 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable AI Framework for Dynamic Resource Management in Vehicular Network Slicing
Jun 13, 2025Effective resource management and network slicing are essential to meet the diverse service demands of vehicular networks, including Enhanced Mobile Broadband (eMBB) and Ultra-Reliable and Low-Latency Communications (URLLC). This paper introduces an Explainable Deep Reinforcement Learning (XRL) framework for dynamic network slicing and resource allocation in vehicular networks, built upon a near-real-time RAN intelligent controller. By integrating a feature-based approach that leverages Shapley values and an attention mechanism, we interpret and refine the decisions of our reinforcementlearning agents, addressing key reliability challenges in vehicular communication systems. Simulation results demonstrate that our approach provides clear, real-time insights into the resource allocation process and achieves higher interpretability precision than a pure attention mechanism. Furthermore, the Quality of Service (QoS) satisfaction for URLLC services increased from 78.0% to 80.13%, while that for eMBB services improved from 71.44% to 73.21%.
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
Feb 27, 2025
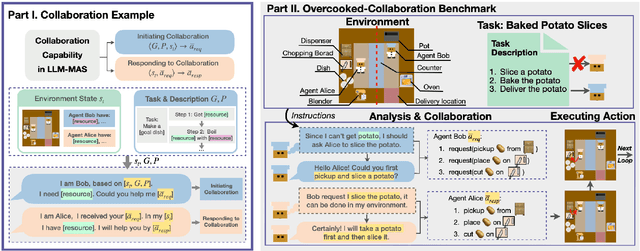

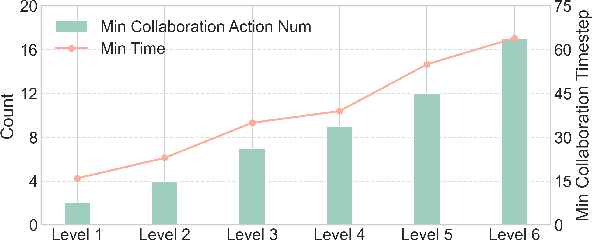
Large language models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-powered Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks from two novel perspectives. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments over 10 popular LLMs and show that, while the LLMs present a strong ability in goal interpretation, there is a significant discrepancy in active collaboration and continuous adaption that are critical for efficiently fulfilling complicated tasks. Notably, we highlight the strengths and weaknesses in LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-sourced benchmark. Environments, 30 open-ended tasks, and an integrated evaluation package are now publicly available at https://github.com/YusaeMeow/Collab-Overcooked.
zkLLM: Zero Knowledge Proofs for Large Language Models
Apr 24, 2024The recent surge in artificial intelligence (AI), characterized by the prominence of large language models (LLMs), has ushered in fundamental transformations across the globe. However, alongside these advancements, concerns surrounding the legitimacy of LLMs have grown, posing legal challenges to their extensive applications. Compounding these concerns, the parameters of LLMs are often treated as intellectual property, restricting direct investigations. In this study, we address a fundamental challenge within the realm of AI legislation: the need to establish the authenticity of outputs generated by LLMs. To tackle this issue, we present zkLLM, which stands as the inaugural specialized zero-knowledge proof tailored for LLMs to the best of our knowledge. Addressing the persistent challenge of non-arithmetic operations in deep learning, we introduce tlookup, a parallelized lookup argument designed for non-arithmetic tensor operations in deep learning, offering a solution with no asymptotic overhead. Furthermore, leveraging the foundation of tlookup, we introduce zkAttn, a specialized zero-knowledge proof crafted for the attention mechanism, carefully balancing considerations of running time, memory usage, and accuracy. Empowered by our fully parallelized CUDA implementation, zkLLM emerges as a significant stride towards achieving efficient zero-knowledge verifiable computations over LLMs. Remarkably, for LLMs boasting 13 billion parameters, our approach enables the generation of a correctness proof for the entire inference process in under 15 minutes. The resulting proof, compactly sized at less than 200 kB, is designed to uphold the privacy of the model parameters, ensuring no inadvertent information leakage.
