 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoTexBuild: 3D Building Model Generation from Map Footprints
Apr 11, 2025We introduce GeoTexBuild, a modular generative framework for creating 3D building models from map footprints. The proposed framework employs a three-stage process comprising height map generation, geometry reconstruction, and appearance stylization, culminating in building models with intricate geometry and appearance attributes. By integrating customized ControlNet and Text2Mesh models, we explore effective methods for controlling both geometric and visual attributes during the generation process. By this, we eliminate the problem of structural variations behind a single facade photo of the existing 3D generation techniques. Experimental results at each stage validate the capability of GeoTexBuild to generate detailed and accurate building models from footprints derived from site planning or map designs. Our framework significantly reduces manual labor in modeling buildings and can offer inspiration for designers.
Enhancement of 3D Gaussian Splatting using Raw Mesh for Photorealistic Recreation of Architectures
Jul 22, 2024The photorealistic reconstruction and rendering of architectural scenes have extensive applications in industries such as film, games, and transportation. It also plays an important role in urban planning, architectural design, and the city's promotion, especially in protecting historical and cultural relics. The 3D Gaussian Splatting, due to better performance over NeRF, has become a mainstream technology in 3D reconstruction. Its only input is a set of images but it relies heavily on geometric parameters computed by the SfM process. At the same time, there is an existing abundance of raw 3D models, that could inform the structural perception of certain buildings but cannot be applied. In this paper, we propose a straightforward method to harness these raw 3D models to guide 3D Gaussians in capturing the basic shape of the building and improve the visual quality of textures and details when photos are captured non-systematically. This exploration opens up new possibilities for improving the effectiveness of 3D reconstruction techniques in the field of architectural design.
Enhancement or Super-Resolution: Learning-based Adaptive Video Streaming with Client-Side Video Processing
Jan 20, 2022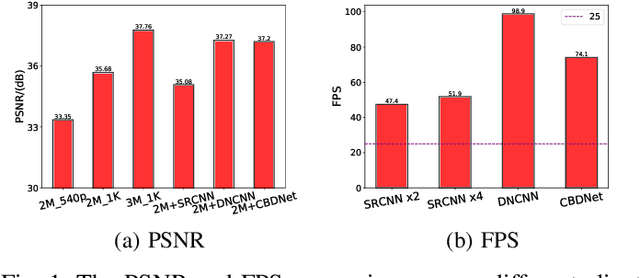
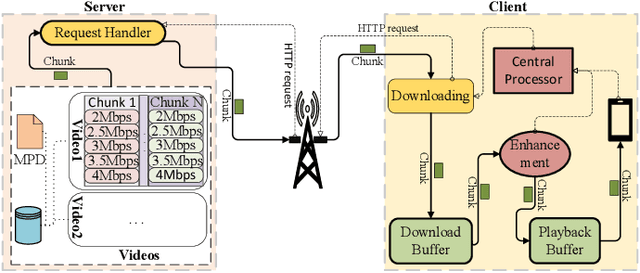
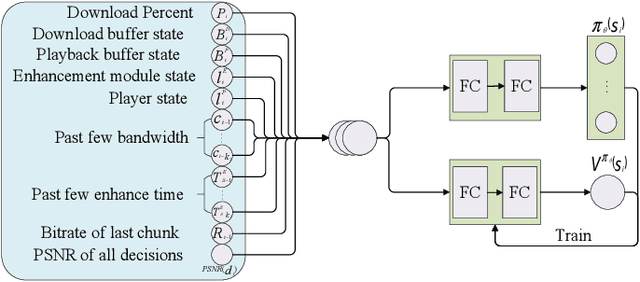
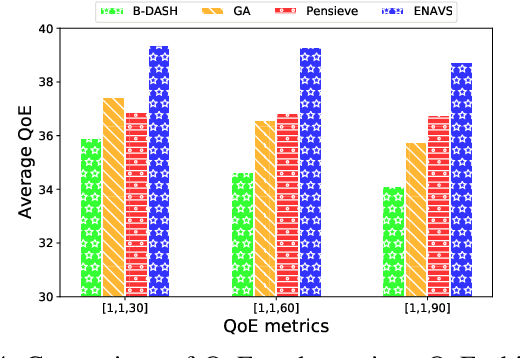
The rapid development of multimedia and communication technology has resulted in an urgent need for high-quality video streaming. However, robust video streaming under fluctuating network conditions and heterogeneous client computing capabilities remains a challenge. In this paper, we consider an enhancement-enabled video streaming network under a time-varying wireless network and limited computation capacity. "Enhancement" means that the client can improve the quality of the downloaded video segments via image processing modules. We aim to design a joint bitrate adaptation and client-side enhancement algorithm toward maximizing the quality of experience (QoE). We formulate the problem as a Markov decision process (MDP) and propose a deep reinforcement learning (DRL)-based framework, named ENAVS. As video streaming quality is mainly affected by video compression, we demonstrate that the video enhancement algorithm outperforms the super-resolution algorithm in terms of signal-to-noise ratio and frames per second, suggesting a better solution for client processing in video streaming. Ultimately, we implement ENAVS and demonstrate extensive testbed results under real-world bandwidth traces and videos. The simulation shows that ENAVS is capable of delivering 5%-14% more QoE under the same bandwidth and computing power conditions as conventional ABR streaming.
