 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Predicting Household Water Consumption Using Satellite and Street View Images in Two Indian Cities
Oct 30, 2025Monitoring household water use in rapidly urbanizing regions is hampered by costly, time-intensive enumeration methods and surveys. We investigate whether publicly available imagery-satellite tiles, Google Street View (GSV) segmentation-and simple geospatial covariates (nightlight intensity, population density) can be utilized to predict household water consumption in Hubballi-Dharwad, India. We compare four approaches: survey features (benchmark), CNN embeddings (satellite, GSV, combined), and GSV semantic maps with auxiliary data. Under an ordinal classification framework, GSV segmentation plus remote-sensing covariates achieves 0.55 accuracy for water use, approaching survey-based models (0.59 accuracy). Error analysis shows high precision at extremes of the household water consumption distribution, but confusion among middle classes is due to overlapping visual proxies. We also compare and contrast our estimates for household water consumption to that of household subjective income. Our findings demonstrate that open-access imagery, coupled with minimal geospatial data, offers a promising alternative to obtaining reliable household water consumption estimates using surveys in urban analytics.
GenQuest: An LLM-based Text Adventure Game for Language Learners
Oct 06, 2025GenQuest is a generative text adventure game that leverages Large Language Models (LLMs) to facilitate second language learning through immersive, interactive storytelling. The system engages English as a Foreign Language (EFL) learners in a collaborative "choose-your-own-adventure" style narrative, dynamically generated in response to learner choices. Game mechanics such as branching decision points and story milestones are incorporated to maintain narrative coherence while allowing learner-driven plot development. Key pedagogical features include content generation tailored to each learner's proficiency level, and a vocabulary assistant that provides in-context explanations of learner-queried text strings, ranging from words and phrases to sentences. Findings from a pilot study with university EFL students in China indicate promising vocabulary gains and positive user perceptions. Also discussed are suggestions from participants regarding the narrative length and quality, and the request for multi-modal content such as illustrations.
Beyond the Score: Uncertainty-Calibrated LLMs for Automated Essay Assessment
Sep 19, 2025
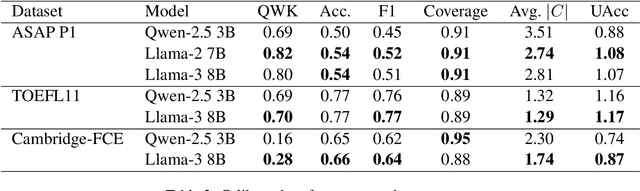

Automated Essay Scoring (AES) systems now reach near human agreement on some public benchmarks, yet real-world adoption, especially in high-stakes examinations, remains limited. A principal obstacle is that most models output a single score without any accompanying measure of confidence or explanation. We address this gap with conformal prediction, a distribution-free wrapper that equips any classifier with set-valued outputs and formal coverage guarantees. Two open-source large language models (Llama-3 8B and Qwen-2.5 3B) are fine-tuned on three diverse corpora (ASAP, TOEFL11, Cambridge-FCE) and calibrated at a 90 percent risk level. Reliability is assessed with UAcc, an uncertainty-aware accuracy that rewards models for being both correct and concise. To our knowledge, this is the first work to combine conformal prediction and UAcc for essay scoring. The calibrated models consistently meet the coverage target while keeping prediction sets compact, indicating that open-source, mid-sized LLMs can already support teacher-in-the-loop AES; we discuss scaling and broader user studies as future work.
GeoTexBuild: 3D Building Model Generation from Map Footprints
Apr 11, 2025We introduce GeoTexBuild, a modular generative framework for creating 3D building models from map footprints. The proposed framework employs a three-stage process comprising height map generation, geometry reconstruction, and appearance stylization, culminating in building models with intricate geometry and appearance attributes. By integrating customized ControlNet and Text2Mesh models, we explore effective methods for controlling both geometric and visual attributes during the generation process. By this, we eliminate the problem of structural variations behind a single facade photo of the existing 3D generation techniques. Experimental results at each stage validate the capability of GeoTexBuild to generate detailed and accurate building models from footprints derived from site planning or map designs. Our framework significantly reduces manual labor in modeling buildings and can offer inspiration for designers.
