 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaching Beyond the Mode: RL for Distributional Reasoning in Language Models
Mar 25, 2026Given a question, a language model (LM) implicitly encodes a distribution over possible answers. In practice, post-training procedures for LMs often collapse this distribution onto a single dominant mode. While this is generally not a problem for benchmark-style evaluations that assume one correct answer, many real-world tasks inherently involve multiple valid answers or irreducible uncertainty. Examples include medical diagnosis, ambiguous question answering, and settings with incomplete information. In these cases, we would like LMs to generate multiple plausible hypotheses, ideally with confidence estimates for each one, and without computationally intensive repeated sampling to generate non-modal answers. This paper describes a multi-answer reinforcement learning approach for training LMs to perform distributional reasoning over multiple answers during inference. We modify the RL objective to enable models to explicitly generate multiple candidate answers in a single forward pass, internalizing aspects of inference-time search into the model's generative process. Across question-answering, medical diagnostic, and coding benchmarks, we observe improved diversity, coverage, and set-level calibration scores compared to single answer trained baselines. Models trained with our approach require fewer tokens to generate multiple answers than competing approaches. On coding tasks, they are also substantially more accurate. These results position multi-answer RL as a principled and compute-efficient alternative to inference-time scaling procedures such as best-of-k. Code and more information can be found at https://multi-answer-rl.github.io/.
CoordLight: Learning Decentralized Coordination for Network-Wide Traffic Signal Control
Mar 25, 2026Adaptive traffic signal control (ATSC) is crucial in alleviating congestion, maximizing throughput and promoting sustainable mobility in ever-expanding cities. Multi-Agent Reinforcement Learning (MARL) has recently shown significant potential in addressing complex traffic dynamics, but the intricacies of partial observability and coordination in decentralized environments still remain key challenges in formulating scalable and efficient control strategies. To address these challenges, we present CoordLight, a MARL-based framework designed to improve intra-neighborhood traffic by enhancing decision-making at individual junctions (agents), as well as coordination with neighboring agents, thereby scaling up to network-level traffic optimization. Specifically, we introduce the Queue Dynamic State Encoding (QDSE), a novel state representation based on vehicle queuing models, which strengthens the agents' capability to analyze, predict, and respond to local traffic dynamics. We further propose an advanced MARL algorithm, named Neighbor-aware Policy Optimization (NAPO). It integrates an attention mechanism that discerns the state and action dependencies among adjacent agents, aiming to facilitate more coordinated decision-making, and to improve policy learning updates through robust advantage calculation. This enables agents to identify and prioritize crucial interactions with influential neighbors, thus enhancing the targeted coordination and collaboration among agents. Through comprehensive evaluations against state-of-the-art traffic signal control methods over three real-world traffic datasets composed of up to 196 intersections, we empirically show that CoordLight consistently exhibits superior performance across diverse traffic networks with varying traffic flows. The code is available at https://github.com/marmotlab/CoordLight
Self-Distillation Enables Continual Learning
Jan 27, 2026Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Jul 22, 2025When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any analogous reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models.
