 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeHarness: Lifecycle-Integrated Security Architecture for LLM-based Agent Deployment
Apr 15, 2026The performance of large language model (LLM) agents depends critically on the execution harness, the system layer that orchestrates tool use, context management, and state persistence. Yet this same architectural centrality makes the harness a high-value attack surface: a single compromise at the harness level can cascade through the entire execution pipeline. We observe that existing security approaches suffer from structural mismatch, leaving them blind to harness-internal state and unable to coordinate across the different phases of agent operation. In this paper, we introduce \safeharness{}, a security architecture in which four proposed defense layers are woven directly into the agent lifecycle to address above significant limitations: adversarial context filtering at input processing, tiered causal verification at decision making, privilege-separated tool control at action execution, and safe rollback with adaptive degradation at state update. The proposed cross-layer mechanisms tie these layers together, escalating verification rigor, triggering rollbacks, and tightening tool privileges whenever sustained anomalies are detected. We evaluate \safeharness{} on benchmark datasets across diverse harness configurations, comparing against four security baselines under five attack scenarios spanning six threat categories. Compared to the unprotected baseline, \safeharness{} achieves an average reduction of approximately 38\% in UBR and 42\% in ASR, substantially lowering both the unsafe behavior rate and the attack success rate while preserving core task utility.
CIA: Inferring the Communication Topology from LLM-based Multi-Agent Systems
Apr 14, 2026LLM-based Multi-Agent Systems (MAS) have demonstrated remarkable capabilities in solving complex tasks. Central to MAS is the communication topology which governs how agents exchange information internally. Consequently, the security of communication topologies has attracted increasing attention. In this paper, we investigate a critical privacy risk: MAS communication topologies can be inferred under a restrictive black-box setting, exposing system vulnerabilities and posing significant intellectual property threats. To explore this risk, we propose Communication Inference Attack (CIA), a novel attack that constructs new adversarial queries to induce intermediate agents' reasoning outputs and models their semantic correlations through the proposed global bias disentanglement and LLM-guided weak supervision. Extensive experiments on MAS with optimized communication topologies demonstrate the effectiveness of CIA, achieving an average AUC of 0.87 and a peak AUC of up to 0.99, thereby revealing the substantial privacy risk in MAS.
Nodule-Aligned Latent Space Learning with LLM-Driven Multimodal Diffusion for Lung Nodule Progression Prediction
Mar 16, 2026Early diagnosis of lung cancer is challenging due to biological uncertainty and the limited understanding of the biological mechanisms driving nodule progression. To address this, we propose Nodule-Aligned Multimodal (Latent) Diffusion (NAMD), a novel framework that predicts lung nodule progression by generating 1-year follow-up nodule computed tomography images with baseline scans and the patient's and nodule's Electronic Health Record (EHR). NAMD introduces a nodule-aligned latent space, where distances between latents directly correspond to changes in nodule attributes, and utilizes an LLM-driven control mechanism to condition the diffusion backbone on patient data. On the National Lung Screening Trial (NLST) dataset, our method synthesizes follow-up nodule images that achieve an AUROC of 0.805 and an AUPRC of 0.346 for lung nodule malignancy prediction, significantly outperforming both baseline scans and state-of-the-art synthesis methods, while closely approaching the performance of real follow-up scans (AUROC: 0.819, AUPRC: 0.393). These results demonstrate that NAMD captures clinically relevant features of lung nodule progression, facilitating earlier and more accurate diagnosis.
Hard Constraints Meet Soft Generation: Guaranteed Feasibility for LLM-based Combinatorial Optimization
Feb 01, 2026Large language models (LLMs) have emerged as promising general-purpose solvers for combinatorial optimization (CO), yet they fundamentally lack mechanisms to guarantee solution feasibility which is critical for real-world deployment. In this work, we introduce FALCON, a framework that ensures 100\% feasibility through three key innovations: (i) \emph{grammar-constrained decoding} enforces syntactic validity, (ii) a \emph{feasibility repair layer} corrects semantic constraint violations, and (iii) \emph{adaptive Best-of-$N$ sampling} allocates inference compute efficiently. To train the underlying LLM, we introduce the Best-anchored Objective-guided Preference Optimization (BOPO) in LLM training, which weights preference pairs by their objective gap, providing dense supervision without human labels. Theoretically, we prove convergence for BOPO and provide bounds on repair-induced quality loss. Empirically, across seven NP-hard CO problems, FALCON achieves perfect feasibility while matching or exceeding the solution quality of state-of-the-art neural and LLM-based solvers.
