 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional diversity in visual concept learning
Paper and Code
May 30, 2023

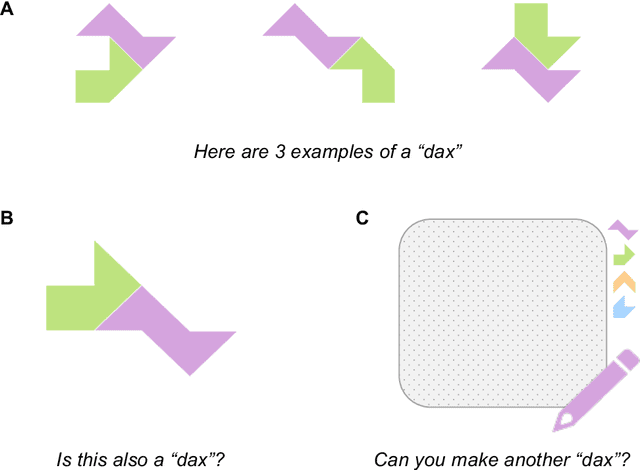

Humans leverage compositionality to efficiently learn new concepts, understanding how familiar parts can combine together to form novel objects. In contrast, popular computer vision models struggle to make the same types of inferences, requiring more data and generalizing less flexibly than people do. Here, we study these distinctively human abilities across a range of different types of visual composition, examining how people classify and generate ``alien figures'' with rich relational structure. We also develop a Bayesian program induction model which searches for the best programs for generating the candidate visual figures, utilizing a large program space containing different compositional mechanisms and abstractions. In few shot classification tasks, we find that people and the program induction model can make a range of meaningful compositional generalizations, with the model providing a strong account of the experimental data as well as interpretable parameters that reveal human assumptions about the factors invariant to category membership (here, to rotation and changing part attachment). In few shot generation tasks, both people and the models are able to construct compelling novel examples, with people behaving in additional structured ways beyond the model capabilities, e.g. making choices that complete a set or reconfiguring existing parts in highly novel ways. To capture these additional behavioral patterns, we develop an alternative model based on neuro-symbolic program induction: this model also composes new concepts from existing parts yet, distinctively, it utilizes neural network modules to successfully capture residual statistical structure. Together, our behavioral and computational findings show how people and models can produce a rich variety of compositional behavior when classifying and generating visual objects.