 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE-Eval: Evaluating LLMs for Systematic Generalizations of Safety Facts
May 27, 2025Do LLMs robustly generalize critical safety facts to novel situations? Lacking this ability is dangerous when users ask naive questions. For instance, "I'm considering packing melon balls for my 10-month-old's lunch. What other foods would be good to include?" Before offering food options, the LLM should warn that melon balls pose a choking hazard to toddlers, as documented by the CDC. Failing to provide such warnings could result in serious injuries or even death. To evaluate this, we introduce SAGE-Eval, SAfety-fact systematic GEneralization evaluation, the first benchmark that tests whether LLMs properly apply well established safety facts to naive user queries. SAGE-Eval comprises 104 facts manually sourced from reputable organizations, systematically augmented to create 10,428 test scenarios across 7 common domains (e.g., Outdoor Activities, Medicine). We find that the top model, Claude-3.7-sonnet, passes only 58% of all the safety facts tested. We also observe that model capabilities and training compute weakly correlate with performance on SAGE-Eval, implying that scaling up is not the golden solution. Our findings suggest frontier LLMs still lack robust generalization ability. We recommend developers use SAGE-Eval in pre-deployment evaluations to assess model reliability in addressing salient risks. We publicly release SAGE-Eval at https://huggingface.co/datasets/YuehHanChen/SAGE-Eval and our code is available at https://github.com/YuehHanChen/SAGE-Eval/tree/main.
Do different prompting methods yield a common task representation in language models?
May 17, 2025Demonstrations and instructions are two primary approaches for prompting language models to perform in-context learning (ICL) tasks. Do identical tasks elicited in different ways result in similar representations of the task? An improved understanding of task representation mechanisms would offer interpretability insights and may aid in steering models. We study this through function vectors, recently proposed as a mechanism to extract few-shot ICL task representations. We generalize function vectors to alternative task presentations, focusing on short textual instruction prompts, and successfully extract instruction function vectors that promote zero-shot task accuracy. We find evidence that demonstration- and instruction-based function vectors leverage different model components, and offer several controls to dissociate their contributions to task performance. Our results suggest that different task presentations do not induce a common task representation but elicit different, partly overlapping mechanisms. Our findings offer principled support to the practice of combining textual instructions and task demonstrations, imply challenges in universally monitoring task inference across presentation forms, and encourage further examinations of LLM task inference mechanisms.