The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
Nov 11, 2024
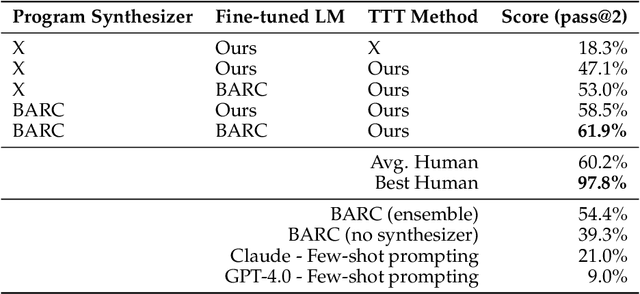
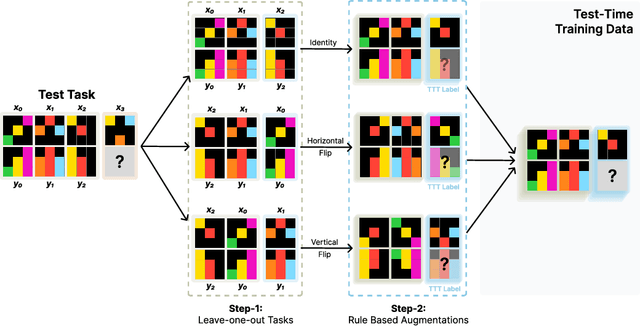
Language models have shown impressive performance on tasks within their training distribution, but often struggle with novel problems requiring complex reasoning. We investigate the effectiveness of test-time training (TTT) -- updating model parameters temporarily during inference using a loss derived from input data -- as a mechanism for improving models' reasoning capabilities, using the Abstraction and Reasoning Corpus (ARC) as a benchmark. Through systematic experimentation, we identify three crucial components for successful TTT: (1) initial finetuning on similar tasks (2) auxiliary task format and augmentations (3) per-instance training. TTT significantly improves performance on ARC tasks, achieving up to 6x improvement in accuracy compared to base fine-tuned models; applying TTT to an 8B-parameter language model, we achieve 53% accuracy on the ARC's public validation set, improving the state-of-the-art by nearly 25% for public and purely neural approaches. By ensembling our method with recent program generation approaches, we get SoTA public validation accuracy of 61.9%, matching the average human score. Our findings suggest that explicit symbolic search is not the only path to improved abstract reasoning in neural language models; additional test-time applied to continued training on few-shot examples can also be extremely effective.
Learning How Hard to Think: Input-Adaptive Allocation of LM Computation
