 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional diversity in visual concept learning
May 30, 2023

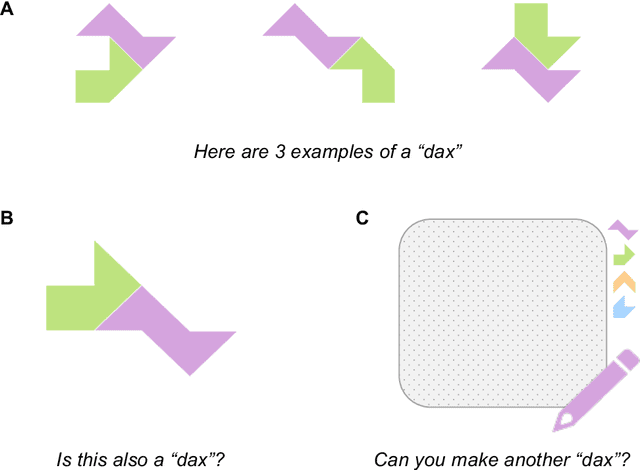

Humans leverage compositionality to efficiently learn new concepts, understanding how familiar parts can combine together to form novel objects. In contrast, popular computer vision models struggle to make the same types of inferences, requiring more data and generalizing less flexibly than people do. Here, we study these distinctively human abilities across a range of different types of visual composition, examining how people classify and generate ``alien figures'' with rich relational structure. We also develop a Bayesian program induction model which searches for the best programs for generating the candidate visual figures, utilizing a large program space containing different compositional mechanisms and abstractions. In few shot classification tasks, we find that people and the program induction model can make a range of meaningful compositional generalizations, with the model providing a strong account of the experimental data as well as interpretable parameters that reveal human assumptions about the factors invariant to category membership (here, to rotation and changing part attachment). In few shot generation tasks, both people and the models are able to construct compelling novel examples, with people behaving in additional structured ways beyond the model capabilities, e.g. making choices that complete a set or reconfiguring existing parts in highly novel ways. To capture these additional behavioral patterns, we develop an alternative model based on neuro-symbolic program induction: this model also composes new concepts from existing parts yet, distinctively, it utilizes neural network modules to successfully capture residual statistical structure. Together, our behavioral and computational findings show how people and models can produce a rich variety of compositional behavior when classifying and generating visual objects.
Learning Task-General Representations with Generative Neuro-Symbolic Modeling
Jun 25, 2020


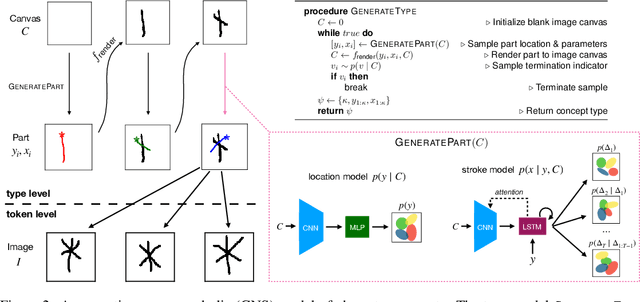
A hallmark of human intelligence is the ability to interact directly with raw data and acquire rich, general-purpose conceptual representations. In machine learning, symbolic models can capture the compositional and causal knowledge that enables flexible generalization, but they struggle to learn from raw inputs, relying on strong abstractions and simplifying assumptions. Neural network models can learn directly from raw data, but they struggle to capture compositional and causal structure and typically must retrain to tackle new tasks. To help bridge this gap, we propose Generative Neuro-Symbolic (GNS) Modeling, a framework for learning task-general representations by combining the structure of symbolic models with the expressivity of neural networks. Concepts and conceptual background knowledge are represented as probabilistic programs with neural network sub-routines, maintaining explicit causal and compositional structure while capturing nonparametric relationships and learning directly from raw data. We apply GNS to the Omniglot challenge of learning simple visual concepts at a human level. We report competitive results on 4 unique tasks including one-shot classification, parsing, generating new exemplars, and generating new concepts. To our knowledge, this is the strongest neurally-grounded model to complete a diverse set of Omniglot tasks.
Generating new concepts with hybrid neuro-symbolic models
Mar 23, 2020

