 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-KL Divergence-based Token Masking: A Novel Approach for Selective Fine-tuning of Large Language Models
May 28, 2026Supervised fine-tuning (SFT) followed by reinforcement learning (RL) has become a standard post-training paradigm for large language models. This paradigm provides a cold-start for RL exploration, avoiding the inefficiency of pure RL where on-policy sampling yields insufficient positive samples. However, in practice, existing approaches often use a small amount of data for SFT initialization compared to the RL phase, which can cause the model to fit the limited samples and shift away from its pre-trained distribution. This distribution shift impedes the model's ability to effectively explore during subsequent RL training. To address this challenge, we propose that in low-data regimes, SFT should prioritize activating task-relevant capabilities rather than memorizing specific content. Along this line, we propose EKSFT (Entropy-KL Selective Fine-Tuning), which selectively masks tokens that exhibit either high entropy or high KL divergence from a reference model. By excluding these high-uncertainty, distribution-shifting tokens from imitation, EKSFT injects task-specific knowledge while preserving the integrity of the model's pre-trained distribution. Empirical evaluations on mathematical reasoning benchmarks demonstrate that EKSFT consistently outperforms standard SFT. Further RL fine-tuning from the EKSFT model yields consistently better post-RL performance, indicating improved exploration for the RL stage. Our codes and datasets are available at https://github.com/MINE-USTC/EKSFT.
Cross-Subject EEG Emotion Recognition Based on Temporal Asynchronous Alignment Contrastive Learning
May 21, 2026With the advancement of science and technology, the importance of emotion research has become increasingly evident. Electroencephalography (EEG)-based emotion recognition has emerged as an active research area in recent years, owing to its objectivity and high temporal resolution. However, most existing methods focus on optimizing encoder structures to enhance feature extraction capabilities, while paying relatively little attention to similarity calculation strategies, particularly overlooking the potential temporal misalignment of responses among different subjects. To address these shortcomings, this paper draws inspiration from the late interaction mechanism of ColBERT in natural language processing (NLP) and proposes a Temporal Asynchronous Alignment-based Contrastive Learning (TA2CL) framework. This method transforms the traditional global "hard alignment" similarity calculation approach into a fine-grained local matching mechanism, enabling the model to adaptively search for and align "locally highly correlated" segments between two EEG signals, thereby effectively mitigating the effects of inter-subject differences and temporal delays. Experimental results demonstrate that the proposed method achieves strong performance across multiple public datasets. Specifically, on the FACED dataset, it achieves an accuracy of 64.5% for the nine-class classification task and 79.5% for the binary classification task, while on the SEED and SEED-V datasets, it achieves accuracies of 86.4% and 70.1%, respectively, validating the method's effectiveness and generalization capability.
Human-Centric Topic Modeling with Goal-Prompted Contrastive Learning and Optimal Transport
Apr 14, 2026Existing topic modeling methods, from LDA to recent neural and LLM-based approaches, which focus mainly on statistical coherence, often produce redundant or off-target topics that miss the user's underlying intent. We introduce Human-centric Topic Modeling, \emph{Human-TM}), a novel task formulation that integrates a human-provided goal directly into the topic modeling process to produce interpretable, diverse and goal-oriented topics. To tackle this challenge, we propose the \textbf{G}oal-prompted \textbf{C}ontrastive \textbf{T}opic \textbf{M}odel with \textbf{O}ptimal \textbf{T}ransport (GCTM-OT), which first uses LLM-based prompting to extract goal candidates from documents, then incorporates these into semantic-aware contrastive learning via optimal transport for topic discovery. Experimental results on three public subreddit datasets show that GCTM-OT outperforms state-of-the-art baselines in topic coherence and diversity while significantly improving alignment with human-provided goals, paving the way for more human-centric topic discovery systems.
ResPrune: Text-Conditioned Subspace Reconstruction for Visual Token Pruning in Large Vision-Language Models
Mar 22, 2026Large Vision-Language Models (LVLMs) rely on dense visual tokens to capture fine-grained visual information, but processing all these tokens incurs substantial computational and memory overhead during inference. To address this issue, we propose ResPrune, a training-free visual token pruning framework that enables efficient LVLM inference by selecting a compact yet informative subset of visual tokens. ResPrune formulates visual token pruning as a subspace reconstruction problem and employs a greedy subspace expansion strategy guided by residual energy, allowing it to preserve the geometric structure of the original visual token space. To further incorporate cross modal alignment, the selection process is conditioned on textual relevance, encouraging the retention of tokens that are both informative and instruction-relevant. The proposed method is lightweight and model-agnostic, and can be seamlessly integrated into existing LVLM pipelines without retraining or architectural modifications. Extensive experiments on multiple LVLM backbones, including LLaVA-1.5, LLaVA-NeXT, and Qwen2.5-VL, demonstrate that ResPrune consistently outperforms existing pruning approaches across a wide range of benchmarks, while achieving effective reductions in computation, memory consumption, and inference latency.