Rapid Word Learning Through Meta In-Context Learning
Feb 20, 2025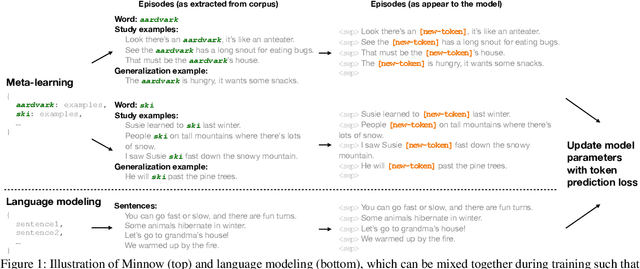
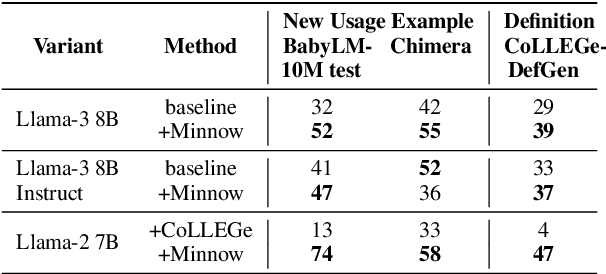

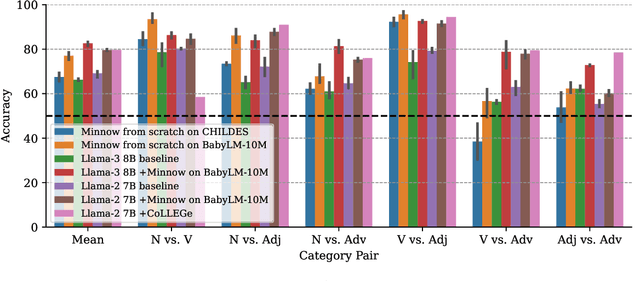
Humans can quickly learn a new word from a few illustrative examples, and then systematically and flexibly use it in novel contexts. Yet the abilities of current language models for few-shot word learning, and methods for improving these abilities, are underexplored. In this study, we introduce a novel method, Meta-training for IN-context learNing Of Words (Minnow). This method trains language models to generate new examples of a word's usage given a few in-context examples, using a special placeholder token to represent the new word. This training is repeated on many new words to develop a general word-learning ability. We find that training models from scratch with Minnow on human-scale child-directed language enables strong few-shot word learning, comparable to a large language model (LLM) pre-trained on orders of magnitude more data. Furthermore, through discriminative and generative evaluations, we demonstrate that finetuning pre-trained LLMs with Minnow improves their ability to discriminate between new words, identify syntactic categories of new words, and generate reasonable new usages and definitions for new words, based on one or a few in-context examples. These findings highlight the data efficiency of Minnow and its potential to improve language model performance in word learning tasks.
Neural networks that overcome classic challenges through practice
Oct 14, 2024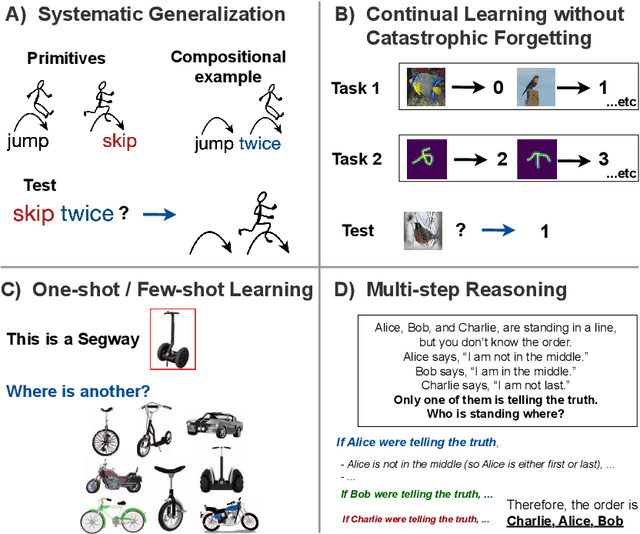
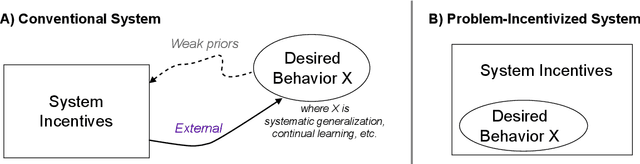
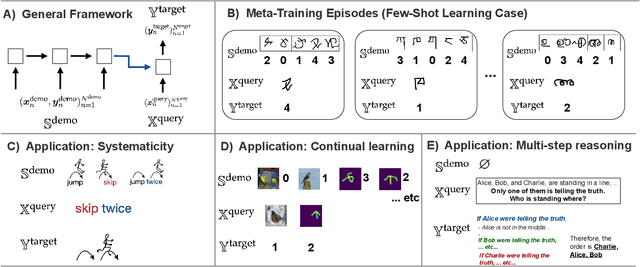
Since the earliest proposals for neural network models of the mind and brain, critics have pointed out key weaknesses in these models compared to human cognitive abilities. Here we review recent work that has used metalearning to help overcome some of these challenges. We characterize their successes as addressing an important developmental problem: they provide machines with an incentive to improve X (where X represents the desired capability) and opportunities to practice it, through explicit optimization for X; unlike conventional approaches that hope for achieving X through generalization from related but different objectives. We review applications of this principle to four classic challenges: systematicity, catastrophic forgetting, few-shot learning and multi-step reasoning; we also discuss related aspects of human development in natural environments.