Diffusion-Guided Gaussian Splatting for Large-Scale Unconstrained 3D Reconstruction and Novel View Synthesis
Apr 02, 2025Recent advancements in 3D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) have achieved impressive results in real-time 3D reconstruction and novel view synthesis. However, these methods struggle in large-scale, unconstrained environments where sparse and uneven input coverage, transient occlusions, appearance variability, and inconsistent camera settings lead to degraded quality. We propose GS-Diff, a novel 3DGS framework guided by a multi-view diffusion model to address these limitations. By generating pseudo-observations conditioned on multi-view inputs, our method transforms under-constrained 3D reconstruction problems into well-posed ones, enabling robust optimization even with sparse data. GS-Diff further integrates several enhancements, including appearance embedding, monocular depth priors, dynamic object modeling, anisotropy regularization, and advanced rasterization techniques, to tackle geometric and photometric challenges in real-world settings. Experiments on four benchmarks demonstrate that GS-Diff consistently outperforms state-of-the-art baselines by significant margins.
Optimized Resource Allocation for Cloud-Native 6G Networks: Zero-Touch ML Models in Microservices-based VNF Deployments
Oct 09, 2024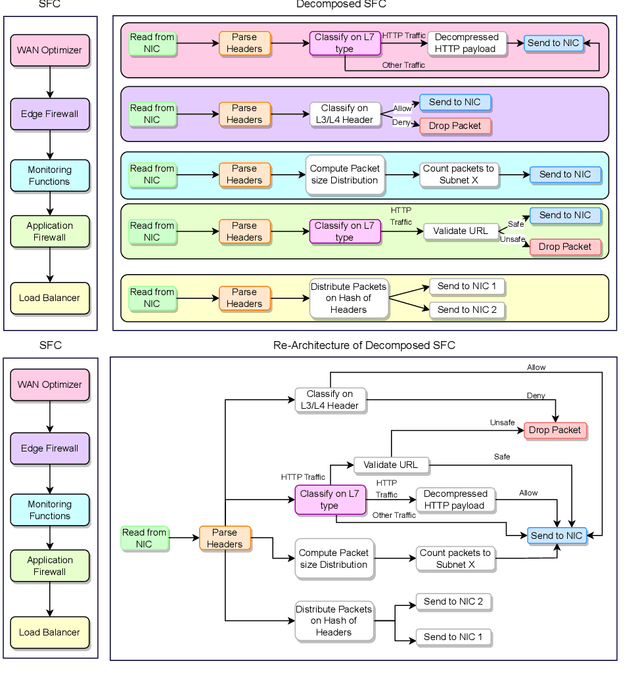
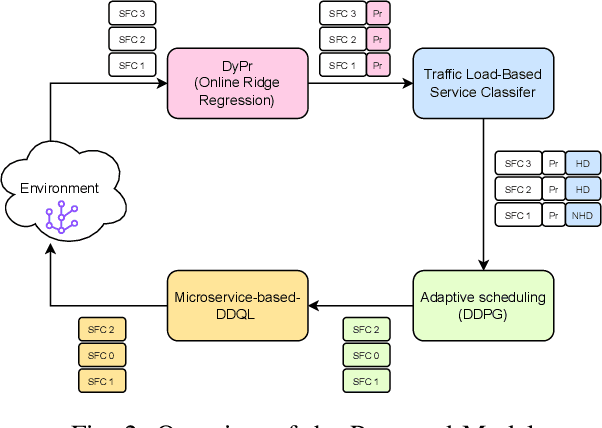
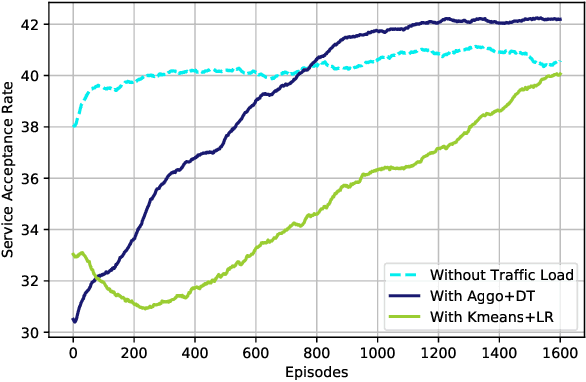
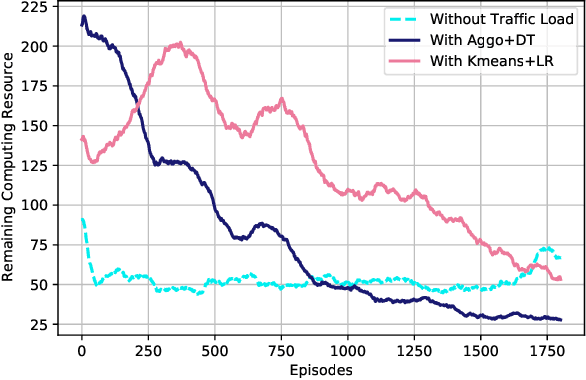
6G, the next generation of mobile networks, is set to offer even higher data rates, ultra-reliability, and lower latency than 5G. New 6G services will increase the load and dynamism of the network. Network Function Virtualization (NFV) aids with this increased load and dynamism by eliminating hardware dependency. It aims to boost the flexibility and scalability of network deployment services by separating network functions from their specific proprietary forms so that they can run as virtual network functions (VNFs) on commodity hardware. It is essential to design an NFV orchestration and management framework to support these services. However, deploying bulky monolithic