 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCOOD-Air: Prompting Heterogeneous Ground-Air Collaborative Perception with Spatial Conversion and Offset Prediction
Mar 14, 2026While Vehicle-to-Vehicle (V2V) collaboration extends sensing ranges through multi-agent data sharing, its reliability remains severely constrained by ground-level occlusions and the limited perspective of chassis-mounted sensors, which often result in critical perception blind spots. We propose OpenCOOD-Air, a novel framework that integrates UAVs as extensible platforms into V2V collaborative perception to overcome these constraints. To mitigate gradient interference from ground-air domain gaps and data sparsity, we adopt a transfer learning strategy to fine-tune UAV weights from pre-trained V2V models. To prevent the spatial information loss inherent in this transition, we formulate ground-air collaborative perception as a heterogeneous integration task with explicit altitude supervision and introduce a Cross-Domain Spatial Converter (CDSC) and a Spatial Offset Prediction Transformer (SOPT). Furthermore, we present the OPV2V-Air benchmark to validate the transition from V2V to Vehicle-to-Vehicle-to-UAV. Compared to state-of-the-art methods, our approach improves 2D and 3D AP@0.7 by 4% and 7%, respectively.
The Taxonomies, Training, and Applications of Event Stream Modelling for Electronic Health Records
Mar 14, 2026The widespread adoption of electronic health records (EHRs) enables the acquisition of heterogeneous clinical data, spanning lab tests, vital signs, medications, and procedures, which offer transformative potential for artificial intelligence in healthcare. Although traditional modelling approaches have typically relied on multivariate time series, they often struggle to accommodate the inherent sparsity and irregularity of real-world clinical workflows. Consequently, research has shifted toward event stream representation, which treats patient records as continuous sequences, thereby preserving the precise temporal structure of the patient journey. However, the existing literature remains fragmented, characterised by inconsistent definitions, disparate modelling architectures, and varying training protocols. To address these gaps, this review establishes a unified definition of EHR event streams and introduces a novel taxonomy that categorises models based on their handling of event time, type, and value. We systematically review training strategies, ranging from supervised learning to self-supervised methods, and provide a comprehensive discussion of applications across clinical scenarios. Finally, we identify open critical challenges and future directions, with the aim of clarifying the current landscape and guiding the development of next-generation healthcare models.
Cross-Linguistic Persona-Driven Data Synthesis for Robust Multimodal Cognitive Decline Detection
Feb 08, 2026Speech-based digital biomarkers represent a scalable, non-invasive frontier for the early identification of Mild Cognitive Impairment (MCI). However, the development of robust diagnostic models remains impeded by acute clinical data scarcity and a lack of interpretable reasoning. Current solutions frequently struggle with cross-lingual generalization and fail to provide the transparent rationales essential for clinical trust. To address these barriers, we introduce SynCog, a novel framework integrating controllable zero-shot multimodal data synthesis with Chain-of-Thought (CoT) deduction fine-tuning. Specifically, SynCog simulates diverse virtual subjects with varying cognitive profiles to effectively alleviate clinical data scarcity. This generative paradigm enables the rapid, zero-shot expansion of clinical corpora across diverse languages, effectively bypassing data bottlenecks in low-resource settings and bolstering the diagnostic performance of Multimodal Large Language Models (MLLMs). Leveraging this synthesized dataset, we fine-tune a foundational multimodal backbone using a CoT deduction strategy, empowering the model to explicitly articulate diagnostic thought processes rather than relying on black-box predictions. Extensive experiments on the ADReSS and ADReSSo benchmarks demonstrate that augmenting limited clinical data with synthetic phenotypes yields competitive diagnostic performance, achieving Macro-F1 scores of 80.67% and 78.46%, respectively, outperforming current baseline models. Furthermore, evaluation on an independent real-world Mandarin cohort (CIR-E) demonstrates robust cross-linguistic generalization, attaining a Macro-F1 of 48.71%. These findings constitute a critical step toward providing clinically trustworthy and linguistically inclusive cognitive assessment tools for global healthcare.
