 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Differential and Collision Entropy for Finite-Regime QKD in Hybrid Quantum Noisy Channels
Jan 31, 2026In this work, a comparative study between three fundamental entropic measures, differential entropy, quantum Renyi entropy, and quantum collision entropy for a hybrid quantum channel (HQC) was investigated, where hybrid quantum noise (HQN) is characterized by both discrete and continuous variables (CV) noise components. Using a Gaussian mixture model (GMM) to statistically model the HQN, we construct as well as visualize the corresponding pointwise entropic functions in a given 3D probabilistic landscape. When integrated over the relevant state space, these entropic surfaces yield values of the respective global entropy. Through analytical and numerical evaluation, it is demonstrated that the differential entropy approaches the quantum collision entropy under certain mixing conditions, which aligns with the Renyi entropy for order $α= 2$. Within the HQC framework, the results establish a theoretical and computational equivalence between these measures. This provides a unified perspective on quantifying uncertainty in hybrid quantum communication systems. Extending the analysis to the operational domain of finite key QKD, we demonstrated that the same $10\%$ approximation threshold corresponds to an order-of-magnitude change in Eves success probability and a measurable reduction in the secure key rate.
Grover's Search-Inspired Quantum Reinforcement Learning for Massive MIMO User Scheduling
Jan 28, 2026The efficient user scheduling policy in the massive Multiple Input Multiple Output (mMIMO) system remains a significant challenge in the field of 5G and Beyond 5G (B5G) due to its high computational complexity, scalability, and Channel State Information (CSI) overhead. This paper proposes a novel Grover's search-inspired Quantum Reinforcement Learning (QRL) framework for mMIMO user scheduling. The QRL agent can explore the exponentially large scheduling space effectively by applying Grover's search to the reinforcement learning process. The model is implemented using our designed quantum-gate-based circuit, which imitates the layered architecture of reinforcement learning, where quantum operations act as policy updates and decision-making units. Moreover, the simulation results demonstrate that the proposed method achieves proper convergence and significantly outperforms classical Convolutional Neural Networks (CNN) and Quantum Deep Learning (QDL) benchmarks.
On the Achievable Rate of Satellite Quantum Communication Channel using Deep Autoencoder Gaussian Mixture Model
Jul 31, 2025We present a comparative study of the Gaussian mixture model (GMM) and the Deep Autoencoder Gaussian Mixture Model (DAGMM) for estimating satellite quantum channel capacity, considering hybrid quantum noise (HQN) and transmission constraints. While GMM is simple and interpretable, DAGMM better captures non-linear variations and noise distributions. Simulations show that DAGMM provides tighter capacity bounds and improved clustering. This introduces the Deep Cluster Gaussian Mixture Model (DCGMM) for high-dimensional quantum data analysis in quantum satellite communication.
An Explainable AI Framework for Dynamic Resource Management in Vehicular Network Slicing
Jun 13, 2025Effective resource management and network slicing are essential to meet the diverse service demands of vehicular networks, including Enhanced Mobile Broadband (eMBB) and Ultra-Reliable and Low-Latency Communications (URLLC). This paper introduces an Explainable Deep Reinforcement Learning (XRL) framework for dynamic network slicing and resource allocation in vehicular networks, built upon a near-real-time RAN intelligent controller. By integrating a feature-based approach that leverages Shapley values and an attention mechanism, we interpret and refine the decisions of our reinforcementlearning agents, addressing key reliability challenges in vehicular communication systems. Simulation results demonstrate that our approach provides clear, real-time insights into the resource allocation process and achieves higher interpretability precision than a pure attention mechanism. Furthermore, the Quality of Service (QoS) satisfaction for URLLC services increased from 78.0% to 80.13%, while that for eMBB services improved from 71.44% to 73.21%.
