 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Modeling of a Simple-Structured Continuously Variable Transmission Utilizing Shape Memory Alloy Superelasticity for Twisted String Actuator
Dec 23, 2025Twisted String Actuators (TSAs) are widely used in robotics but suffer from a limited range of Transmission Ratio (TR) variation, restricting their efficiency under varying loads.To overcome this, we propose a novel lightweight, simple-structured Continuously Variable Transmission (CVT) mechanism for TSA utilizing Shape Memory Alloy (SMA) superelasticity. The CVT mechanism consists solely of a pair of highly lightweight superelastic SMA rods connecting the ends of twisted strings. These rods deform under external loads, adjusting the inter-string distance to enable continuous TR variation.We develop a comprehensive theoretical model that integrates three critical nonlinearities
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025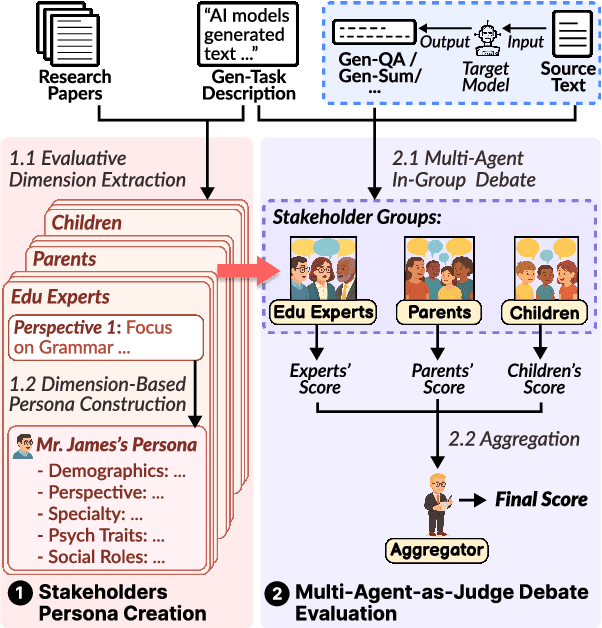



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
SMAR: Soft Modality-Aware Routing Strategy for MoE-based Multimodal Large Language Models Preserving Language Capabilities
Jun 06, 2025Mixture of Experts (MoE) architectures have become a key approach for scaling large language models, with growing interest in extending them to multimodal tasks. Existing methods to build multimodal MoE models either incur high training costs or suffer from degraded language capabilities when adapting pretrained models. To address this, we propose Soft ModalityAware Routing (SMAR), a novel regularization technique that uses Kullback Leibler divergence to control routing probability distributions across modalities, encouraging expert specialization without modifying model architecture or heavily relying on textual data. Experiments on visual instruction tuning show that SMAR preserves language ability at 86.6% retention with only 2.5% pure text, outperforming baselines while maintaining strong multimodal performance. Our approach offers a practical and efficient solution to balance modality differentiation and language capabilities in multimodal MoE models.
Enhancing Complex Instruction Following for Large Language Models with Mixture-of-Contexts Fine-tuning
May 17, 2025Large language models (LLMs) exhibit remarkable capabilities in handling natural language tasks; however, they may struggle to consistently follow complex instructions including those involve multiple constraints. Post-training LLMs using supervised fine-tuning (SFT) is a standard approach to improve their ability to follow instructions. In addressing complex instruction following, existing efforts primarily focus on data-driven methods that synthesize complex instruction-output pairs for SFT. However, insufficient attention allocated to crucial sub-contexts may reduce the effectiveness of SFT. In this work, we propose transforming sequentially structured input instruction into multiple parallel instructions containing subcontexts. To support processing this multi-input, we propose MISO (Multi-Input Single-Output), an extension to currently dominant decoder-only transformer-based LLMs. MISO introduces a mixture-of-contexts paradigm that jointly considers the overall instruction-output alignment and the influence of individual sub-contexts to enhance SFT effectiveness. We apply MISO fine-tuning to complex instructionfollowing datasets and evaluate it with standard LLM inference. Empirical results demonstrate the superiority of MISO as a fine-tuning method for LLMs, both in terms of effectiveness in complex instruction-following scenarios and its potential for training efficiency.
FreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
Apr 22, 2025Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance, yet existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive subject-specific optimization, while zero-shot methods fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor employs semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated image. Additionally, our framework incorporates a novel noise initialization strategy to preserve geometry priors of reference subjects for robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
Robot Skin with Touch and Bend Sensing using Electrical Impedance Tomography
Mar 17, 2025Flexible electronic skins that simultaneously sense touch and bend are desired in several application areas, such as to cover articulated robot structures. This paper introduces a flexible tactile sensor based on Electrical Impedance Tomography (EIT), capable of simultaneously detecting and measuring contact forces and flexion of the sensor. The sensor integrates a magnetic hydrogel composite and utilizes EIT to reconstruct internal conductivity distributions. Real-time estimation is achieved through the one-step Gauss-Newton method, which dynamically updates reference voltages to accommodate sensor deformation. A convolutional neural network is employed to classify interactions, distinguishing between touch, bending, and idle states using pre-reconstructed images. Experimental results demonstrate an average touch localization error of 5.4 mm (SD 2.2 mm) and average bending angle estimation errors of 1.9$^\circ$ (SD 1.6$^\circ$). The proposed adaptive reference method effectively distinguishes between single- and multi-touch scenarios while compensating for deformation effects. This makes the sensor a promising solution for multimodal sensing in robotics and human-robot collaboration.
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
Feb 27, 2025
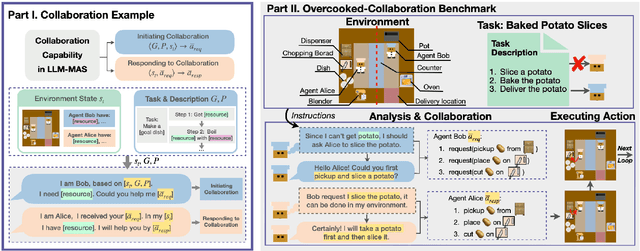