Learning Geo-Contextual Embeddings for Commuting Flow Prediction
May 04, 2020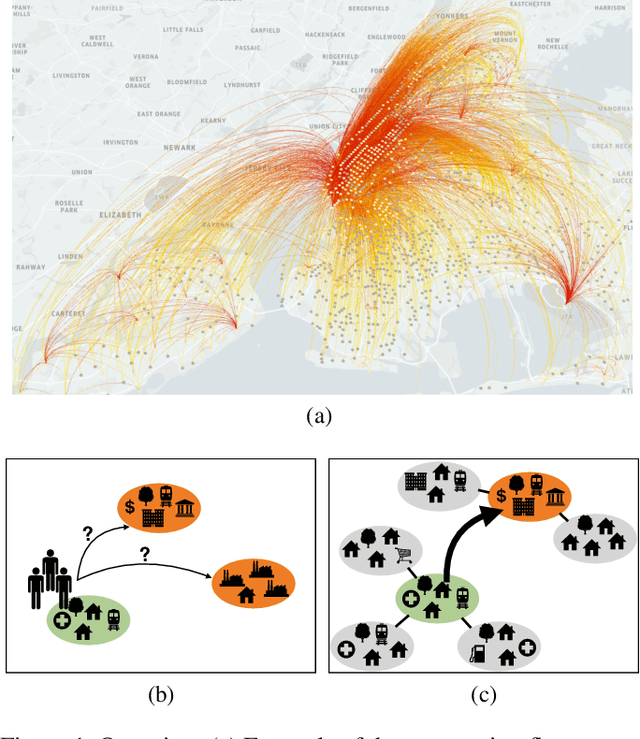
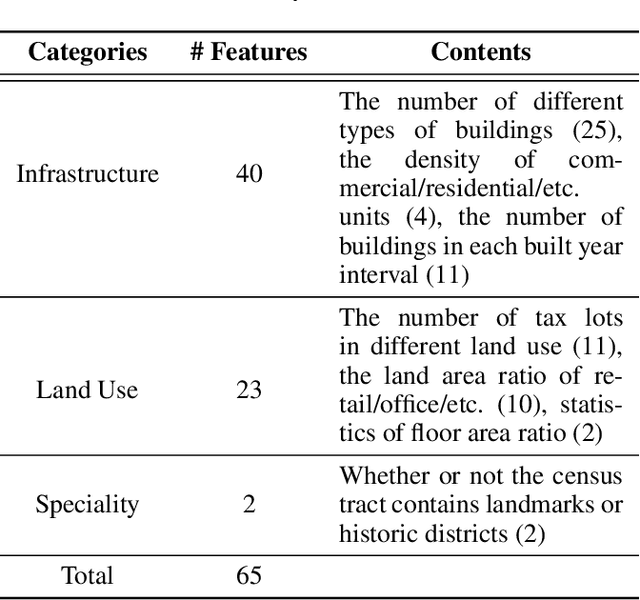
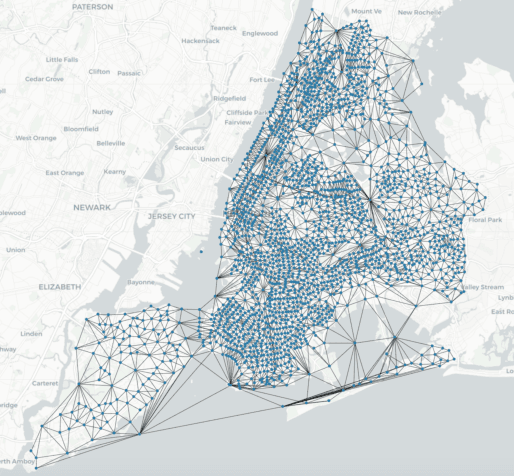
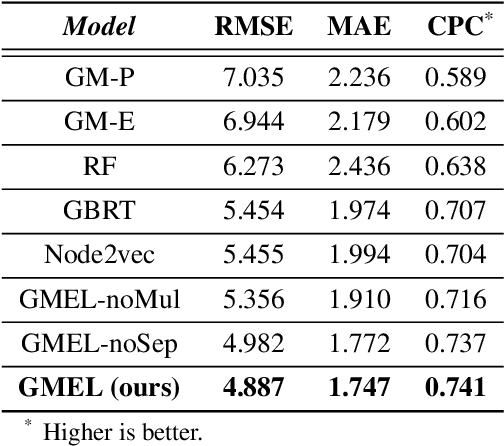
Predicting commuting flows based on infrastructure and land-use information is critical for urban planning and public policy development. However, it is a challenging task given the complex patterns of commuting flows. Conventional models, such as gravity model, are mainly derived from physics principles and limited by their predictive power in real-world scenarios where many factors need to be considered. Meanwhile, most existing machine learning-based methods ignore the spatial correlations and fail to model the influence of nearby regions. To address these issues, we propose Geo-contextual Multitask Embedding Learner (GMEL), a model that captures the spatial correlations from geographic contextual information for commuting flow prediction. Specifically, we first construct a geo-adjacency network containing the geographic contextual information. Then, an attention mechanism is proposed based on the framework of graph attention network (GAT) to capture the spatial correlations and encode geographic contextual information to embedding space. Two separate GATs are used to model supply and demand characteristics. A multitask learning