.g. VideoMAE, V-JEPA) on video-level tasks like action recognition and point/object tracking, while also performing favorably against image models (e.g. DINOv2) on tasks that test geometric and dense spatial understanding. Notably, RVM achieves strong performance in the small-model regime without requiring knowledge distillation, exhibiting up to 30x greater parameter efficiency than competing video masked autoencoders. Moreover, we demonstrate that RVM's recurrent nature allows for stable feature propagation over long temporal horizons with linear computational cost, overcoming some of the limitations of standard spatio-temporal attention-based architectures. Finally, we use qualitative visualizations to highlight that RVM learns rich representations of scene semantics, structure, and motion.
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025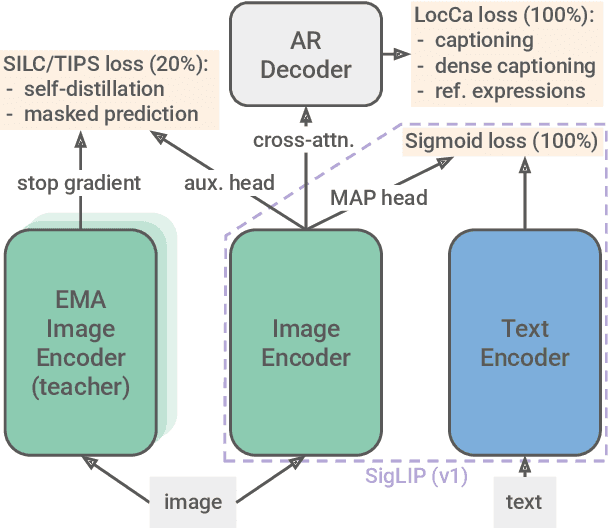
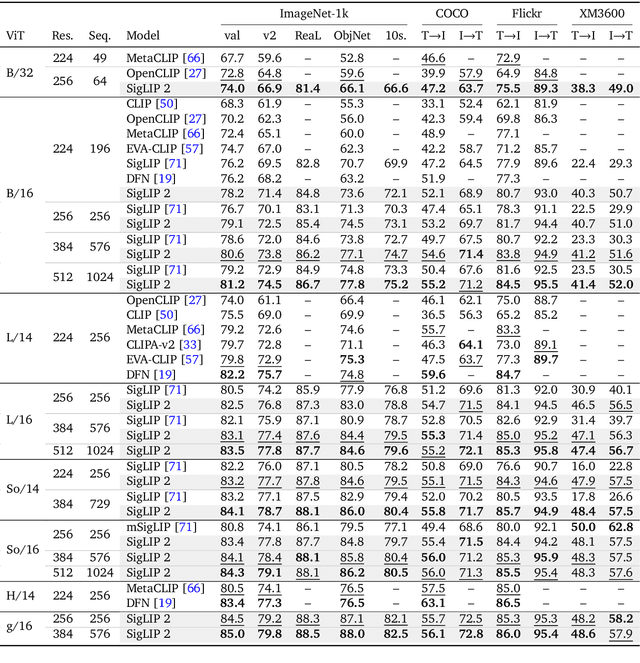
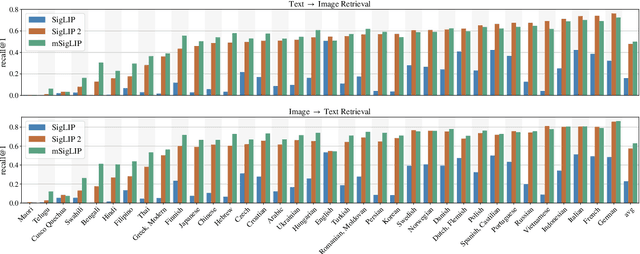
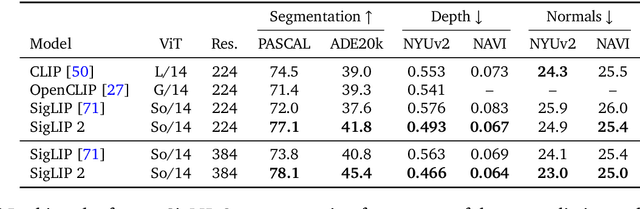
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
Active Data Curation Effectively Distills Large-Scale Multimodal Models
Nov 27, 2024Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective functions, teacher-ensembles, and weight inheritance. In this work we explore an alternative, yet simple approach -- active data curation as effective distillation for contrastive multimodal pretraining. Our simple online batch selection method, ACID, outperforms strong KD baselines across various model-, data- and compute-configurations. Further, we find such an active data curation strategy to in fact be complementary to standard KD, and can be effectively combined to train highly performant inference-efficient models. Our simple and scalable pretraining framework, ACED, achieves state-of-the-art results across 27 zero-shot classification and retrieval tasks with upto 11% less inference FLOPs. We further demonstrate that our ACED models yield strong vision-encoders for training generative multimodal models in the LiT-Decoder setting, outperforming larger vision encoders for image-captioning and visual question-answering tasks.