Oct 07, 2024Computationally intensive decoding procedures--including search, reranking, and self-critique--can improve the quality of language model (LM) outputs in problems spanning code generation, numerical reasoning, and dialog. Existing work typically applies the same decoding procedure for every input to an LM. But not all inputs require the same amount of computation to process. Can we allocate decoding computation adaptively, using more resources to answer questions whose answers will be harder to compute? We present an approach that predicts the distribution of rewards given an input and computation budget, then allocates additional computation to inputs for which it is predicted to be most useful. We apply this approach in two decoding procedures: first, an adaptive best-of-k procedure that dynamically selects the number of samples to generate as input to a reranker; second, a routing procedure that dynamically responds to a query using a decoding procedure that is expensive but accurate, or one that is cheaper but less capable. Across a suite of programming, mathematics, and dialog tasks, we show that accurate computation-allocation procedures can be learned, and reduce computation by up to 50% at no cost to response quality, or improve quality by up to 10% at a fixed computational budget.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023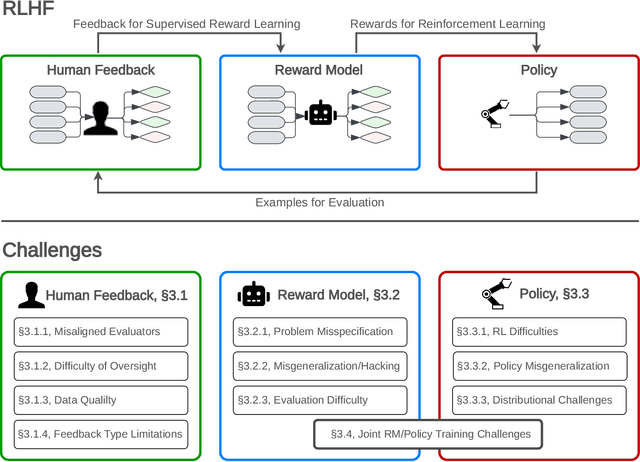
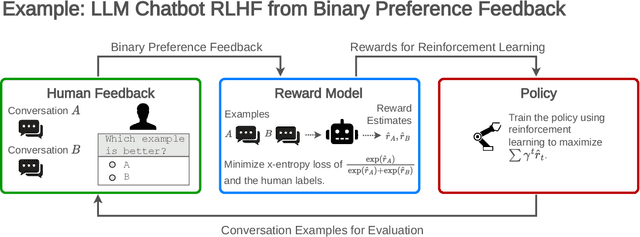
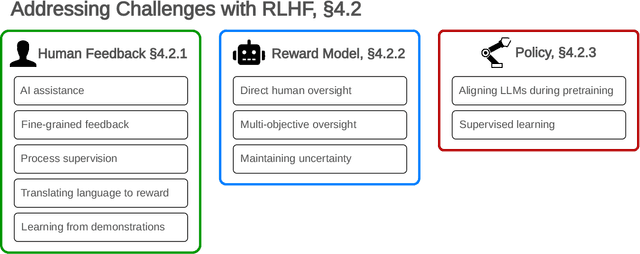

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Distributed Reinforcement Learning for Robot Teams: A Review
Apr 07, 2022
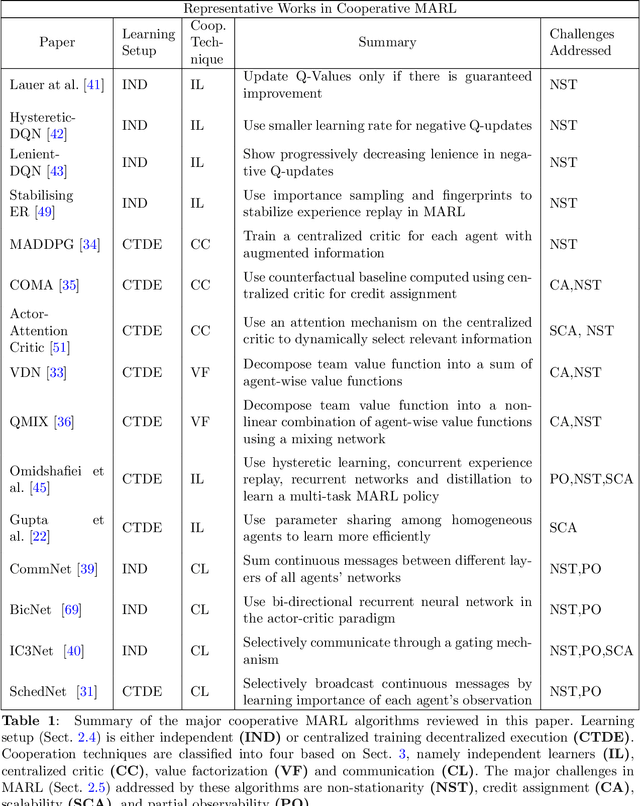

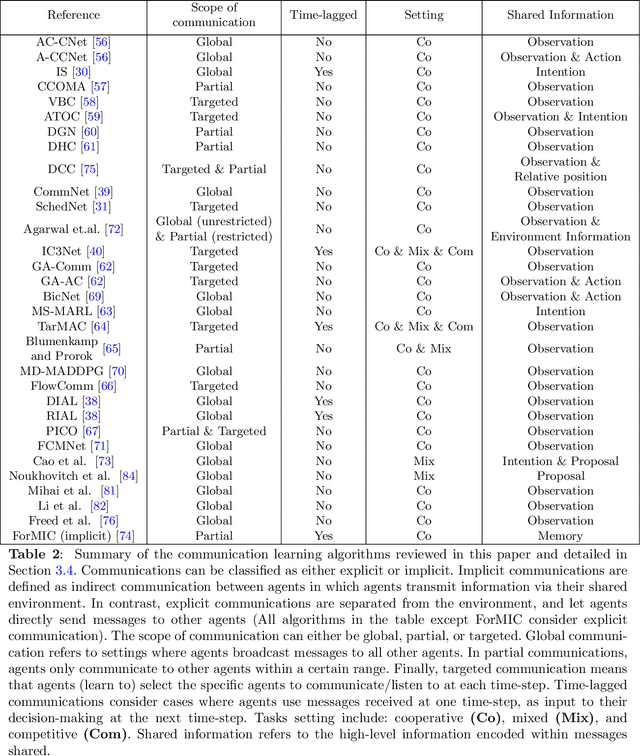