MuVaC: AVariational Causal Framework for Multimodal Sarcasm Understanding in Dialogues
Jan 28, 2026The prevalence of sarcasm in multimodal dialogues on the social platforms presents a crucial yet challenging task for understanding the true intent behind online content. Comprehensive sarcasm analysis requires two key aspects: Multimodal Sarcasm Detection (MSD) and Multimodal Sarcasm Explanation (MuSE). Intuitively, the act of detection is the result of the reasoning process that explains the sarcasm. Current research predominantly focuses on addressing either MSD or MuSE as a single task. Even though some recent work has attempted to integrate these tasks, their inherent causal dependency is often overlooked. To bridge this gap, we propose MuVaC, a variational causal inference framework that mimics human cognitive mechanisms for understanding sarcasm, enabling robust multimodal feature learning to jointly optimize MSD and MuSE. Specifically, we first model MSD and MuSE from the perspective of structural causal models, establishing variational causal pathways to define the objectives for joint optimization. Next, we design an alignment-then-fusion approach to integrate multimodal features, providing robust fusion representations for sarcasm detection and explanation generation. Finally, we enhance the reasoning trustworthiness by ensuring consistency between detection results and explanations. Experimental results demonstrate the superiority of MuVaC in public datasets, offering a new perspective for understanding multimodal sarcasm.
Correcting False Alarms from Unseen: Adapting Graph Anomaly Detectors at Test Time
Nov 10, 2025Graph anomaly detection (GAD), which aims to detect outliers in graph-structured data, has received increasing research attention recently. However, existing GAD methods assume identical training and testing distributions, which is rarely valid in practice. In real-world scenarios, unseen but normal samples may emerge during deployment, leading to a normality shift that degrades the performance of GAD models trained on the original data. Through empirical analysis, we reveal that the degradation arises from (1) semantic confusion, where unseen normal samples are misinterpreted as anomalies due to their novel patterns, and (2) aggregation contamination, where the representations of seen normal nodes are distorted by unseen normals through message aggregation. While retraining or fine-tuning GAD models could be a potential solution to the above challenges, the high cost of model retraining and the difficulty of obtaining labeled data often render this approach impractical in real-world applications. To bridge the gap, we proposed a lightweight and plug-and-play Test-time adaptation framework for correcting Unseen Normal pattErns (TUNE) in GAD. To address semantic confusion, a graph aligner is employed to align the shifted data to the original one at the graph attribute level. Moreover, we utilize the minimization of representation-level shift as a supervision signal to train the aligner, which leverages the estimated aggregation contamination as a key indicator of normality shift. Extensive experiments on 10 real-world datasets demonstrate that TUNE significantly enhances the generalizability of pre-trained GAD models to both synthetic and real unseen normal patterns.
Graph Wave Networks
May 26, 2025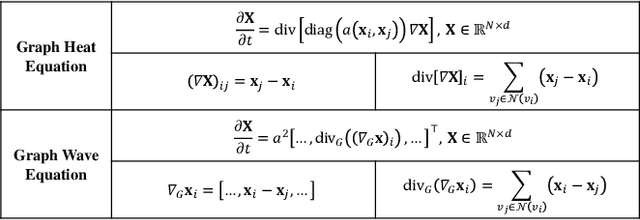
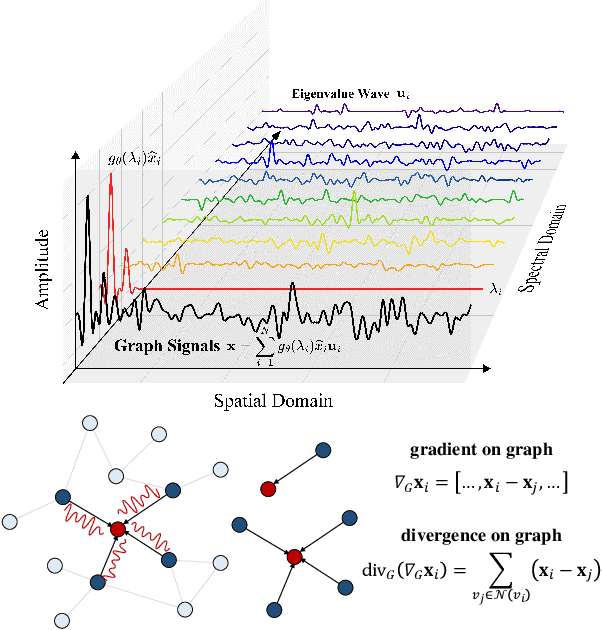
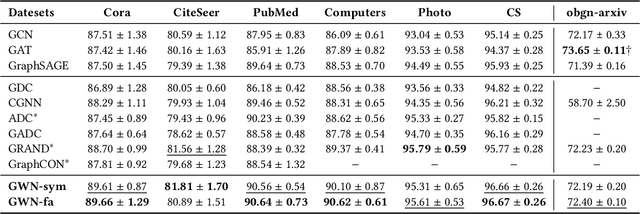
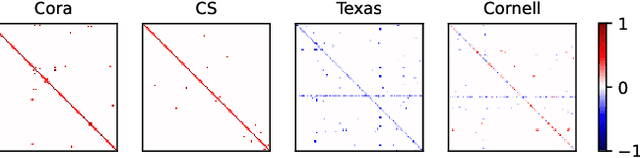