Data curation via joint example selection further accelerates multimodal learning
Jun 25, 2024



Data curation is an essential component of large-scale pretraining. In this work, we demonstrate that jointly selecting batches of data is more effective for learning than selecting examples independently. Multimodal contrastive objectives expose the dependencies between data and thus naturally yield criteria for measuring the joint learnability of a batch. We derive a simple and tractable algorithm for selecting such batches, which significantly accelerate training beyond individually-prioritized data points. As performance improves by selecting from larger super-batches, we also leverage recent advances in model approximation to reduce the associated computational overhead. As a result, our approach--multimodal contrastive learning with joint example selection (JEST)--surpasses state-of-the-art models with up to 13$\times$ fewer iterations and 10$\times$ less computation. Essential to the performance of JEST is the ability to steer the data selection process towards the distribution of smaller, well-curated datasets via pretrained reference models, exposing the level of data curation as a new dimension for neural scaling laws.
Probing Biological and Artificial Neural Networks with Task-dependent Neural Manifolds
Dec 21, 2023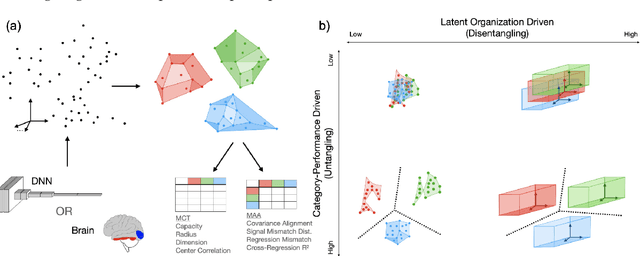
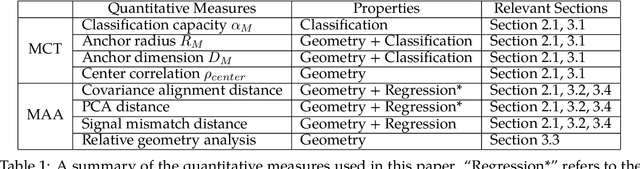
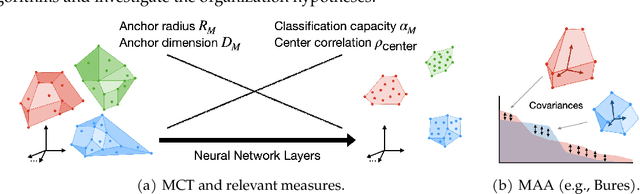

Recently, growth in our understanding of the computations performed in both biological and artificial neural networks has largely been driven by either low-level mechanistic studies or global normative approaches. However, concrete methodologies for bridging the gap between these levels of abstraction remain elusive. In this work, we investigate the internal mechanisms of neural networks through the lens of neural population geometry, aiming to provide understanding at an intermediate level of abstraction, as a way to bridge that gap. Utilizing manifold capacity theory (MCT) from statistical physics and manifold alignment analysis (MAA) from high-dimensional statistics, we probe the underlying organization of task-dependent manifolds in deep neural networks and macaque neural recordings. Specifically, we quantitatively characterize how different learning objectives lead to differences in the organizational strategies of these models and demonstrate how these geometric analyses are connected to the decodability of task-relevant information. These analyses present a strong direction for bridging mechanistic and normative theories in neural networks through neural population geometry, potentially opening up many future research avenues in both machine learning and neuroscience.