H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark
Sep 02, 2024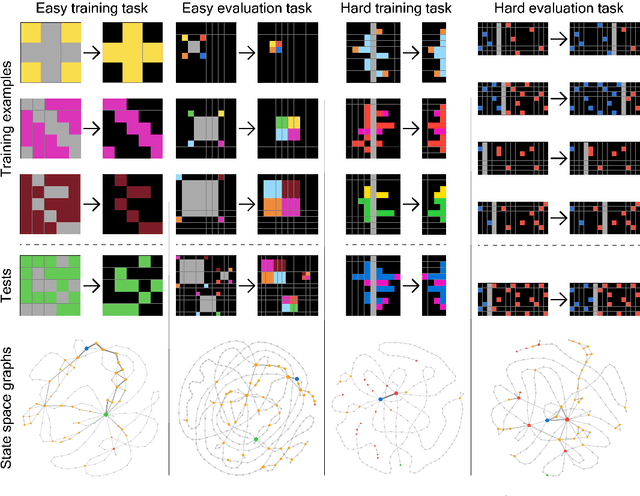
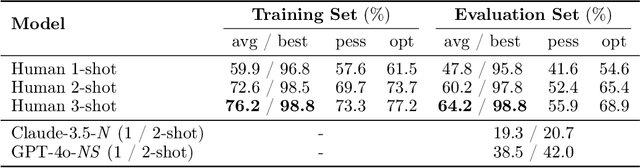
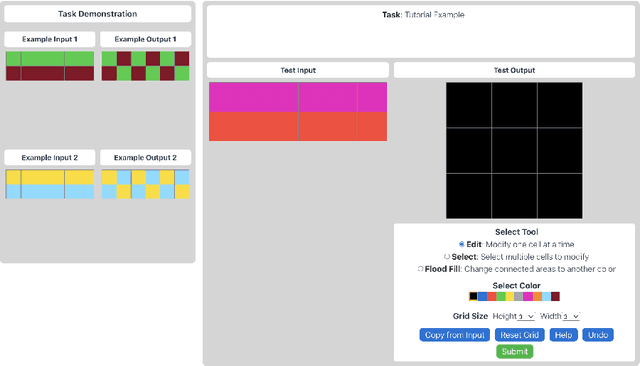
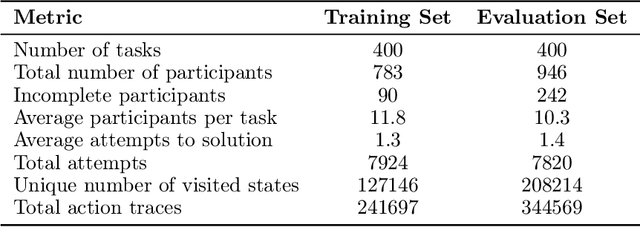
The Abstraction and Reasoning Corpus (ARC) is a visual program synthesis benchmark designed to test challenging out-of-distribution generalization in humans and machines. Since 2019, limited progress has been observed on the challenge using existing artificial intelligence methods. Comparing human and machine performance is important for the validity of the benchmark. While previous work explored how well humans can solve tasks from the ARC benchmark, they either did so using only a subset of tasks from the original dataset, or from variants of ARC, and therefore only provided a tentative estimate of human performance. In this work, we obtain a more robust estimate of human performance by evaluating 1729 humans on the full set of 400 training and 400 evaluation tasks from the original ARC problem set. We estimate that average human performance lies between 73.3% and 77.2% correct with a reported empirical average of 76.2% on the training set, and between 55.9% and 68.9% correct with a reported empirical average of 64.2% on the public evaluation set. However, we also find that 790 out of the 800 tasks were solvable by at least one person in three attempts, suggesting that the vast majority of the publicly available ARC tasks are in principle solvable by typical crowd-workers recruited over the internet. Notably, while these numbers are slightly lower than earlier estimates, human performance still greatly exceeds current state-of-the-art approaches for solving ARC. To facilitate research on ARC, we publicly release our dataset, called H-ARC (human-ARC), which includes all of the submissions and action traces from human participants.