VNFs on the network is difficult, especially when underlying resources are scarce, resulting in ineffective resource management. To address this, microservices-based NFV approaches are proposed. In this approach, monolithic VNFs are decomposed into micro VNFs, increasing the likelihood of their successful placement and resulting in more efficient resource management. This article discusses the proposed framework for resource allocation for microservices-based services to provide end-to-end Quality of Service (QoS) using the Double Deep Q Learning (DDQL) approach. Furthermore, to enhance this resource allocation approach, we discussed and addressed two crucial sub-problems: the need for a dynamic priority technique and the presence of the low-priority starvation problem. Using the Deep Deterministic Policy Gradient (DDPG) model, an Adaptive Scheduling model is developed that effectively mitigates the starvation problem. Additionally, the impact of incorporating traffic load considerations into deployment and scheduling is thoroughly investigated.
KAN versus MLP on Irregular or Noisy Functions
Aug 15, 2024



In this paper, we compare the performance of Kolmogorov-Arnold Networks (KAN) and Multi-Layer Perceptron (MLP) networks on irregular or noisy functions. We control the number of parameters and the size of the training samples to ensure a fair comparison. For clarity, we categorize the functions into six types: regular functions, continuous functions with local non-differentiable points, functions with jump discontinuities, functions with singularities, functions with coherent oscillations, and noisy functions. Our experimental results indicate that KAN does not always perform best. For some types of functions, MLP outperforms or performs comparably to KAN. Furthermore, increasing the size of training samples can improve performance to some extent. When noise is added to functions, the irregular features are often obscured by the noise, making it challenging for both MLP and KAN to extract these features effectively. We hope these experiments provide valuable insights for future neural network research and encourage further investigations to overcome these challenges.