Bridging Data Gaps of Rare Conditions in ICU: A Multi-Disease Adaptation Approach for Clinical Prediction
Jul 08, 2025Artificial Intelligence has revolutionised critical care for common conditions. Yet, rare conditions in the intensive care unit (ICU), including recognised rare diseases and low-prevalence conditions in the ICU, remain underserved due to data scarcity and intra-condition heterogeneity. To bridge such gaps, we developed KnowRare, a domain adaptation-based deep learning framework for predicting clinical outcomes for rare conditions in the ICU. KnowRare mitigates data scarcity by initially learning condition-agnostic representations from diverse electronic health records through self-supervised pre-training. It addresses intra-condition heterogeneity by selectively adapting knowledge from clinically similar conditions with a developed condition knowledge graph. Evaluated on two ICU datasets across five clinical prediction tasks (90-day mortality, 30-day readmission, ICU mortality, remaining length of stay, and phenotyping), KnowRare consistently outperformed existing state-of-the-art models. Additionally, KnowRare demonstrated superior predictive performance compared to established ICU scoring systems, including APACHE IV and IV-a. Case studies further demonstrated KnowRare's flexibility in adapting its parameters to accommodate dataset-specific and task-specific characteristics, its generalisation to common conditions under limited data scenarios, and its rationality in selecting source conditions. These findings highlight KnowRare's potential as a robust and practical solution for supporting clinical decision-making and improving care for rare conditions in the ICU.
AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
May 19, 2025



Machine learning-based interatomic potentials and force fields depend critically on accurate atomic structures, yet such data are scarce due to the limited availability of experimentally resolved crystals. Although atomic-resolution electron microscopy offers a potential source of structural data, converting these images into simulation-ready formats remains labor-intensive and error-prone, creating a bottleneck for model training and validation. We introduce AutoMat, an end-to-end, agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts their physical properties. AutoMat combines pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation and property prediction via MatterSim, and coordinated orchestration across all stages. We propose the first dedicated STEM2Mat-Bench for this task and evaluate performance using lattice RMSD, formation energy MAE, and structure-matching success rate. By orchestrating external tool calls, AutoMat enables a text-only LLM to outperform vision-language models in this domain, achieving closed-loop reasoning throughout the pipeline. In large-scale experiments over 450 structure samples, AutoMat substantially outperforms existing multimodal large language models and tools. These results validate both AutoMat and STEM2Mat-Bench, marking a key step toward bridging microscopy and atomistic simulation in materials science.The code and dataset are publicly available at https://github.com/yyt-2378/AutoMat and https://huggingface.co/datasets/yaotianvector/STEM2Mat.
MambaOcc: Visual State Space Model for BEV-based Occupancy Prediction with Local Adaptive Reordering
Aug 21, 2024Occupancy prediction has attracted intensive attention and shown great superiority in the development of autonomous driving systems. The fine-grained environmental representation brought by occupancy prediction in terms of both geometry and semantic information has facilitated the general perception and safe planning under open scenarios. However, it also brings high computation costs and heavy parameters in existing works that utilize voxel-based 3d dense representation and Transformer-based quadratic attention. To address these challenges, in this paper, we propose a Mamba-based occupancy prediction method (MambaOcc) adopting BEV features to ease the burden of 3D scenario representation, and linear Mamba-style attention to achieve efficient long-range perception. Besides, to address the sensitivity of Mamba to sequence order, we propose a local adaptive reordering (LAR) mechanism with deformable convolution and design a hybrid BEV encoder comprised of convolution layers and Mamba. Extensive experiments on the Occ3D-nuScenes dataset demonstrate that MambaOcc achieves state-of-the-art performance in terms of both accuracy and computational efficiency. For example, compared to FlashOcc, MambaOcc delivers superior results while reducing the number of parameters by 42\% and computational costs by 39\%. Code will be available at https://github.com/Hub-Tian/MambaOcc.
Reinforcement Learning in Dynamic Treatment Regimes Needs Critical Reexamination
May 28, 2024



In the rapidly changing healthcare landscape, the implementation of offline reinforcement learning (RL) in dynamic treatment regimes (DTRs) presents a mix of unprecedented opportunities and challenges. This position paper offers a critical examination of the current status of offline RL in the context of DTRs. We argue for a reassessment of applying RL in DTRs, citing concerns such as inconsistent and potentially inconclusive evaluation metrics, the absence of naive and supervised learning baselines, and the diverse choice of RL formulation in existing research. Through a case study with more than 17,000 evaluation experiments using a publicly available Sepsis dataset, we demonstrate that the performance of RL algorithms can significantly vary with changes in evaluation metrics and Markov Decision Process (MDP) formulations. Surprisingly, it is observed that in some instances, RL algorithms can be surpassed by random baselines subjected to policy evaluation methods and reward design. This calls for more careful policy evaluation and algorithm development in future DTR works. Additionally, we discussed potential enhancements toward more reliable development of RL-based dynamic treatment regimes and invited further discussion within the community. Code is available at https://github.com/GilesLuo/ReassessDTR.
DTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
May 28, 2024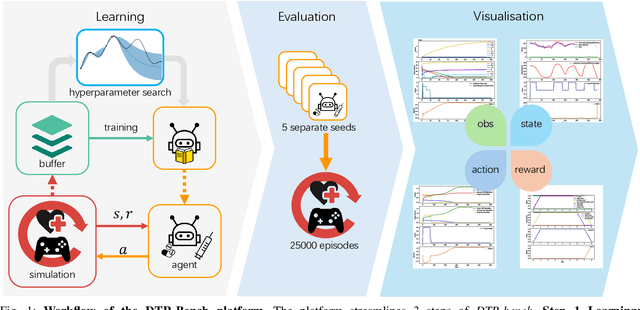
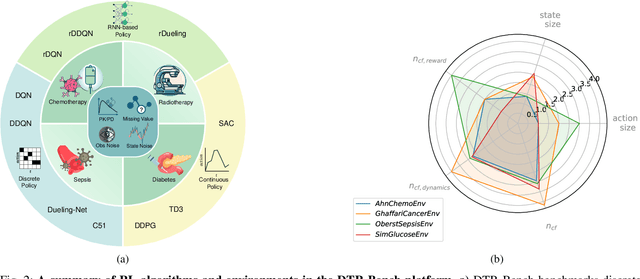


Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce \textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.
Integrating Chemistry Knowledge in Large Language Models via Prompt Engineering
Apr 22, 2024



This paper presents a study on the integration of domain-specific knowledge in prompt engineering to enhance the performance of large language models (LLMs) in scientific domains. A benchmark dataset is curated to encapsulate the intricate physical-chemical properties of small molecules, their drugability for pharmacology, alongside the functional attributes of enzymes and crystal materials, underscoring the relevance and applicability across biological and chemical domains.The proposed domain-knowledge embedded prompt engineering method outperforms traditional prompt engineering strategies on various metrics, including capability, accuracy, F1 score, and hallucination drop. The effectiveness of the method is demonstrated through case studies on complex materials including the MacMillan catalyst, paclitaxel, and lithium cobalt oxide. The results suggest that domain-knowledge prompts can guide LLMs to generate more accurate and relevant responses, highlighting the potential of LLMs as powerful tools for scientific discovery and innovation when equipped with domain-specific prompts. The study also discusses limitations and future directions for domain-specific prompt engineering development.
Diffuse Map Guiding Unsupervised Generative Adversarial Network for SVBRDF Estimation
May 25, 2022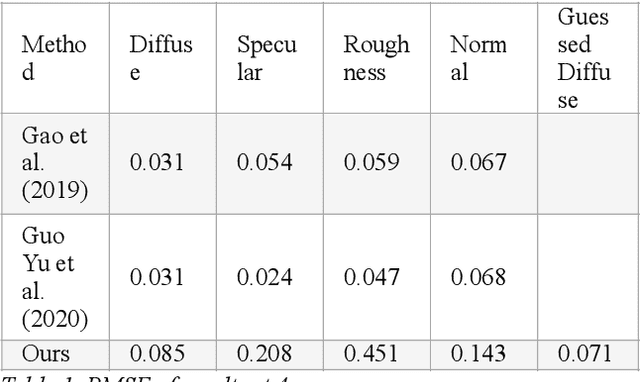
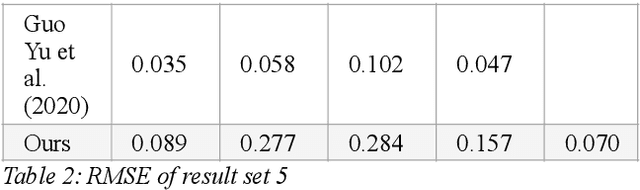
Reconstructing materials in the real world has always been a difficult problem in computer graphics. Accurately reconstructing the material in the real world is critical in the field of realistic rendering. Traditionally, materials in computer graphics are mapped by an artist, then mapped onto a geometric model by coordinate transformation, and finally rendered with a rendering engine to get realistic materials. For opaque objects, the industry commonly uses physical-based bidirectional reflectance distribution function (BRDF) rendering models for material modeling. The commonly used physical-based rendering models are Cook-Torrance BRDF, Disney BRDF. In this paper, we use the Cook-Torrance model to reconstruct the materials. The SVBRDF material parameters include Normal, Diffuse, Specular and Roughness. This paper presents a Diffuse map guiding material estimation method based on the Generative Adversarial Network(GAN). This method can predict plausible SVBRDF maps with global features using only a few pictures taken by the mobile phone. The main contributions of this paper are: 1) We preprocess a small number of input pictures to produce a large number of non-repeating pictures for training to reduce over-fitting. 2) We use a novel method to directly obtain the guessed diffuse map with global characteristics, which provides more prior information for the training process. 3) We improve the network architecture of the generator so that it can generate fine details of normal maps and reduce the possibility to generate over-flat normal maps. The method used in this paper can obtain prior knowledge without using dataset training, which greatly reduces the difficulty of material reconstruction and saves a lot of time to generate and calibrate datasets.