 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstractions for Hierarchical Planning in Program-Synthesis Agents
Jan 31, 2026Humans learn abstractions and use them to plan efficiently to quickly generalize across tasks -- an ability that remains challenging for state-of-the-art large language model (LLM) agents and deep reinforcement learning (RL) systems. Inspired by the cognitive science of how people form abstractions and intuitive theories of their world knowledge, Theory-Based RL (TBRL) systems, such as TheoryCoder, exhibit strong generalization through effective use of abstractions. However, they heavily rely on human-provided abstractions and sidestep the abstraction-learning problem. We introduce TheoryCoder-2, a new TBRL agent that leverages LLMs' in-context learning ability to actively learn reusable abstractions rather than relying on hand-specified ones, by synthesizing abstractions from experience and integrating them into a hierarchical planning process. We conduct experiments on diverse environments, including BabyAI, Minihack and VGDL games like Sokoban. We find that TheoryCoder-2 is significantly more sample-efficient than baseline LLM agents augmented with classical planning domain construction, reasoning-based planning, and prior program-synthesis agents such as WorldCoder. TheoryCoder-2 is able to solve complex tasks that the baselines fail, while only requiring minimal human prompts, unlike prior TBRL systems.
Fast weight programming and linear transformers: from machine learning to neurobiology
Aug 11, 2025Recent advances in artificial neural networks for machine learning, and language modeling in particular, have established a family of recurrent neural network (RNN) architectures that, unlike conventional RNNs with vector-form hidden states, use two-dimensional (2D) matrix-form hidden states. Such 2D-state RNNs, known as Fast Weight Programmers (FWPs), can be interpreted as a neural network whose synaptic weights (called fast weights) dynamically change over time as a function of input observations, and serve as short-term memory storage; corresponding synaptic weight modifications are controlled or programmed by another network (the programmer) whose parameters are trained (e.g., by gradient descent). In this Primer, we review the technical foundations of FWPs, their computational characteristics, and their connections to transformers and state space models. We also discuss connections between FWPs and models of synaptic plasticity in the brain, suggesting a convergence of natural and artificial intelligence.
Sequential-Parallel Duality in Prefix Scannable Models
Jun 12, 2025Modern neural sequence models are designed to meet the dual mandate of parallelizable training and fast sequential inference. Recent developments have given rise to various models, such as Gated Linear Attention (GLA) and Mamba, that achieve such ``sequential-parallel duality.'' This raises a natural question: can we characterize the full class of neural sequence models that support near-constant-time parallel evaluation and linear-time, constant-space sequential inference? We begin by describing a broad class of such models -- state space models -- as those whose state updates can be computed using the classic parallel prefix scan algorithm with a custom associative aggregation operator. We then define a more general class, Prefix-Scannable Models (PSMs), by relaxing the state aggregation operator to allow arbitrary (potentially non-associative) functions such as softmax attention. This generalization unifies many existing architectures, including element-wise RNNs (e.g., Mamba) and linear transformers (e.g., GLA, Mamba2, mLSTM), while also introducing new models with softmax-like operators that achieve O(1) amortized compute per token and log(N) memory for sequence length N. We empirically evaluate such models on illustrative small-scale language modeling and canonical synthetic tasks, including state tracking and associative recall. Empirically, we find that PSMs retain the expressivity of transformer-based architectures while matching the inference efficiency of state space models -- in some cases exhibiting better length generalization than either.
Key-value memory in the brain
Jan 06, 2025


Classical models of memory in psychology and neuroscience rely on similarity-based retrieval of stored patterns, where similarity is a function of retrieval cues and the stored patterns. While parsimonious, these models do not allow distinct representations for storage and retrieval, despite their distinct computational demands. Key-value memory systems, in contrast, distinguish representations used for storage (values) and those used for retrieval (keys). This allows key-value memory systems to optimize simultaneously for fidelity in storage and discriminability in retrieval. We review the computational foundations of key-value memory, its role in modern machine learning systems, related ideas from psychology and neuroscience, applications to a number of empirical puzzles, and possible biological implementations.
Why Are Positional Encodings Nonessential for Deep Autoregressive Transformers? Revisiting a Petroglyph
Dec 31, 2024
Do autoregressive Transformer language models require explicit positional encodings (PEs)? The answer is "no" as long as they have more than one layer -- they can distinguish sequences with permuted tokens without requiring explicit PEs. This property has been known since early efforts (those contemporary with GPT-2) adopting the Transformer for language modeling. However, this result does not appear to have been well disseminated and was even rediscovered recently. This may be partially due to a sudden growth of the language modeling community after the advent of GPT-2, but perhaps also due to the lack of a clear explanation in prior publications, despite being commonly understood by practitioners in the past. Here we review this long-forgotten explanation why explicit PEs are nonessential for multi-layer autoregressive Transformers (in contrast, one-layer models require PEs to discern order information of their input tokens). We also review the origin of this result, and hope to re-establish it as a common knowledge.