A Hybrid Noise Approach to Modelling of Free-Space Satellite Quantum Communication Channel for Continuous-Variable QKD
Oct 20, 2024



This paper significantly advances the application of Quantum Key Distribution (QKD) in Free- Space Optics (FSO) satellite-based quantum communication. We propose an innovative satellite quantum channel model and derive the secret quantum key distribution rate achievable through this channel. Unlike existing models that approximate the noise in quantum channels as merely Gaussian distributed, our model incorporates a hybrid noise analysis, accounting for both quantum Poissonian noise and classical Additive-White-Gaussian Noise (AWGN). This hybrid approach acknowledges the dual vulnerability of continuous variables (CV) Gaussian quantum channels to both quantum and classical noise, thereby offering a more realistic assessment of the quantum Secret Key Rate (SKR). This paper delves into the variation of SKR with the Signal-to-Noise Ratio (SNR) under various influencing parameters. We identify and analyze critical factors such as reconciliation efficiency, transmission coefficient, transmission efficiency, the quantum Poissonian noise parameter, and the satellite altitude. These parameters are pivotal in determining the SKR in FSO satellite quantum channels, highlighting the challenges of satellitebased quantum communication. Our work provides a comprehensive framework for understanding and optimizing SKR in satellite-based QKD systems, paving the way for more efficient and secure quantum communication networks.
Optimized Resource Allocation for Cloud-Native 6G Networks: Zero-Touch ML Models in Microservices-based VNF Deployments
Oct 09, 2024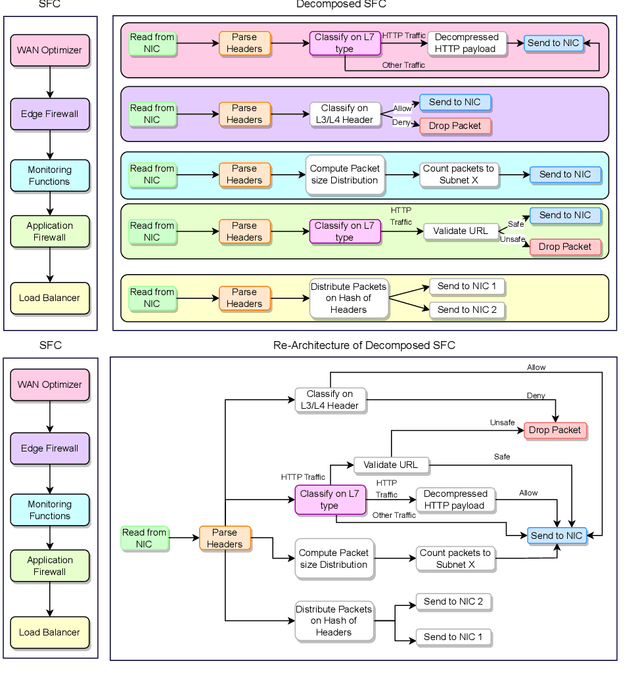
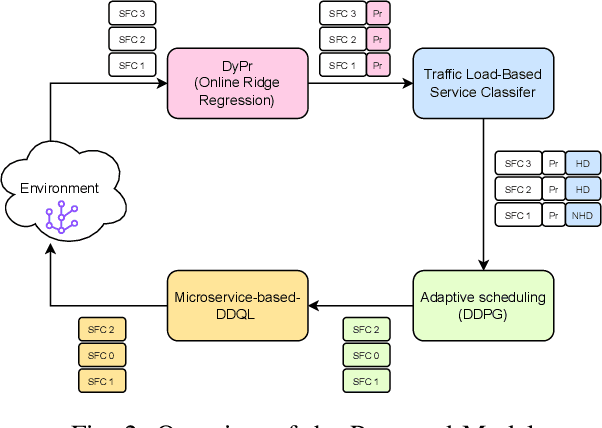
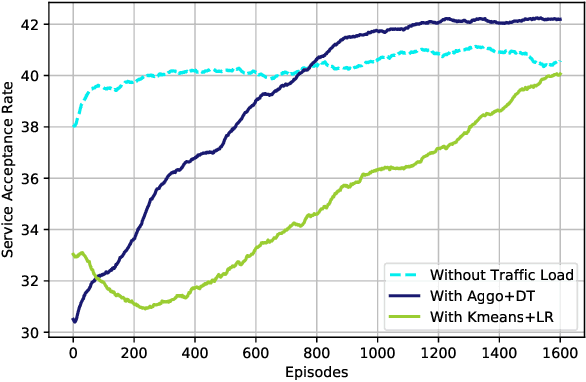
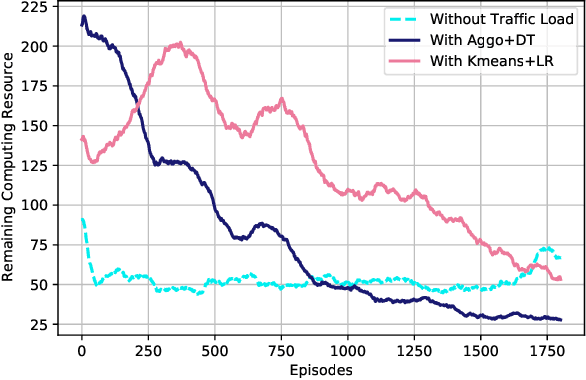
6G, the next generation of mobile networks, is set to offer even higher data rates, ultra-reliability, and lower latency than 5G. New 6G services will increase the load and dynamism of the network. Network Function Virtualization (NFV) aids with this increased load and dynamism by eliminating hardware dependency. It aims to boost the flexibility and scalability of network deployment services by separating network functions from their specific proprietary forms so that they can run as virtual network functions (VNFs) on commodity hardware. It is essential to design an NFV orchestration and management framework to support these services. However, deploying bulky monolithic VNFs on the network is difficult, especially when underlying resources are scarce, resulting in ineffective resource management. To address this, microservices-based NFV approaches are proposed. In this approach, monolithic VNFs are decomposed into micro VNFs, increasing the likelihood of their successful placement and resulting in more efficient resource management. This article discusses the proposed framework for resource allocation for microservices-based services to provide end-to-end Quality of Service (QoS) using the Double Deep