 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMAL2: Pathfinding via Reinforcement and Imitation Multi-Agent Learning -- Lifelong
Paper and Code
Oct 16, 2020
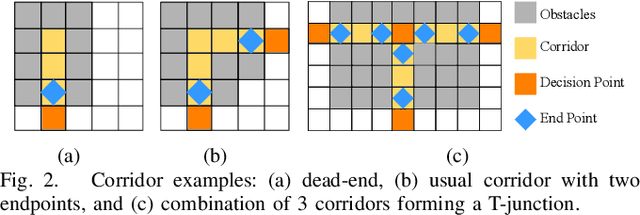
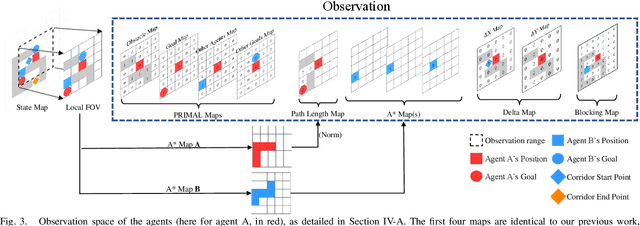
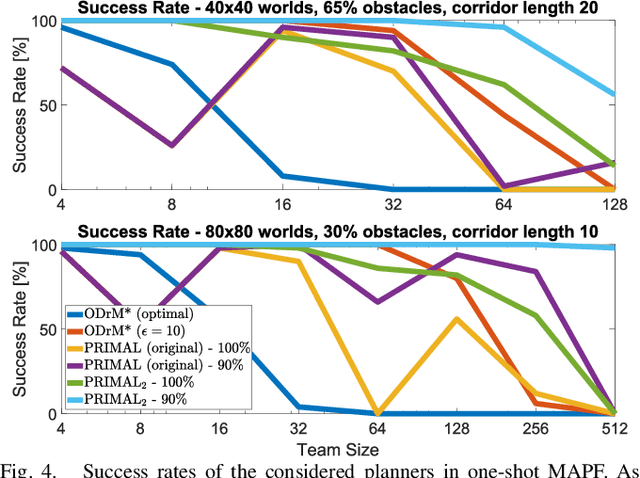
Multi-agent path finding (MAPF) is an indispensable component of large-scale robot deployments in numerous domains ranging from airport management to warehouse automation. In particular, this work addresses lifelong MAPF (LMAPF) -- an online variant of the problem where agents are immediately assigned a new goal upon reaching their current one -- in dense and highly structured environments, typical of real-world warehouses operations. Effectively solving LMAPF in such environments requires expensive coordination between agents as well as frequent replanning abilities, a daunting task for existing coupled and decoupled approaches alike. With the purpose of achieving considerable agent coordination without any compromise on reactivity and scalability, we introduce PRIMAL2, a distributed reinforcement learning framework for LMAPF where agents learn fully decentralized policies to reactively plan paths online in a partially observable world. We extend our previous work, which was effective in low-density sparsely occupied worlds, to highly structured and constrained worlds by identifying behaviors and conventions which improve implicit agent coordination, and enabling their learning through the construction of a novel local agent observation and various training aids. We present extensive results of PRIMAL2 in both MAPF and LMAPF environments with up to 1024 agents and compare its performance to complete state-of-the-art planners. We experimentally observe that agents successfully learn to follow ideal conventions and can exhibit selfless coordinated maneuvers that maximize joint rewards. We find that not only does PRIMAL2 significantly surpass our previous work, it is also able to perform on par and even outperform state-of-the-art planners in terms of throughput.