Neural networks that overcome classic challenges through practice
Oct 14, 2024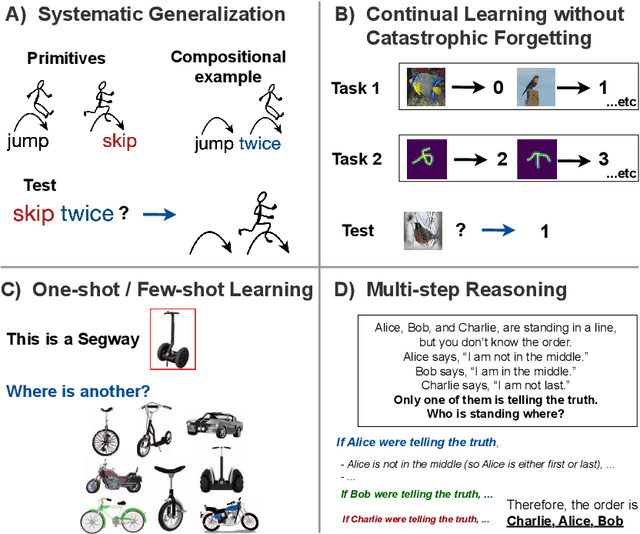
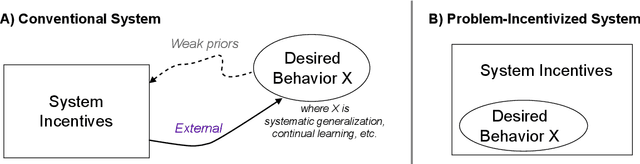
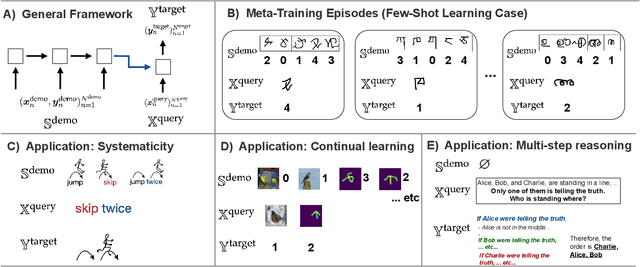
Since the earliest proposals for neural network models of the mind and brain, critics have pointed out key weaknesses in these models compared to human cognitive abilities. Here we review recent work that has used metalearning to help overcome some of these challenges. We characterize their successes as addressing an important developmental problem: they provide machines with an incentive to improve X (where X represents the desired capability) and opportunities to practice it, through explicit optimization for X; unlike conventional approaches that hope for achieving X through generalization from related but different objectives. We review applications of this principle to four classic challenges: systematicity, catastrophic forgetting, few-shot learning and multi-step reasoning; we also discuss related aspects of human development in natural environments.
MoEUT: Mixture-of-Experts Universal Transformers
May 25, 2024Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in learning compositional generalizations, but layer-sharing comes with a practical limitation of parameter-compute ratio: it drastically reduces the parameter count compared to the non-shared model with the same dimensionality. Naively scaling up the layer size to compensate for the loss of parameters makes its computational resource requirements prohibitive. In practice, no previous work has succeeded in proposing a shared-layer Transformer design that is competitive in parameter count-dominated tasks such as language modeling. Here we propose MoEUT (pronounced "moot"), an effective mixture-of-experts (MoE)-based shared-layer Transformer architecture, which combines several recent advances in MoEs for both feedforward and attention layers of standard Transformers together with novel layer-normalization and grouping schemes that are specific and crucial to UTs. The resulting UT model, for the first time, slightly outperforms standard Transformers on language modeling tasks such as BLiMP and PIQA, while using significantly less compute and memory.
Dissecting the Interplay of Attention Paths in a Statistical Mechanics Theory of Transformers
May 24, 2024Despite the remarkable empirical performance of Transformers, their theoretical understanding remains elusive. Here, we consider a deep multi-head self-attention network, that is closely related to Transformers yet analytically tractable. We develop a statistical mechanics theory of Bayesian learning in this model, deriving exact equations for the network's predictor statistics under the finite-width thermodynamic limit, i.e., $N,P\rightarrow\infty$, $P/N=\mathcal{O}(1)$, where $N$ is the network width and $P$ is the number of training examples. Our theory shows that the predictor statistics are expressed as a sum of independent kernels, each one pairing different 'attention paths', defined as information pathways through different attention heads across layers. The kernels are weighted according to a 'task-relevant kernel combination' mechanism that aligns the total kernel with the task labels. As a consequence, this interplay between attention paths enhances generalization performance. Experiments confirm our findings on both synthetic and real-world sequence classification tasks. Finally, our theory explicitly relates the kernel combination mechanism to properties of the learned weights, allowing for a qualitative transfer of its insights to models trained via gradient descent. As an illustration, we demonstrate an efficient size reduction of the network, by pruning those attention heads that are deemed less relevant by our theory.
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
Dec 14, 2023



The costly self-attention layers in modern Transformers require memory and compute quadratic in sequence length. Existing approximation methods usually underperform and fail to obtain significant speedups in practice. Here we present SwitchHead - a novel method that reduces both compute and memory requirements and achieves wall-clock speedup, while matching the language modeling performance of baseline Transformers with the same parameter budget. SwitchHead uses Mixture-of-Experts (MoE) layers for the value and output projections and requires 4 to 8 times fewer attention matrices than standard Transformers. Our novel attention can also be combined with MoE MLP layers, resulting in an efficient fully-MoE "SwitchAll" Transformer model. Our code is public.
Automating Continual Learning
Dec 01, 2023General-purpose learning systems should improve themselves in open-ended fashion in ever-changing environments. Conventional learning algorithms for neural networks, however, suffer from catastrophic forgetting (CF) -- previously acquired skills are forgotten when a new task is learned. Instead of hand-crafting new algorithms for avoiding CF, we propose Automated Continual Learning (ACL) to train self-referential neural networks to meta-learn their own in-context continual (meta-)learning algorithms. ACL encodes all desiderata -- good performance on both old and new tasks -- into its meta-learning objectives. Our experiments demonstrate that ACL effectively solves "in-context catastrophic forgetting"; our ACL-learned algorithms outperform hand-crafted ones, e.g., on the Split-MNIST benchmark in the replay-free setting, and enables continual learning of diverse tasks consisting of multiple few-shot and standard image classification datasets.