Q Learning (DDQL) approach. Furthermore, to enhance this resource allocation approach, we discussed and addressed two crucial sub-problems: the need for a dynamic priority technique and the presence of the low-priority starvation problem. Using the Deep Deterministic Policy Gradient (DDPG) model, an Adaptive Scheduling model is developed that effectively mitigates the starvation problem. Additionally, the impact of incorporating traffic load considerations into deployment and scheduling is thoroughly investigated.
ECG Biometric Authentication Using Self-Supervised Learning for IoT Edge Sensors
Sep 09, 2024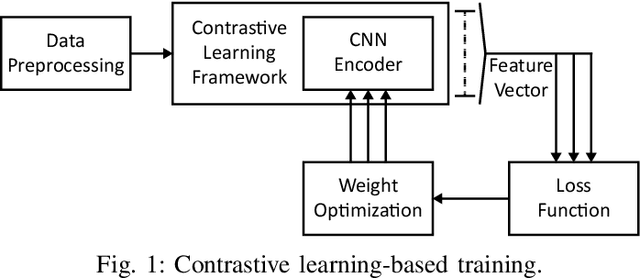
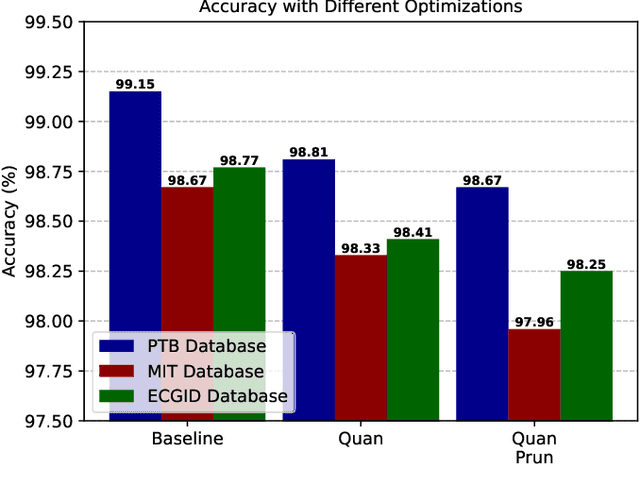
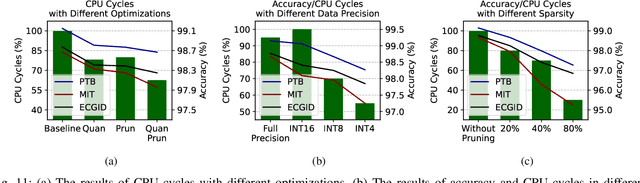
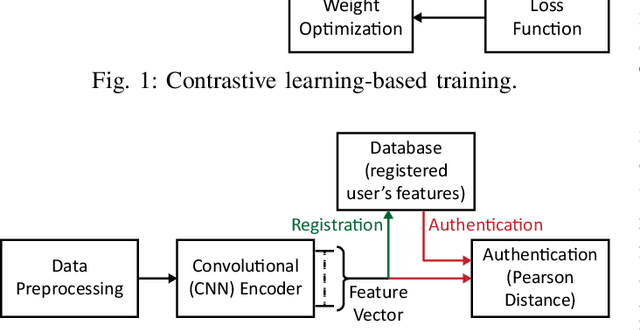
Wearable Internet of Things (IoT) devices are gaining ground for continuous physiological data acquisition and health monitoring. These physiological signals can be used for security applications to achieve continuous authentication and user convenience due to passive data acquisition. This paper investigates an electrocardiogram (ECG) based biometric user authentication system using features derived from the Convolutional Neural Network (CNN) and self-supervised contrastive learning. Contrastive learning enables us to use large unlabeled datasets to train the model and establish its generalizability. We propose approaches enabling the CNN encoder to extract appropriate features that distinguish the user from other subjects. When evaluated using the PTB ECG database with 290 subjects, the proposed technique achieved an authentication accuracy of 99.15%. To test its generalizability, we applied the model to two new datasets, the MIT-BIH Arrhythmia Database and the ECG-ID Database, achieving over 98.5% accuracy without any modifications. Furthermore, we show that repeating the authentication step three times can increase accuracy to nearly 100% for both PTBDB and ECGIDDB. This paper also presents model optimizations for embedded device deployment, which makes the system more relevant to real-world scenarios. To deploy our model in IoT edge sensors, we optimized the model complexity by applying quantization and pruning. The optimized model achieves 98.67% accuracy on PTBDB, with 0.48% accuracy loss and 62.6% CPU cycles compared to the unoptimized model. An accuracy-vs-time-complexity tradeoff analysis is performed, and results are presented for different optimization levels.
Hybrid Quantum Noise Approximation and Pattern Analysis on Parameterized Component Distributions
Sep 07, 2024



Noise is a vital factor in determining the accuracy of processing the information of the quantum channel. One must consider classical noise effects associated with quantum noise sources for more realistic modelling of quantum channels. A hybrid quantum noise model incorporating both quantum Poisson noise and classical additive white Gaussian noise (AWGN) can be interpreted as an infinite mixture of Gaussians with weightage from the Poisson distribution. The entropy measure of this function