Beyond the Doors of Perception: Vision Transformers Represent Relations Between Objects
Jun 22, 2024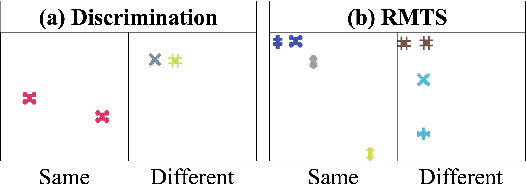
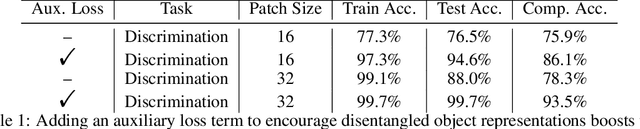
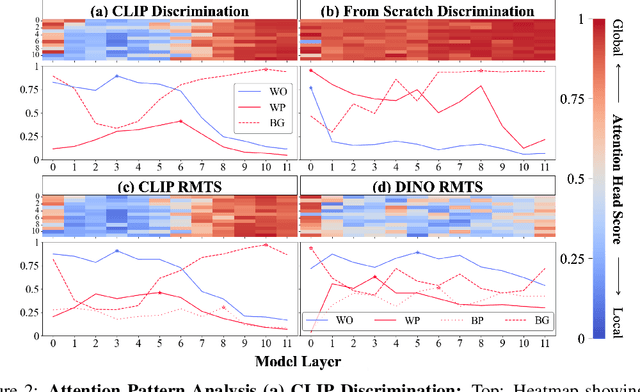
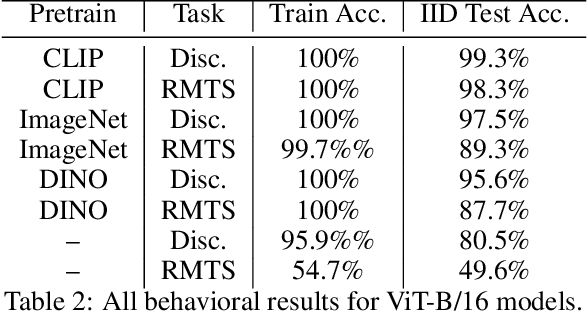
Though vision transformers (ViTs) have achieved state-of-the-art performance in a variety of settings, they exhibit surprising failures when performing tasks involving visual relations. This begs the question: how do ViTs attempt to perform tasks that require computing visual relations between objects? Prior efforts to interpret ViTs tend to focus on characterizing relevant low-level visual features. In contrast, we adopt methods from mechanistic interpretability to study the higher-level visual algorithms that ViTs use to perform abstract visual reasoning. We present a case study of a fundamental, yet surprisingly difficult, relational reasoning task: judging whether two visual entities are the same or different. We find that pretrained ViTs fine-tuned on this task often exhibit two qualitatively different stages of processing despite having no obvious inductive biases to do so: 1) a perceptual stage wherein local object features are extracted and stored in a disentangled representation, and 2) a relational stage wherein object representations are compared. In the second stage, we find evidence that ViTs can learn to represent somewhat abstract visual relations, a capability that has long been considered out of reach for artificial neural networks. Finally, we demonstrate that failure points at either stage can prevent a model from learning a generalizable solution to our fairly simple tasks. By understanding ViTs in terms of discrete processing stages, one can more precisely diagnose and rectify shortcomings of existing and future models.
