 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELF: Embedded Language Flows
May 11, 2026Diffusion and flow-based models have become the de facto approaches for generating continuous data, e.g., in domains such as images and videos. Their success has attracted growing interest in applying them to language modeling. Unlike their image-domain counterparts, today's leading diffusion language models (DLMs) primarily operate over discrete tokens. In this paper, we show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. We propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network. This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG). Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
Reaching Beyond the Mode: RL for Distributional Reasoning in Language Models
Mar 25, 2026Given a question, a language model (LM) implicitly encodes a distribution over possible answers. In practice, post-training procedures for LMs often collapse this distribution onto a single dominant mode. While this is generally not a problem for benchmark-style evaluations that assume one correct answer, many real-world tasks inherently involve multiple valid answers or irreducible uncertainty. Examples include medical diagnosis, ambiguous question answering, and settings with incomplete information. In these cases, we would like LMs to generate multiple plausible hypotheses, ideally with confidence estimates for each one, and without computationally intensive repeated sampling to generate non-modal answers. This paper describes a multi-answer reinforcement learning approach for training LMs to perform distributional reasoning over multiple answers during inference. We modify the RL objective to enable models to explicitly generate multiple candidate answers in a single forward pass, internalizing aspects of inference-time search into the model's generative process. Across question-answering, medical diagnostic, and coding benchmarks, we observe improved diversity, coverage, and set-level calibration scores compared to single answer trained baselines. Models trained with our approach require fewer tokens to generate multiple answers than competing approaches. On coding tasks, they are also substantially more accurate. These results position multi-answer RL as a principled and compute-efficient alternative to inference-time scaling procedures such as best-of-k. Code and more information can be found at https://multi-answer-rl.github.io/.
Pitfalls in Evaluating Interpretability Agents
Mar 20, 2026Automated interpretability systems aim to reduce the need for human labor and scale analysis to increasingly large models and diverse tasks. Recent efforts toward this goal leverage large language models (LLMs) at increasing levels of autonomy, ranging from fixed one-shot workflows to fully autonomous interpretability agents. This shift creates a corresponding need to scale evaluation approaches to keep pace with both the volume and complexity of generated explanations. We investigate this challenge in the context of automated circuit analysis -- explaining the roles of model components when performing specific tasks. To this end, we build an agentic system in which a research agent iteratively designs experiments and refines hypotheses. When evaluated against human expert explanations across six circuit analysis tasks in the literature, the system appears competitive. However, closer examination reveals several pitfalls of replication-based evaluation: human expert explanations can be subjective or incomplete, outcome-based comparisons obscure the research process, and LLM-based systems may reproduce published findings via memorization or informed guessing. To address some of these pitfalls, we propose an unsupervised intrinsic evaluation based on the functional interchangeability of model components. Our work demonstrates fundamental challenges in evaluating complex automated interpretability systems and reveals key limitations of replication-based evaluation.
Do LLMs Benefit From Their Own Words?
Feb 27, 2026Multi-turn interactions with large language models typically retain the assistant's own past responses in the conversation history. In this work, we revisit this design choice by asking whether large language models benefit from conditioning on their own prior responses. Using in-the-wild, multi-turn conversations, we compare standard (full-context) prompting with a user-turn-only prompting approach that omits all previous assistant responses, across three open reasoning models and one state-of-the-art model. To our surprise, we find that removing prior assistant responses does not affect response quality on a large fraction of turns. Omitting assistant-side history can reduce cumulative context lengths by up to 10x. To explain this result, we find that multi-turn conversations consist of a substantial proportion (36.4%) of self-contained prompts, and that many follow-up prompts provide sufficient instruction to be answered using only the current user turn and prior user turns. When analyzing cases where user-turn-only prompting substantially outperforms full context, we identify instances of context pollution, in which models over-condition on their previous responses, introducing errors, hallucinations, or stylistic artifacts that propagate across turns. Motivated by these findings, we design a context-filtering approach that selectively omits assistant-side context. Our findings suggest that selectively omitting assistant history can improve response quality while reducing memory consumption.