is difficult to calculate. This research developed how the infinite mixture can be well approximated by a finite mixture distribution depending on the Poisson parametric setting compared to the number of mixture components. The mathematical analysis of the characterization of hybrid quantum noise has been demonstrated based on Gaussian and Poisson parametric analysis. This helps in the pattern analysis of the parametric values of the component distribution, and it also helps in the calculation of hybrid noise entropy to understand hybrid quantum noise better.
A Machine Learning Approach for Optimizing Hybrid Quantum Noise Clusters for Gaussian Quantum Channel Capacity
Apr 13, 2024



This work contributes to the advancement of quantum communication by visualizing hybrid quantum noise in higher dimensions and optimizing the capacity of the quantum channel by using machine learning (ML). Employing the expectation maximization (EM) algorithm, the quantum channel parameters are iteratively adjusted to estimate the channel capacity, facilitating the categorization of quantum noise data in higher dimensions into a finite number of clusters. In contrast to previous investigations that represented the model in lower dimensions, our work describes the quantum noise as a Gaussian Mixture Model (GMM) with mixing weights derived from a Poisson distribution. The objective was to model the quantum noise using a finite mixture of Gaussian components while preserving the mixing coefficients from the Poisson distribution. Approximating the infinite Gaussian mixture with a finite number of components makes it feasible to visualize clusters of quantum noise data without modifying the original probability density function. By implementing the EM algorithm, the research fine-tuned the channel parameters, identified optimal clusters, improved channel capacity estimation, and offered insights into the characteristics of quantum noise within an ML framework.
Unsupervised Pre-Training Using Masked Autoencoders for ECG Analysis
Oct 17, 2023



Unsupervised learning methods have become increasingly important in deep learning due to their demonstrated large utilization of datasets and higher accuracy in computer vision and natural language processing tasks. There is a growing trend to extend unsupervised learning methods to other domains, which helps to utilize a large amount of unlabelled data. This paper proposes an unsupervised pre-training technique based on masked autoencoder (MAE) for electrocardiogram (ECG) signals. In addition, we propose a task-specific fine-tuning to form a complete framework for ECG analysis. The framework is high-level, universal, and not individually adapted to specific model architectures or tasks. Experiments are conducted using various model architectures and large-scale datasets, resulting in an accuracy of 94.39% on the MITDB dataset for ECG arrhythmia classification task. The result shows a better performance for the classification of previously unseen data for the proposed approach compared to fully supervised methods.