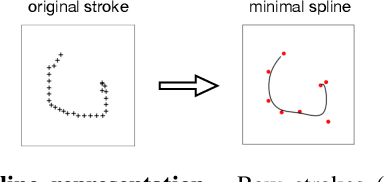
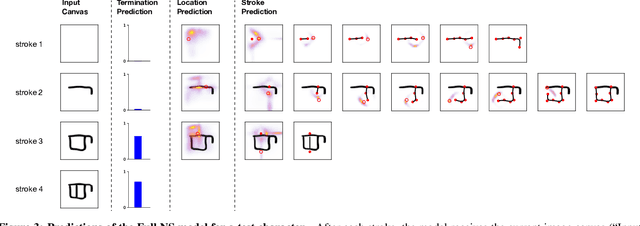
Human conceptual knowledge supports the ability to generate novel yet highly structured concepts, and the form of this conceptual knowledge is of great interest to cognitive scientists. One tradition has emphasized structured knowledge, viewing concepts as embedded in intuitive theories or organized in complex symbolic knowledge structures. A second tradition has emphasized statistical knowledge, viewing conceptual knowledge as an emerging from the rich correlational structure captured by training neural networks and other statistical models. In this paper, we explore a synthesis of these two traditions through a novel neuro-symbolic model for generating new concepts. Using simple visual concepts as a testbed, we bring together neural networks and symbolic probabilistic programs to learn a generative model of novel handwritten characters. Two alternative models are explored with more generic neural network architectures. We compare each of these three models for their likelihoods on held-out character classes and for the quality of their productions, finding that our hybrid model learns the most convincing representation and generalizes further from the training observations.
Robust Nonlinear Component Estimation with Tikhonov Regularization
Jul 18, 2019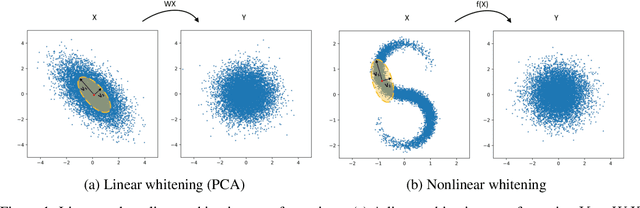
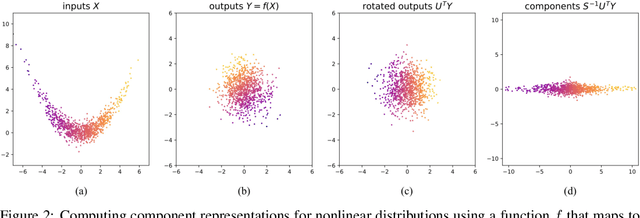
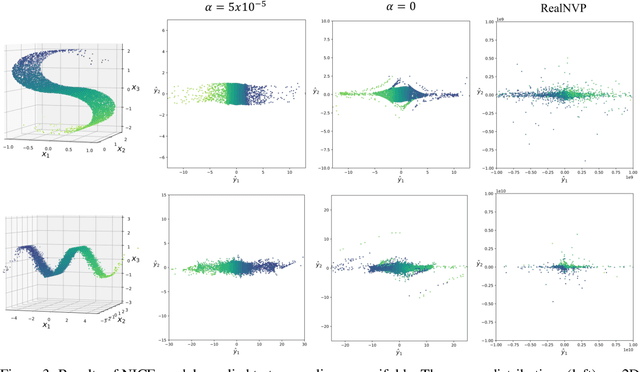
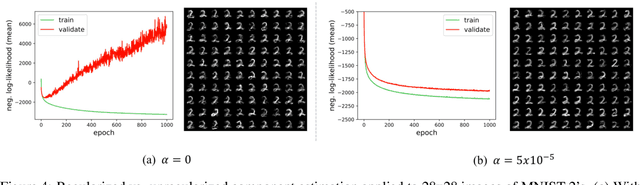
Learning reduced component representations of data using nonlinear transformations is a central problem in unsupervised learning with a rich history. Recently, a new family of algorithms based on maximum likelihood optimization with change of variables has demonstrated an impressive ability to model complex nonlinear data distributions. These algorithms learn to map from arbitrary random variables to independent components using invertible nonlinear function approximators. Despite the potential of this framework, the underlying optimization objective is ill-posed for a large class of variables, inhibiting accurate component estimates in many use cases. We present a new Tikhonov regularization technique for nonlinear independent component estimation that mediates the instability of the algorithm and facilitates robust component estimates. In addition, we provide a theoretically grounded procedure for feature extraction that produces PCA-like representations of nonlinear distributions using the learned model. We apply our technique to a handful of nonlinear data manifolds and show that the resulting representations possess important consistencies lacked by unregularized models.
Learning a smooth kernel regularizer for convolutional neural networks
Mar 05, 2019