framework is used to introduce stronger restrictions and enhance the effectiveness of the embedding representation. Finally, a gradient boosting machine is trained based on the learned embeddings to predict commuting flows. We evaluate our model using real-world datasets from New York City and the experimental results demonstrate the effectiveness of our proposal against the state of the art.
* Github: https://github.com/jackmiemie/GMEL
Unsupervised Classification of Street Architectures Based on InfoGAN
May 30, 2019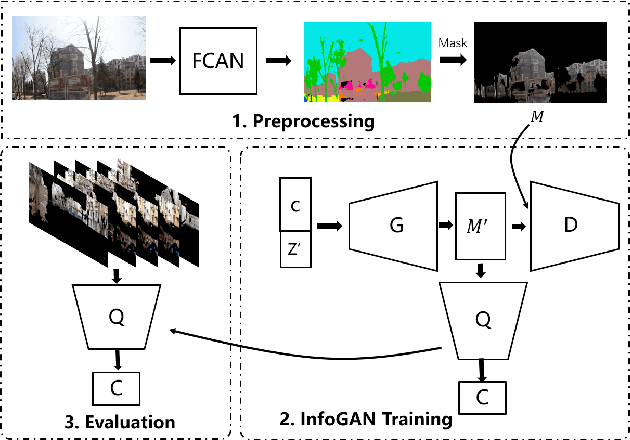
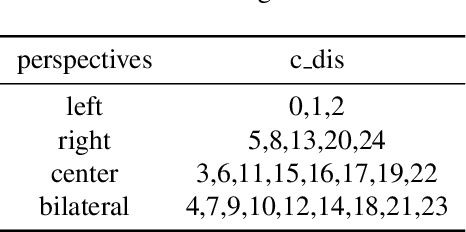

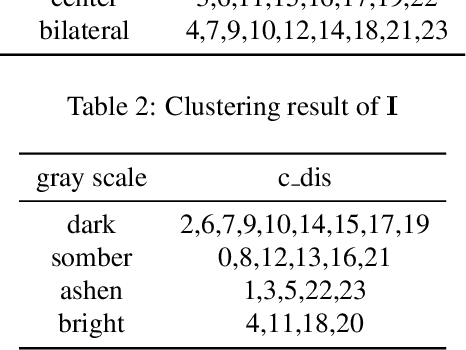
Street architectures play an essential role in city image and streetscape analysing. However, existing approaches are all supervised which require costly labeled data. To solve this, we propose a street architectural unsupervised classification framework based on Information maximizing Generative Adversarial Nets (InfoGAN), in which we utilize the auxiliary distribution $Q$ of InfoGAN as an unsupervised classifier. Experiments on database of true street view images in Nanjing, China validate the practicality and accuracy of our framework. Furthermore, we draw a series of heuristic conclusions from the intrinsic information hidden in true images. These conclusions will assist planners to know the architectural categories better.