Purpose of review: Recent advances in sensing, actuation, and computation have opened the door to multi-robot systems consisting of hundreds/thousands of robots, with promising applications to automated manufacturing, disaster relief, harvesting, last-mile delivery, port/airport operations, or search and rescue. The community has leveraged model-free multi-agent reinforcement learning (MARL) to devise efficient, scalable controllers for multi-robot systems (MRS). This review aims to provide an analysis of the state-of-the-art in distributed MARL for multi-robot cooperation. Recent findings: Decentralized MRS face fundamental challenges, such as non-stationarity and partial observability. Building upon the "centralized training, decentralized execution" paradigm, recent MARL approaches include independent learning, centralized critic, value decomposition, and communication learning approaches. Cooperative behaviors are demonstrated through AI benchmarks and fundamental real-world robotic capabilities such as multi-robot motion/path planning. Summary: This survey reports the challenges surrounding decentralized model-free MARL for multi-robot cooperation and existing classes of approaches. We present benchmarks and robotic applications along with a discussion on current open avenues for research.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021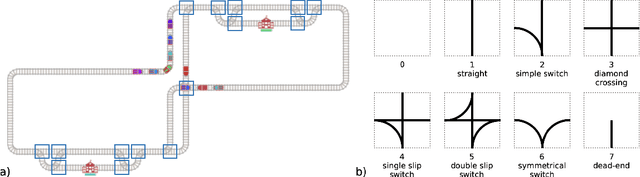
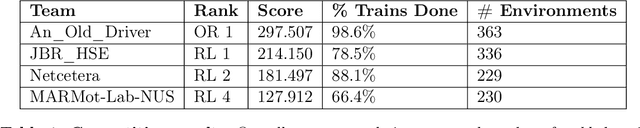
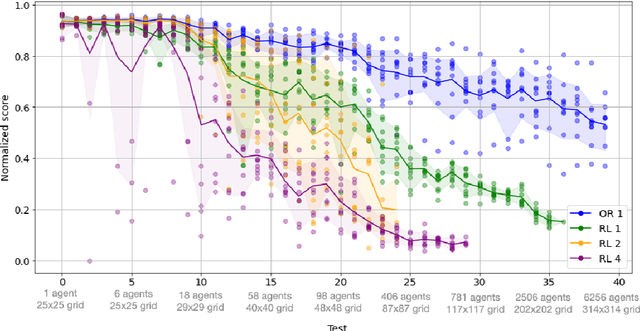
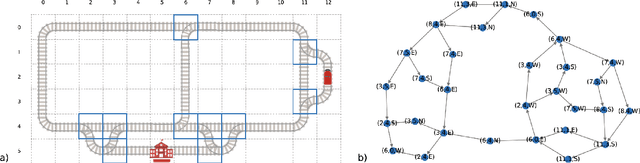
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
PRIMAL2: Pathfinding via Reinforcement and Imitation Multi-Agent Learning -- Lifelong
Oct 16, 2020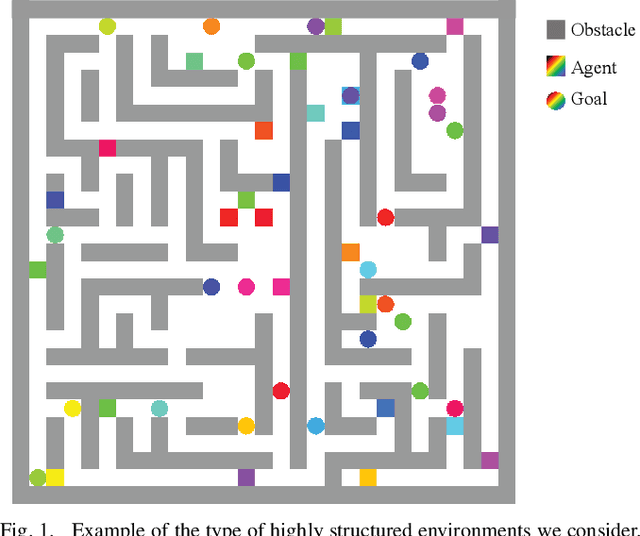
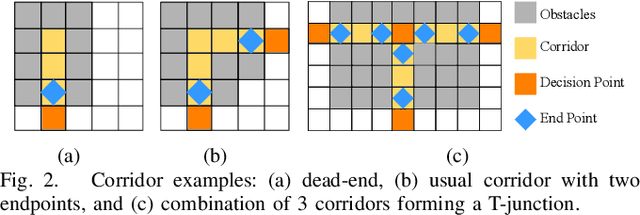
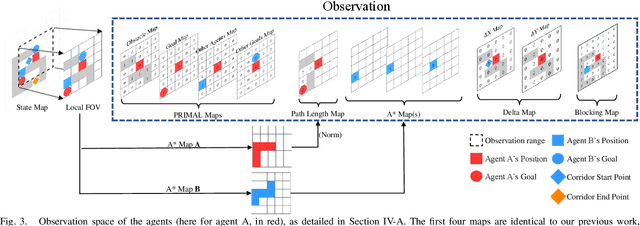
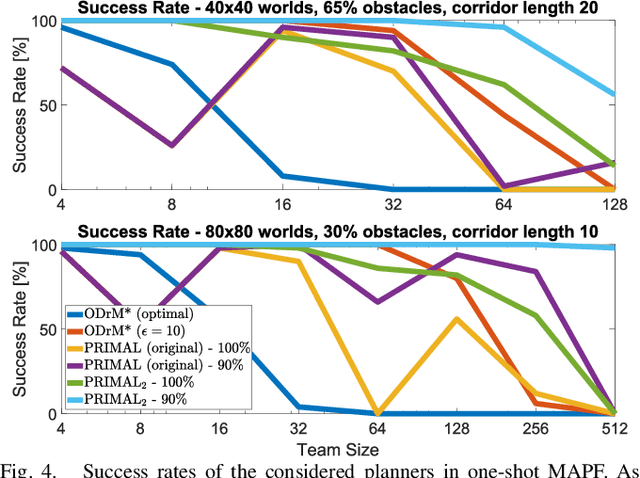