An Evaluation of Standard Statistical Models and LLMs on Time Series Forecasting
Aug 09, 2024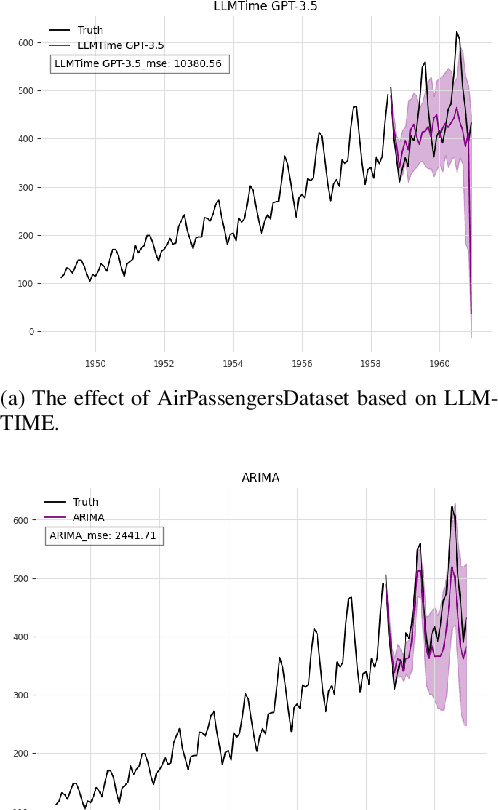
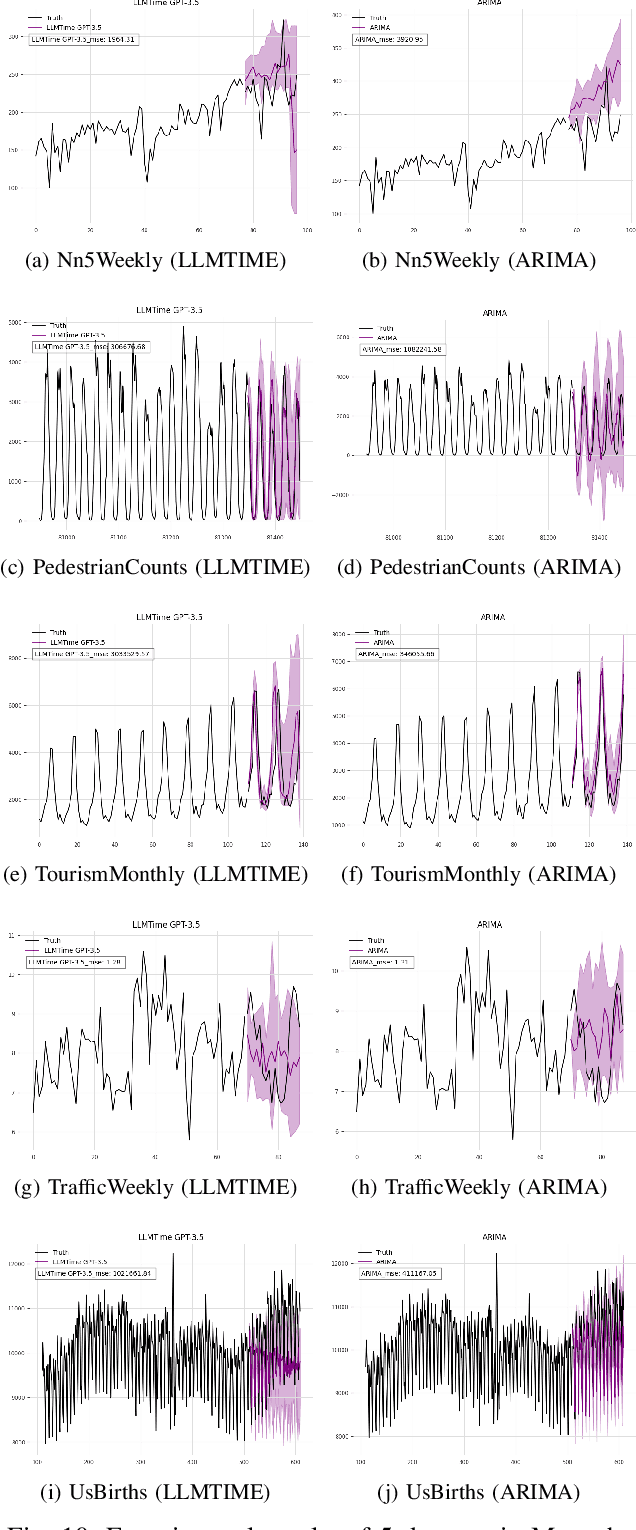
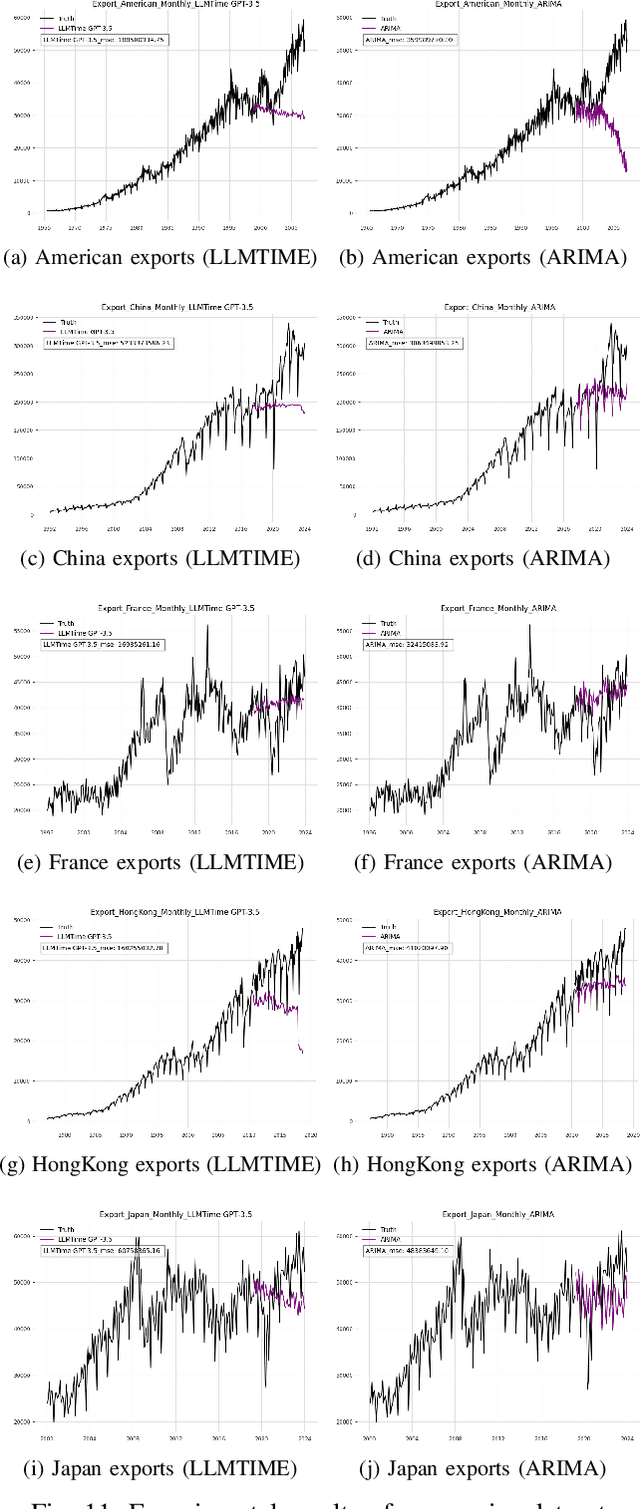
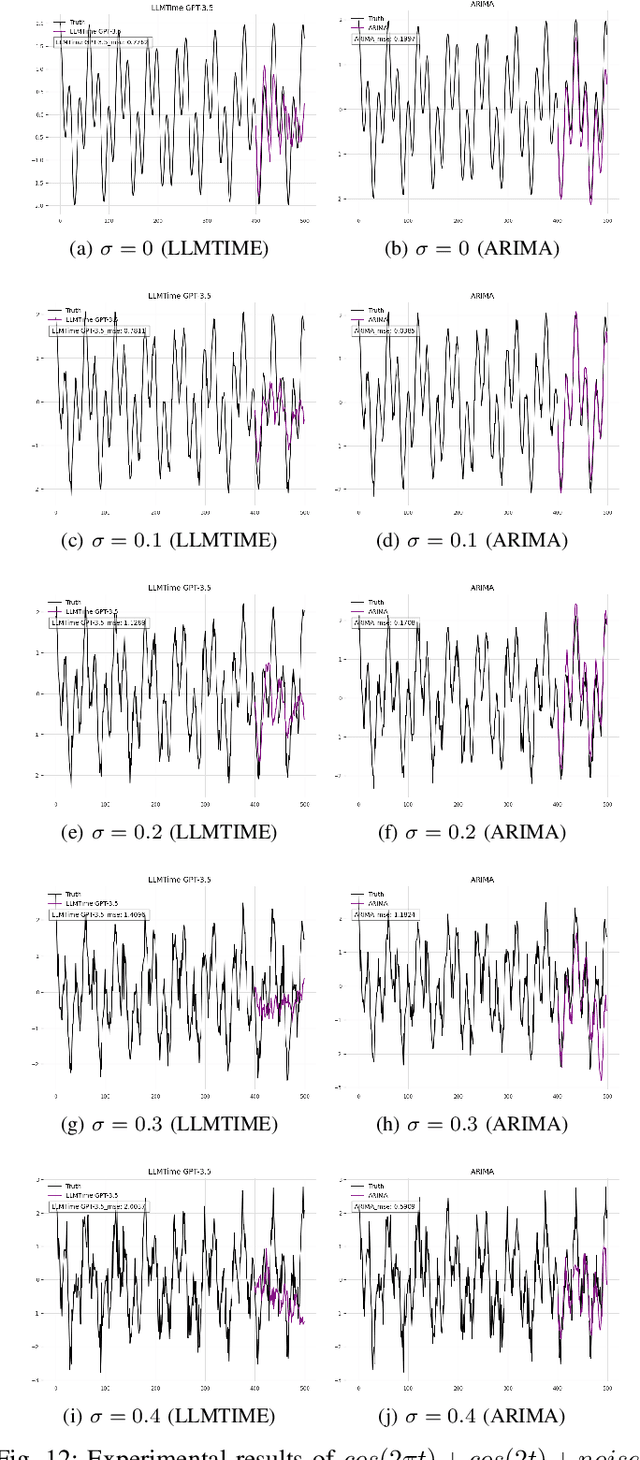
This research examines the use of Large Language Models (LLMs) in predicting time series, with a specific focus on the LLMTIME model. Despite the established effectiveness of LLMs in tasks such as text generation, language translation, and sentiment analysis, this study highlights the key challenges that large language models encounter in the context of time series prediction. We assess the performance of LLMTIME across multiple datasets and introduce classical almost periodic functions as time series to gauge its effectiveness. The empirical results indicate that while large language models can perform well in zero-shot forecasting for certain datasets, their predictive accuracy diminishes notably when confronted with diverse time series data and traditional signals. The primary finding of this study is that the predictive capacity of LLMTIME, similar to other LLMs, significantly deteriorates when dealing with time series data that contain both periodic and trend components, as well as when the signal comprises complex frequency components.
Enhancement of 3D Gaussian Splatting using Raw Mesh for Photorealistic Recreation of Architectures
Jul 22, 2024The photorealistic reconstruction and rendering of architectural scenes have extensive applications in industries such as film, games, and transportation. It also plays an important role in urban planning, architectural design, and the city's promotion, especially in protecting historical and cultural relics. The 3D Gaussian Splatting, due to better performance over NeRF, has become a mainstream technology in 3D reconstruction. Its only input is a set of images but it relies heavily on geometric parameters computed by the SfM process. At the same time, there is an existing abundance of raw 3D models, that could inform the structural perception of certain buildings but cannot be applied. In this paper, we propose a straightforward method to harness these raw 3D models to guide 3D Gaussians in capturing the basic shape of the building and improve the visual quality of textures and details when photos are captured non-systematically. This exploration opens up new possibilities for improving the effectiveness of 3D reconstruction techniques in the field of architectural design.