CONCUR: A Framework for Continual Constrained and Unconstrained Routing
Dec 10, 2025AI tasks differ in complexity and are best addressed with different computation strategies (e.g., combinations of models and decoding methods). Hence, an effective routing system that maps tasks to the appropriate strategies is crucial. Most prior methods build the routing framework by training a single model across all strategies, which demands full retraining whenever new strategies appear and leads to high overhead. Attempts at such continual routing, however, often face difficulties with generalization. Prior models also typically use a single input representation, limiting their ability to capture the full complexity of the routing problem and leading to sub-optimal routing decisions. To address these gaps, we propose CONCUR, a continual routing framework that supports both constrained and unconstrained routing (i.e., routing with or without a budget). Our modular design trains a separate predictor model for each strategy, enabling seamless incorporation of new strategies with low additional training cost. Our predictors also leverage multiple representations of both tasks and computation strategies to better capture overall problem complexity. Experiments on both in-distribution and out-of-distribution, knowledge- and reasoning-intensive tasks show that our method outperforms the best single strategy and strong existing routing techniques with higher end-to-end accuracy and lower inference cost in both continual and non-continual settings, while also reducing training cost in the continual setting.
ARC Is a Vision Problem!
Nov 18, 2025The Abstraction and Reasoning Corpus (ARC) is designed to promote research on abstract reasoning, a fundamental aspect of human intelligence. Common approaches to ARC treat it as a language-oriented problem, addressed by large language models (LLMs) or recurrent reasoning models. However, although the puzzle-like tasks in ARC are inherently visual, existing research has rarely approached the problem from a vision-centric perspective. In this work, we formulate ARC within a vision paradigm, framing it as an image-to-image translation problem. To incorporate visual priors, we represent the inputs on a "canvas" that can be processed like natural images. It is then natural for us to apply standard vision architectures, such as a vanilla Vision Transformer (ViT), to perform image-to-image mapping. Our model is trained from scratch solely on ARC data and generalizes to unseen tasks through test-time training. Our framework, termed Vision ARC (VARC), achieves 60.4% accuracy on the ARC-1 benchmark, substantially outperforming existing methods that are also trained from scratch. Our results are competitive with those of leading LLMs and close the gap to average human performance.
Training Language Models to Explain Their Own Computations
Nov 11, 2025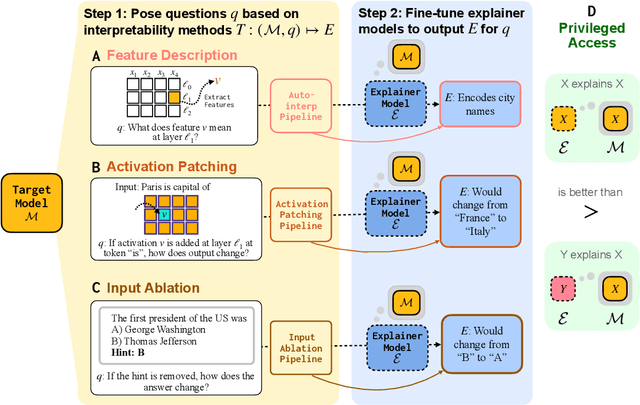
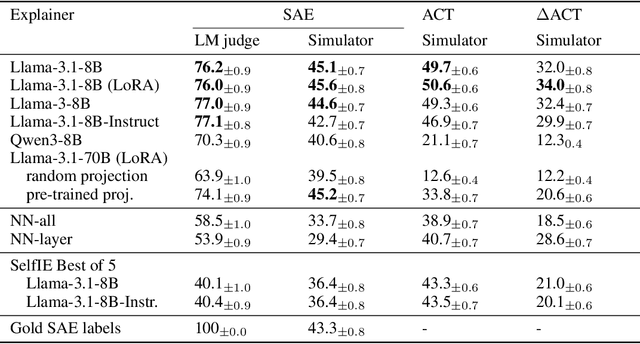
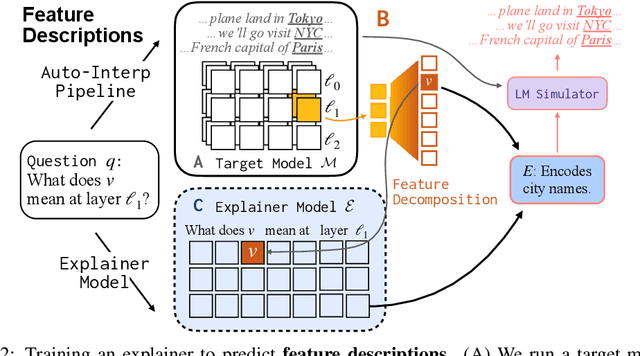
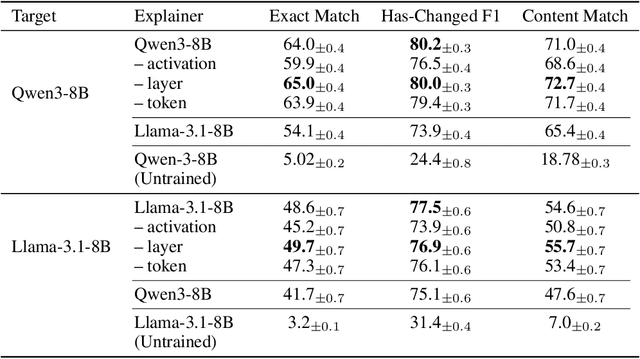
Can language models (LMs) learn to faithfully describe their internal computations? Are they better able to describe themselves than other models? We study the extent to which LMs' privileged access to their own internals can be leveraged to produce new techniques for explaining their behavior. Using existing interpretability techniques as a source of ground truth, we fine-tune LMs to generate natural language descriptions of (1) the information encoded by LM features, (2) the causal structure of LMs' internal activations, and (3) the influence of specific input tokens on LM outputs. When trained with only tens of thousands of example explanations, explainer models exhibit non-trivial generalization to new queries. This generalization appears partly attributable to explainer models' privileged access to their own internals: using a model to explain its own computations generally works better than using a *different* model to explain its computations (even if the other model is significantly more capable). Our results suggest not only that LMs can learn to reliably explain their internal computations, but that such explanations offer a scalable complement to existing interpretability methods.