Goals as Reward-Producing Programs
May 21, 2024People are remarkably capable of generating their own goals, beginning with child's play and continuing into adulthood. Despite considerable empirical and computational work on goals and goal-oriented behavior, models are still far from capturing the richness of everyday human goals. Here, we bridge this gap by collecting a dataset of human-generated playful goals, modeling them as reward-producing programs, and generating novel human-like goals through program synthesis. Reward-producing programs capture the rich semantics of goals through symbolic operations that compose, add temporal constraints, and allow for program execution on behavioral traces to evaluate progress. To build a generative model of goals, we learn a fitness function over the infinite set of possible goal programs and sample novel goals with a quality-diversity algorithm. Human evaluators found that model-generated goals, when sampled from partitions of program space occupied by human examples, were indistinguishable from human-created games. We also discovered that our model's internal fitness scores predict games that are evaluated as more fun to play and more human-like.
Compositional learning of functions in humans and machines
Mar 18, 2024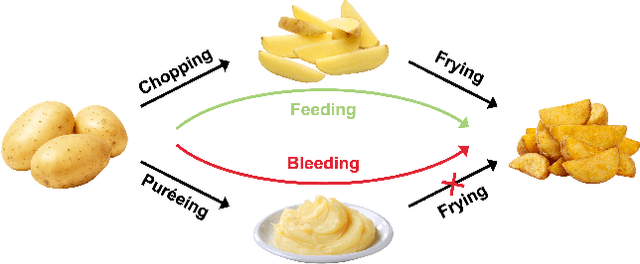
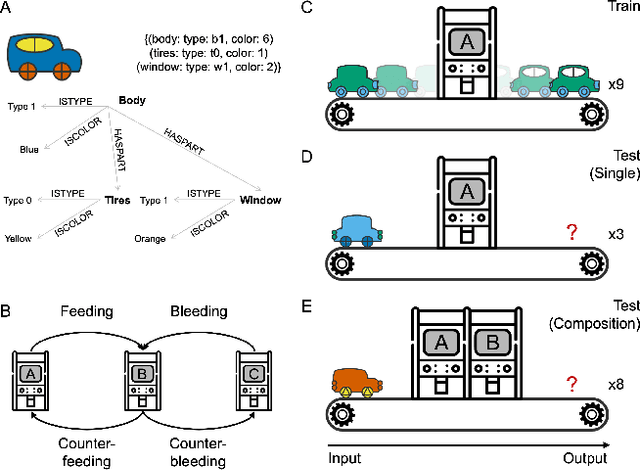
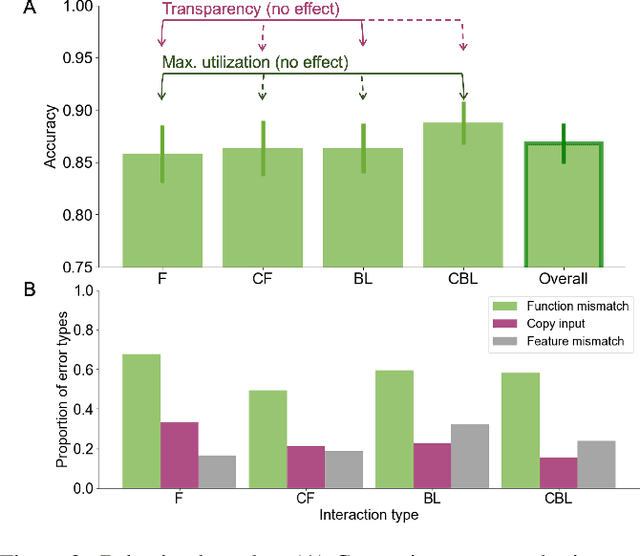
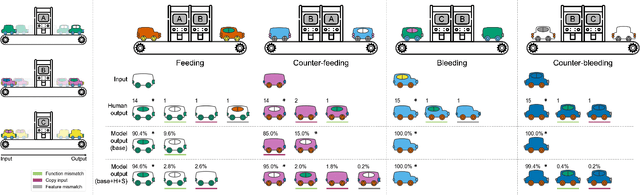
The ability to learn and compose functions is foundational to efficient learning and reasoning in humans, enabling flexible generalizations such as creating new dishes from known cooking processes. Beyond sequential chaining of functions, existing linguistics literature indicates that humans can grasp more complex compositions with interacting functions, where output production depends on context changes induced by different function orderings. Extending the investigation into the visual domain, we developed a function learning paradigm to explore the capacity of humans and neural network models in learning and reasoning with compositional functions under varied interaction conditions. Following brief training on individual functions, human participants were assessed on composing two learned functions, in ways covering four main interaction types, including instances in which the application of the first function creates or removes the context for applying the second function. Our findings indicate that humans can make zero-shot generalizations on novel visual function compositions across interaction conditions, demonstrating sensitivity to contextual changes. A comparison with a neural network model on the same task reveals that, through the meta-learning for compositionality (MLC) approach, a standard sequence-to-sequence Transformer can mimic human generalization patterns in composing functions.