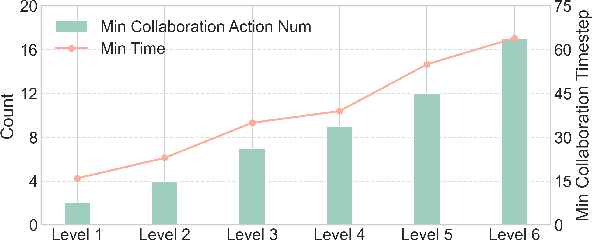
Large language models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-powered Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks from two novel perspectives. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments over 10 popular LLMs and show that, while the LLMs present a strong ability in goal interpretation, there is a significant discrepancy in active collaboration and continuous adaption that are critical for efficiently fulfilling complicated tasks. Notably, we highlight the strengths and weaknesses in LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-sourced benchmark. Environments, 30 open-ended tasks, and an integrated evaluation package are now publicly available at https://github.com/YusaeMeow/Collab-Overcooked.
Circuit-tuning: A Mechanistic Approach for Identifying Parameter Redundancy and Fine-tuning Neural Networks
Feb 10, 2025The study of mechanistic interpretability aims to reverse-engineer a model to explain its behaviors. While recent studies have focused on the static mechanism of a certain behavior, the training dynamics inside a model remain to be explored. In this work, we develop an interpretable method for fine-tuning and reveal the mechanism behind learning. We first propose the concept of node redundancy as an extension of intrinsic dimension and explain the idea behind circuit discovery from a fresh view. Based on the theory, we propose circuit-tuning, a two-stage algorithm that iteratively performs circuit discovery to mask out irrelevant edges and updates the remaining parameters responsible for a specific task. Experiments show that our method not only improves performance on a wide range of tasks but is also scalable while preserving general capabilities. We visualize and analyze the circuits before, during, and after fine-tuning, providing new insights into the self-organization mechanism of a neural network in the learning process.
Controlled Low-Rank Adaptation with Subspace Regularization for Continued Training on Large Language Models
Oct 22, 2024



Large language models (LLMs) exhibit remarkable capabilities in natural language processing but face catastrophic forgetting when learning new tasks, where adaptation to a new domain leads to a substantial decline in performance on previous tasks. In this paper, we propose Controlled LoRA (CLoRA), a subspace regularization method on LoRA structure. Aiming to reduce the scale of output change while introduce minimal constraint on model capacity, CLoRA imposes constraint on the direction of updating matrix null space. Experimental results on commonly used LLM finetuning tasks reveal that CLoRA significantly outperforms existing LoRA subsequent methods on both in-domain and outdomain evaluations, highlighting the superority of CLoRA as a effective parameter-efficient finetuning method with catastrophic forgetting mitigating. Further investigation for model parameters indicates that CLoRA effectively balances the trade-off between model capacity and degree of forgetting.
Concept Conductor: Orchestrating Multiple Personalized Concepts in Text-to-Image Synthesis
Aug 07, 2024
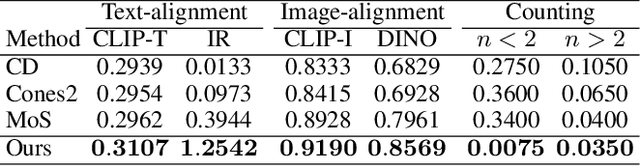
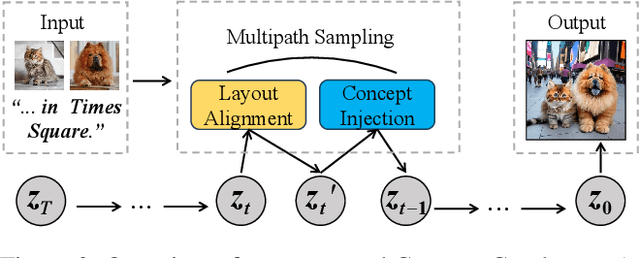
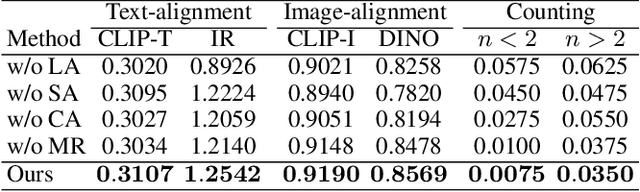
The customization of text-to-image models has seen significant advancements, yet generating multiple personalized concepts remains a challenging task. Current methods struggle with attribute leakage and layout confusion when handling multiple concepts, leading to reduced concept fidelity and semantic consistency. In this work, we introduce a novel training-free framework, Concept Conductor, designed to ensure visual fidelity and correct layout in multi-concept customization. Concept Conductor isolates the sampling processes of multiple custom models to prevent attribute leakage between different concepts and corrects erroneous layouts through self-attention-based spatial guidance. Additionally, we present a concept injection technique that employs shape-aware masks to specify the generation area for each concept. This technique injects the structure and appearance of personalized concepts through feature fusion in the attention layers, ensuring harmony in the final image. Extensive qualitative and quantitative experiments demonstrate that Concept Conductor can consistently generate composite images with accurate layouts while preserving the visual details of each concept. Compared to existing baselines, Concept Conductor shows significant performance improvements. Our method supports the combination of any number of concepts and maintains high fidelity even when dealing with visually similar concepts. The code and models are available at https://github.com/Nihukat/Concept-Conductor.