Automated Detection of Visual Attribute Reliance with a Self-Reflective Agent
Oct 24, 2025When a vision model performs image recognition, which visual attributes drive its predictions? Detecting unintended reliance on specific visual features is critical for ensuring model robustness, preventing overfitting, and avoiding spurious correlations. We introduce an automated framework for detecting such dependencies in trained vision models. At the core of our method is a self-reflective agent that systematically generates and tests hypotheses about visual attributes that a model may rely on. This process is iterative: the agent refines its hypotheses based on experimental outcomes and uses a self-evaluation protocol to assess whether its findings accurately explain model behavior. When inconsistencies arise, the agent self-reflects over its findings and triggers a new cycle of experimentation. We evaluate our approach on a novel benchmark of 130 models designed to exhibit diverse visual attribute dependencies across 18 categories. Our results show that the agent's performance consistently improves with self-reflection, with a significant performance increase over non-reflective baselines. We further demonstrate that the agent identifies real-world visual attribute dependencies in state-of-the-art models, including CLIP's vision encoder and the YOLOv8 object detector.
Modeling Student Learning with 3.8 Million Program Traces
Oct 06, 2025As programmers write code, they often edit and retry multiple times, creating rich "interaction traces" that reveal how they approach coding tasks and provide clues about their level of skill development. For novice programmers in particular, these traces reflect the diverse reasoning processes they employ to code, such as exploratory behavior to understand how a programming concept works, re-strategizing in response to bugs, and personalizing stylistic choices. In this work, we explore what can be learned from training language models on such reasoning traces: not just about code, but about coders, and particularly students learning to program. We introduce a dataset of over 3.8 million programming reasoning traces from users of Pencil Code, a free online educational platform used by students to learn simple programming concepts. Compared to models trained only on final programs or synthetically-generated traces, we find that models trained on real traces are stronger at modeling diverse student behavior. Through both behavioral and probing analyses, we also find that many properties of code traces, such as goal backtracking or number of comments, can be predicted from learned representations of the students who write them. Building on this result, we show that we can help students recover from mistakes by steering code generation models to identify a sequence of edits that will results in more correct code while remaining close to the original student's style. Together, our results suggest that many properties of code are properties of individual students and that training on edit traces can lead to models that are more steerable, more predictive of student behavior while programming, and better at generating programs in their final states. Code and data is available at https://github.com/meghabyte/pencilcode-public
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Jul 22, 2025When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any analogous reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models.