Discovering Decoupled Functional Modules in Large Language Models
Mar 18, 2026Understanding the internal functional organization of Large Language Models (LLMs) is crucial for improving their trustworthiness and performance. However, how LLMs organize different functions into modules remains highly unexplored. To bridge this gap, we formulate a functional module discovery problem and propose an Unsupervised LLM Cross-layer MOdule Discovery (ULCMOD) framework that simultaneously disentangles the large set of neurons in the entire LLM into modules while discovering the topics of input samples related to these modules. Our framework introduces a novel objective function and an efficient Iterative Decoupling (IterD) algorithm. Extensive experiments show that our method discovers high-quality, disentangled modules that capture more meaningful semantic information and achieve superior performance in various downstream tasks. Moreover, our qualitative analysis reveals that the discovered modules show semantic coherence, correspond to interpretable specializations, and a clear spatial and hierarchical organization within the LLM. Our work provides a novel tool for interpreting the functional modules of LLMs, filling a critical blank in LLM's interpretability research.
Training-Free Pyramid Token Pruning for Efficient Large Vision-Language Models via Region, Token, and Instruction-Guided Importance
Sep 19, 2025Large Vision-Language Models (LVLMs) have significantly advanced multimodal understanding but still struggle with efficiently processing high-resolution images. Recent approaches partition high-resolution images into multiple sub-images, dramatically increasing the number of visual tokens and causing exponential computational overhead during inference. To address these limitations, we propose a training-free token pruning strategy, Pyramid Token Pruning (PTP), that integrates bottom-up visual saliency at both region and token levels with top-down instruction-guided importance. Inspired by human visual attention mechanisms, PTP selectively retains more tokens from visually salient regions and further leverages textual instructions to pinpoint tokens most relevant to specific multimodal tasks. Extensive experiments across 13 diverse benchmarks demonstrate that our method substantially reduces computational overhead and inference latency with minimal performance loss.
HERO: Rethinking Visual Token Early Dropping in High-Resolution Large Vision-Language Models
Sep 16, 2025
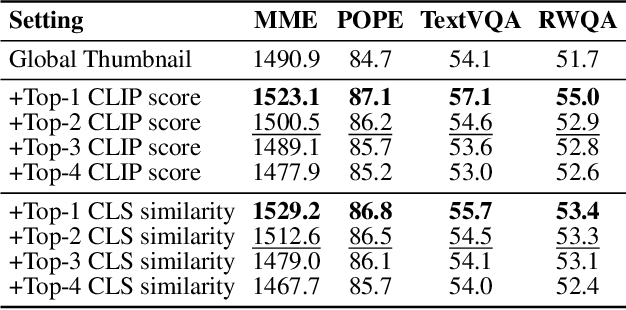
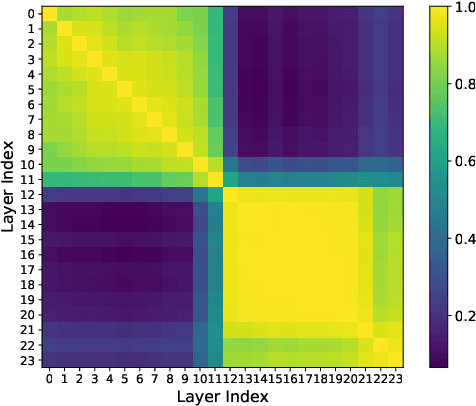
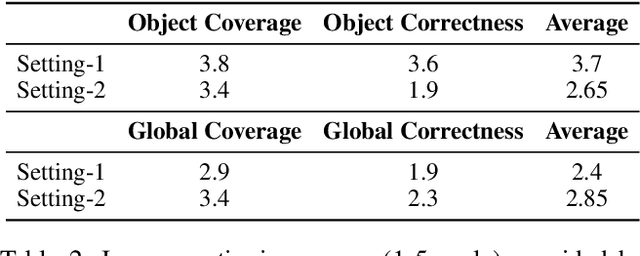
By cropping high-resolution images into local tiles and encoding them independently, High-Resolution Large Vision-Language Models (HR-LVLMs) have demonstrated remarkable fine-grained visual understanding capabilities. However, this divide-and-conquer paradigm significantly increases the number of visual tokens, resulting in substantial computational and memory overhead. To better understand and address this challenge, we empirically investigate visual token utilization in HR-LVLMs and uncover three key findings: (1) the local tiles have varying importance, jointly determined by visual saliency and task relevance; (2) the CLS token in CLIP-based vision encoders exhibits a two-stage attention pattern across layers, with each stage attending to different types of visual tokens; (3) the visual tokens emphasized at different stages encode information at varying levels of granularity, playing complementary roles within LVLMs. Building on these insights, we propose HERO, a High-resolution visual token early dropping framework that integrates content-adaptive token budget allocation with function-aware token selection. By accurately estimating tile-level importance and selectively retaining visual tokens with complementary roles, HERO achieves superior efficiency-accuracy trade-offs across diverse benchmarks and model scales, all in a training-free manner. This study provides both empirical insights and practical solutions toward efficient inference in HR-LVLMs.