Layerwise complexity-matched learning yields an improved model of cortical area V2
Dec 18, 2023Human ability to recognize complex visual patterns arises through transformations performed by successive areas in the ventral visual cortex. Deep neural networks trained end-to-end for object recognition approach human capabilities, and offer the best descriptions to date of neural responses in the late stages of the hierarchy. But these networks provide a poor account of the early stages, compared to traditional hand-engineered models, or models optimized for coding efficiency or prediction. Moreover, the gradient backpropagation used in end-to-end learning is generally considered to be biologically implausible. Here, we overcome both of these limitations by developing a bottom-up self-supervised training methodology that operates independently on successive layers. Specifically, we maximize feature similarity between pairs of locally-deformed natural image patches, while decorrelating features across patches sampled from other images. Crucially, the deformation amplitudes are adjusted proportionally to receptive field sizes in each layer, thus matching the task complexity to the capacity at each stage of processing. In comparison with architecture-matched versions of previous models, we demonstrate that our layerwise complexity-matched learning (LCL) formulation produces a two-stage model (LCL-V2) that is better aligned with selectivity properties and neural activity in primate area V2. We demonstrate that the complexity-matched learning paradigm is critical for the emergence of the improved biological alignment. Finally, when the two-stage model is used as a fixed front-end for a deep network trained to perform object recognition, the resultant model (LCL-V2Net) is significantly better than standard end-to-end self-supervised, supervised, and adversarially-trained models in terms of generalization to out-of-distribution tasks and alignment with human behavior.
Towards In-context Scene Understanding
Jun 02, 2023In-context learning$\unicode{x2013}$the ability to configure a model's behavior with different prompts$\unicode{x2013}$has revolutionized the field of natural language processing, alleviating the need for task-specific models and paving the way for generalist models capable of assisting with any query. Computer vision, in contrast, has largely stayed in the former regime: specialized decoders and finetuning protocols are generally required to perform dense tasks such as semantic segmentation and depth estimation. In this work we explore a simple mechanism for in-context learning of such scene understanding tasks: nearest neighbor retrieval from a prompt of annotated features. We propose a new pretraining protocol$\unicode{x2013}$leveraging attention within and across images$\unicode{x2013}$which yields representations particularly useful in this regime. The resulting Hummingbird model, suitably prompted, performs various scene understanding tasks without modification while approaching the performance of specialists that have been finetuned for each task. Moreover, Hummingbird can be configured to perform new tasks much more efficiently than finetuned models, raising the possibility of scene understanding in the interactive assistant regime.
Self-supervised video pretraining yields strong image representations
Oct 12, 2022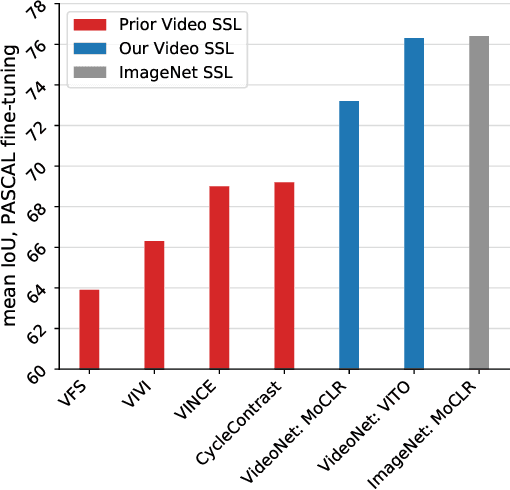
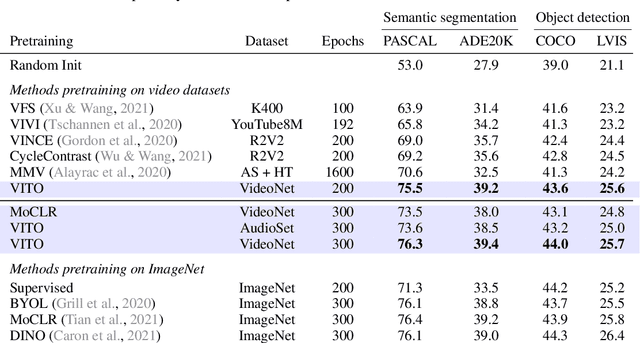
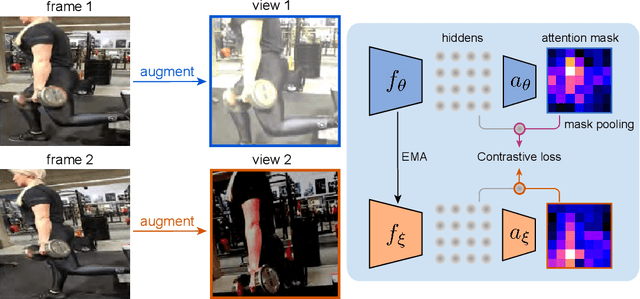
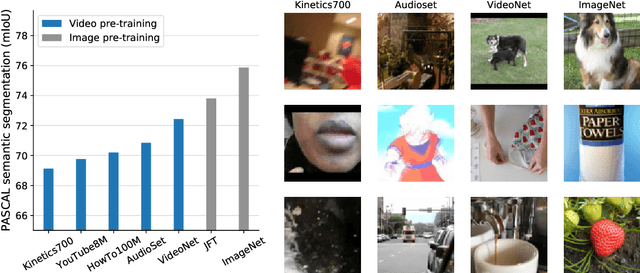
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.
Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022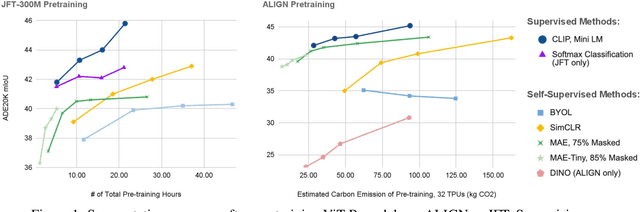
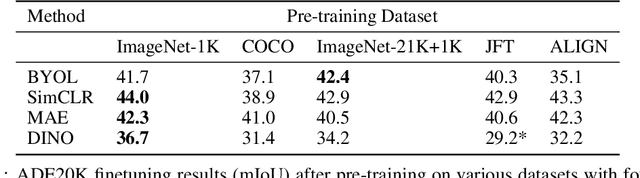
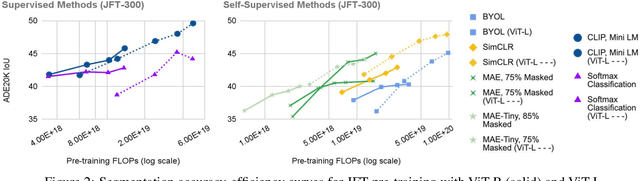
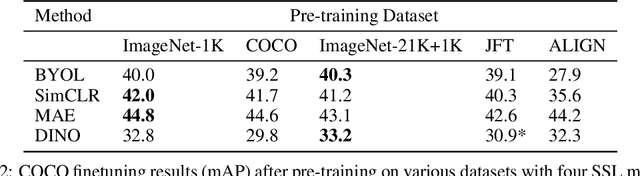
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.
Self-Supervised Learning of a Biologically-Inspired Visual Texture Model
Jun 30, 2020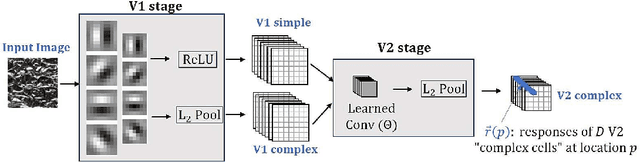


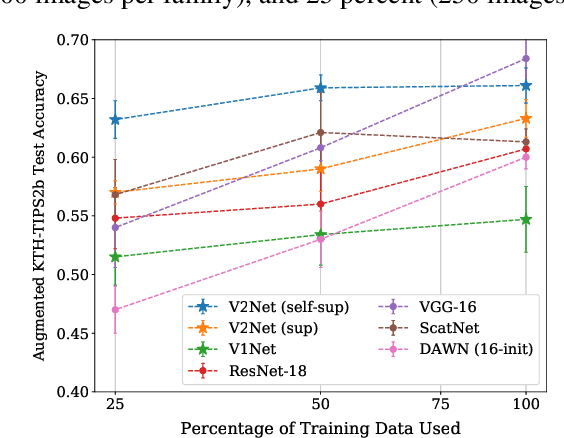
We develop a model for representing visual texture in a low-dimensional feature space, along with a novel self-supervised learning objective that is used to train it on an unlabeled database of texture images. Inspired by the architecture of primate visual cortex, the model uses a first stage of oriented linear filters (corresponding to cortical area V1), consisting of both rectified units (simple cells) and pooled phase-invariant units (complex cells). These responses are processed by a second stage (analogous to cortical area V2) consisting of convolutional filters followed by half-wave rectification and pooling to generate V2 'complex cell' responses. The second stage filters are trained on a set of unlabeled homogeneous texture images, using a novel contrastive objective that maximizes the distance between the distribution of V2 responses to individual images and the distribution of responses across all images. When evaluated on texture classification, the trained model achieves substantially greater data-efficiency than a variety of deep hierarchical model architectures. Moreover, we show that the learned model exhibits stronger representational similarity to texture responses of neural populations recorded in primate V2 than pre-trained deep CNNs.