Learning Correction Errors via Frequency-Self Attention for Blind Image Super-Resolution
Mar 12, 2024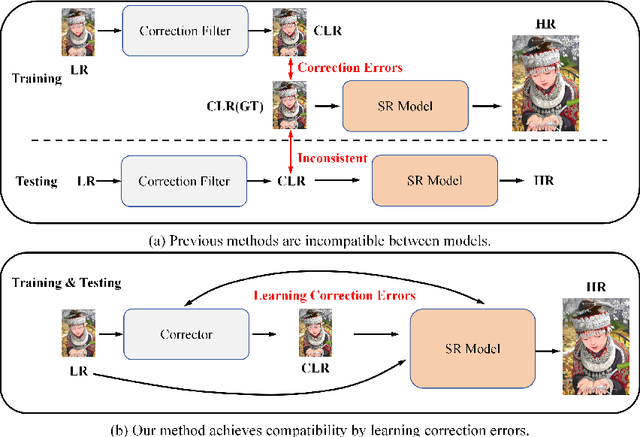

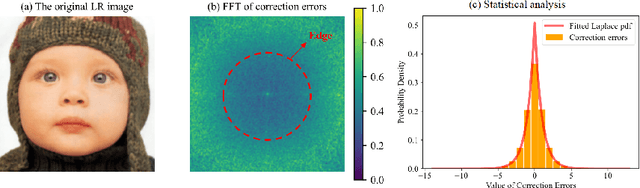
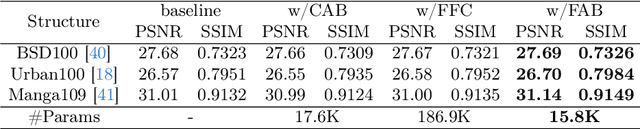
Previous approaches for blind image super-resolution (SR) have relied on degradation estimation to restore high-resolution (HR) images from their low-resolution (LR) counterparts. However, accurate degradation estimation poses significant challenges. The SR model's incompatibility with degradation estimation methods, particularly the Correction Filter, may significantly impair performance as a result of correction errors. In this paper, we introduce a novel blind SR approach that focuses on Learning Correction Errors (LCE). Our method employs a lightweight Corrector to obtain a corrected low-resolution (CLR) image. Subsequently, within an SR network, we jointly optimize SR performance by utilizing both the original LR image and the frequency learning of the CLR image. Additionally, we propose a new Frequency-Self Attention block (FSAB) that enhances the global information utilization ability of Transformer. This block integrates both self-attention and frequency spatial attention mechanisms. Extensive ablation and comparison experiments conducted across various settings demonstrate the superiority of our method in terms of visual quality and accuracy. Our approach effectively addresses the challenges associated with degradation estimation and correction errors, paving the way for more accurate blind image SR.
zkDL: Efficient Zero-Knowledge Proofs of Deep Learning Training
Jul 30, 2023The recent advancements in deep learning have brought about significant changes in various aspects of people's lives. Meanwhile, these rapid developments have raised concerns about the legitimacy of the training process of deep networks. However, to protect the intellectual properties of untrusted AI developers, directly examining the training process by accessing the model parameters and training data by verifiers is often prohibited. In response to this challenge, we present zkDL, an efficient zero-knowledge proof of deep learning training. At the core of zkDL is zkReLU, a specialized zero-knowledge proof protocol with optimized proving time and proof size for the ReLU activation function, a major obstacle in verifiable training due to its non-arithmetic nature. To integrate zkReLU into the proof system for the entire training process, we devise a novel construction of an arithmetic circuit from neural networks. By leveraging the abundant parallel computation resources, this construction reduces proving time and proof sizes by a factor of the network depth. As a result, zkDL enables the generation of complete and sound proofs, taking less than a minute with a size of less than 20 kB per training step, for a 16-layer neural network with 200M parameters, while ensuring the privacy of data and model parameters.