Adacc: Adaptive Compression and Activation Checkpointing for LLM Memory Management
Aug 01, 2025Training large language models often employs recomputation to alleviate memory pressure, which can introduce up to 30% overhead in real-world scenarios. In this paper, we propose Adacc, a novel memory management framework that combines adaptive compression and activation checkpointing to reduce the GPU memory footprint. It comprises three modules: (1) We design layer-specific compression algorithms that account for outliers in LLM tensors, instead of directly quantizing floats from FP16 to INT4, to ensure model accuracy. (2) We propose an optimal scheduling policy that employs MILP to determine the best memory optimization for each tensor. (3) To accommodate changes in training tensors, we introduce an adaptive policy evolution mechanism that adjusts the policy during training to enhance throughput. Experimental results show that Adacc can accelerate the LLM training by 1.01x to 1.37x compared to state-of-the-art frameworks, while maintaining comparable model accuracy to the Baseline.
Global Semantic-Guided Sub-image Feature Weight Allocation in High-Resolution Large Vision-Language Models
Jan 24, 2025As the demand for high-resolution image processing in Large Vision-Language Models (LVLMs) grows, sub-image partitioning has become a popular approach for mitigating visual information loss associated with fixed-resolution processing. However, existing partitioning methods uniformly process sub-images, resulting in suboptimal image understanding. In this work, we reveal that the sub-images with higher semantic relevance to the entire image encapsulate richer visual information for preserving the model's visual understanding ability. Therefore, we propose the Global Semantic-guided Weight Allocator (GSWA) module, which dynamically allocates weights to sub-images based on their relative information density, emulating human visual attention mechanisms. This approach enables the model to focus on more informative regions, overcoming the limitations of uniform treatment. We integrate GSWA into the InternVL2-2B framework to create SleighVL, a lightweight yet high-performing model. Extensive experiments demonstrate that SleighVL outperforms models with comparable parameters and remains competitive with larger models. Our work provides a promising direction for more efficient and contextually aware high-resolution image processing in LVLMs, advancing multimodal system development.
FASP: Fast and Accurate Structured Pruning of Large Language Models
Jan 16, 2025



The rapid increase in the size of large language models (LLMs) has significantly escalated their computational and memory demands, posing challenges for efficient deployment, especially on resource-constrained devices. Structured pruning has emerged as an effective model compression method that can reduce these demands while preserving performance. In this paper, we introduce FASP (Fast and Accurate Structured Pruning), a novel structured pruning framework for LLMs that emphasizes both speed and accuracy. FASP employs a distinctive pruning structure that interlinks sequential layers, allowing for the removal of columns in one layer while simultaneously eliminating corresponding rows in the preceding layer without incurring additional performance loss. The pruning metric, inspired by Wanda, is computationally efficient and effectively selects components to prune. Additionally, we propose a restoration mechanism that enhances model fidelity by adjusting the remaining weights post-pruning. We evaluate FASP on the OPT and LLaMA model families, demonstrating superior performance in terms of perplexity and accuracy on downstream tasks compared to state-of-the-art methods. Our approach achieves significant speed-ups, pruning models such as OPT-125M in 17 seconds and LLaMA-30B in 15 minutes on a single NVIDIA RTX 4090 GPU, making it a highly practical solution for optimizing LLMs.