Multi-agent path finding (MAPF) is an indispensable component of large-scale robot deployments in numerous domains ranging from airport management to warehouse automation. In particular, this work addresses lifelong MAPF (LMAPF) -- an online variant of the problem where agents are immediately assigned a new goal upon reaching their current one -- in dense and highly structured environments, typical of real-world warehouses operations. Effectively solving LMAPF in such environments requires expensive coordination between agents as well as frequent replanning abilities, a daunting task for existing coupled and decoupled approaches alike. With the purpose of achieving considerable agent coordination without any compromise on reactivity and scalability, we introduce PRIMAL2, a distributed reinforcement learning framework for LMAPF where agents learn fully decentralized policies to reactively plan paths online in a partially observable world. We extend our previous work, which was effective in low-density sparsely occupied worlds, to highly structured and constrained worlds by identifying behaviors and conventions which improve implicit agent coordination, and enabling their learning through the construction of a novel local agent observation and various training aids. We present extensive results of PRIMAL2 in both MAPF and LMAPF environments with up to 1024 agents and compare its performance to complete state-of-the-art planners. We experimentally observe that agents successfully learn to follow ideal conventions and can exhibit selfless coordinated maneuvers that maximize joint rewards. We find that not only does PRIMAL2 significantly surpass our previous work, it is also able to perform on par and even outperform state-of-the-art planners in terms of throughput.