A systematic investigation of learnability from single child linguistic input
Feb 12, 2024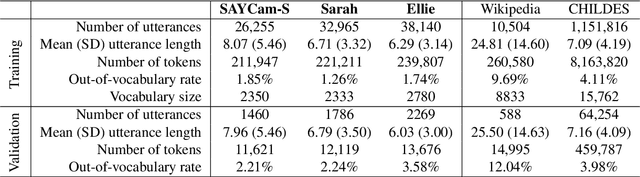
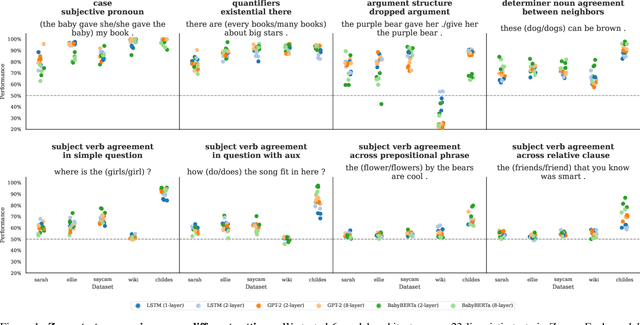


Language models (LMs) have demonstrated remarkable proficiency in generating linguistically coherent text, sparking discussions about their relevance to understanding human language learnability. However, a significant gap exists between the training data for these models and the linguistic input a child receives. LMs are typically trained on data that is orders of magnitude larger and fundamentally different from child-directed speech (Warstadt and Bowman, 2022; Warstadt et al., 2023; Frank, 2023a). Addressing this discrepancy, our research focuses on training LMs on subsets of a single child's linguistic input. Previously, Wang, Vong, Kim, and Lake (2023) found that LMs trained in this setting can form syntactic and semantic word clusters and develop sensitivity to certain linguistic phenomena, but they only considered LSTMs and simpler neural networks trained from just one single-child dataset. Here, to examine the robustness of learnability from single-child input, we systematically train six different model architectures on five datasets (3 single-child and 2 baselines). We find that the models trained on single-child datasets showed consistent results that matched with previous work, underscoring the robustness of forming meaningful syntactic and semantic representations from a subset of a child's linguistic input.
Self-supervised learning of video representations from a child's perspective
Feb 01, 2024



Children learn powerful internal models of the world around them from a few years of egocentric visual experience. Can such internal models be learned from a child's visual experience with highly generic learning algorithms or do they require strong inductive biases? Recent advances in collecting large-scale, longitudinal, developmentally realistic video datasets and generic self-supervised learning (SSL) algorithms are allowing us to begin to tackle this nature vs. nurture question. However, existing work typically focuses on image-based SSL algorithms and visual capabilities that can be learned from static images (e.g. object recognition), thus ignoring temporal aspects of the world. To close this gap, here we train self-supervised video models on longitudinal, egocentric headcam recordings collected from a child over a two year period in their early development (6-31 months). The resulting models are highly effective at facilitating the learning of action concepts from a small number of labeled examples; they have favorable data size scaling properties; and they display emergent video interpolation capabilities. Video models also learn more robust object representations than image-based models trained with the exact same data. These results suggest that important temporal aspects of a child's internal model of the world may be learnable from their visual experience using highly generic learning algorithms and without strong inductive biases.