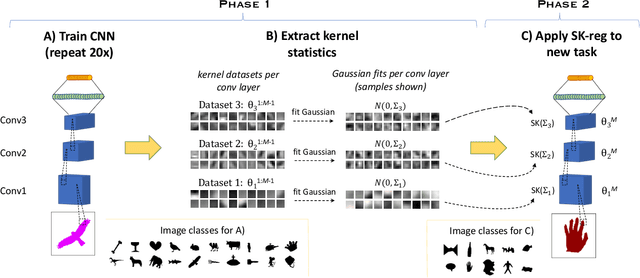

Modern deep neural networks require a tremendous amount of data to train, often needing hundreds or thousands of labeled examples to learn an effective representation. For these networks to work with less data, more structure must be built into their architectures or learned from previous experience. The learned weights of convolutional neural networks (CNNs) trained on large datasets for object recognition contain a substantial amount of structure. These representations have parallels to simple cells in the primary visual cortex, where receptive fields are smooth and contain many regularities. Incorporating smoothness constraints over the kernel weights of modern CNN architectures is a promising way to improve their sample complexity. We propose a smooth kernel regularizer that encourages spatial correlations in convolution kernel weights. The correlation parameters of this regularizer are learned from previous experience, yielding a method with a hierarchical Bayesian interpretation. We show that our correlated regularizer can help constrain models for visual recognition, improving over an L2 regularization baseline.
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.
Learning Inductive Biases with Simple Neural Networks
Jun 13, 2018
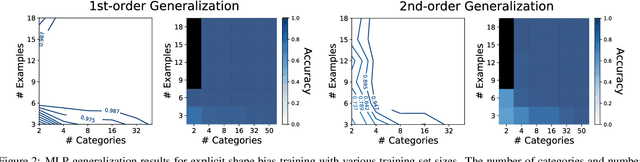
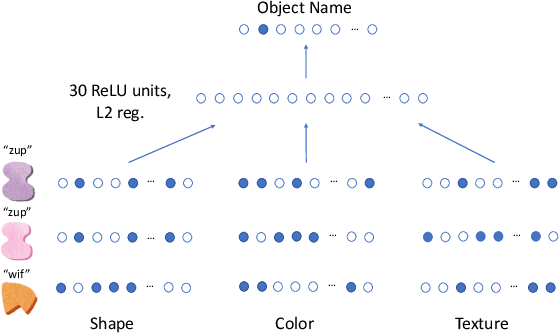
People use rich prior knowledge about the world in order to efficiently learn new concepts. These priors - also known as "inductive biases" - pertain to the space of internal models considered by a learner, and they help the learner make inferences that go beyond the observed data. A recent study found that deep neural networks optimized for object recognition develop the shape bias (Ritter et al., 2017), an inductive bias possessed by children that plays an important role in early word learning. However, these networks use unrealistically large quantities of training data, and the conditions required for these biases to develop are not well understood. Moreover, it is unclear how the learning dynamics of these networks relate to developmental processes in childhood. We investigate the development and influence of the shape bias in neural networks using controlled datasets of abstract patterns and synthetic images, allowing us to systematically vary the quantity and form of the experience provided to the learning algorithms. We find that simple neural networks develop a shape bias after seeing as few as 3 examples of 4 object categories. The development of these biases predicts the onset of vocabulary acceleration in our networks, consistent with the developmental process in children.
* Published in Proceedings of the 40th Annual Meeting of the Cognitive Science Society, July 2018
Detecting Adversarial Samples from Artifacts
Nov 15, 2017


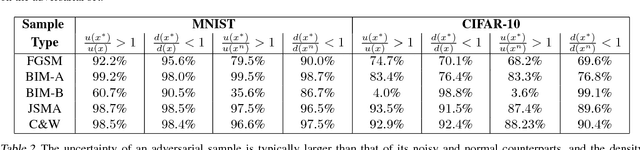
Deep neural networks (DNNs) are powerful nonlinear architectures that are known to be robust to random perturbations of the input. However, these models are vulnerable to adversarial perturbations--small input changes crafted explicitly to fool the model. In this paper, we ask whether a DNN can distinguish adversarial samples from their normal and noisy counterparts. We investigate model confidence on adversarial samples by looking at Bayesian uncertainty estimates, available in dropout neural networks, and by performing density estimation in the subspace of deep features learned by the model. The result is a method for implicit adversarial detection that is oblivious to the attack algorithm. We evaluate this method on a variety of standard datasets including MNIST and CIFAR-10 and show that it generalizes well across different architectures and attacks. Our findings report that 85-93% ROC-AUC can be achieved on a number of standard classification tasks with a negative class that consists of both normal and noisy samples.