Dynamics modeling has been introduced as a novel paradigm in message passing (MP) of graph neural networks (GNNs). Existing methods consider MP between nodes as a heat diffusion process, and leverage heat equation to model the temporal evolution of nodes in the embedding space. However, heat equation can hardly depict the wave nature of graph signals in graph signal processing. Besides, heat equation is essentially a partial differential equation (PDE) involving a first partial derivative of time, whose numerical solution usually has low stability, and leads to inefficient model training. In this paper, we would like to depict more wave details in MP, since graph signals are essentially wave signals that can be seen as a superposition of a series of waves in the form of eigenvector. This motivates us to consider MP as a wave propagation process to capture the temporal evolution of wave signals in the space. Based on wave equation in physics, we innovatively develop a graph wave equation to leverage the wave propagation on graphs. In details, we demonstrate that the graph wave equation can be connected to traditional spectral GNNs, facilitating the design of graph wave networks based on various Laplacians and enhancing the performance of the spectral GNNs. Besides, the graph wave equation is particularly a PDE involving a second partial derivative of time, which has stronger stability on graphs than the heat equation that involves a first partial derivative of time. Additionally, we theoretically prove that the numerical solution derived from the graph wave equation are constantly stable, enabling to significantly enhance model efficiency while ensuring its performance. Extensive experiments show that GWNs achieve SOTA and efficient performance on benchmark datasets, and exhibit outstanding performance in addressing challenging graph problems, such as over-smoothing and heterophily.
* 15 pages, 8 figures, published to WWW 2025
Multi-Modal Brain Tumor Segmentation via 3D Multi-Scale Self-attention and Cross-attention
Apr 12, 2025Due to the success of CNN-based and Transformer-based models in various computer vision tasks, recent works study the applicability of CNN-Transformer hybrid architecture models in 3D multi-modality medical segmentation tasks. Introducing Transformer brings long-range dependent information modeling ability in 3D medical images to hybrid models via the self-attention mechanism. However, these models usually employ fixed receptive fields of 3D volumetric features within each self-attention layer, ignoring the multi-scale volumetric lesion features. To address this issue, we propose a CNN-Transformer hybrid 3D medical image segmentation model, named TMA-TransBTS, based on an encoder-decoder structure. TMA-TransBTS realizes simultaneous extraction of multi-scale 3D features and modeling of long-distance dependencies by multi-scale division and aggregation of 3D tokens in a self-attention layer. Furthermore, TMA-TransBTS proposes a 3D multi-scale cross-attention module to establish a link between the encoder and the decoder for extracting rich volume representations by exploiting the mutual attention mechanism of cross-attention and multi-scale aggregation of 3D tokens. Extensive experimental results on three public 3D medical segmentation datasets show that TMA-TransBTS achieves higher averaged segmentation results than previous state-of-the-art CNN-based 3D methods and CNN-Transform hybrid 3D methods for the segmentation of 3D multi-modality brain tumors.
Multi-modal and Multi-view Fundus Image Fusion for Retinopathy Diagnosis via Multi-scale Cross-attention and Shifted Window Self-attention
Apr 12, 2025



The joint interpretation of multi-modal and multi-view fundus images is critical for retinopathy prevention, as different views can show the complete 3D eyeball field and different modalities can provide complementary lesion areas. Compared with single images, the sequence relationships in multi-modal and multi-view fundus images contain long-range dependencies in lesion features. By modeling the long-range dependencies in these sequences, lesion areas can be more comprehensively mined, and modality-specific lesions can be detected. To learn the long-range dependency relationship and fuse complementary multi-scale lesion features between different fundus modalities, we design a multi-modal fundus image fusion method based on multi-scale cross-attention, which solves the static receptive field problem in previous multi-modal medical fusion methods based on attention. To capture multi-view relative positional relationships between different views and fuse comprehensive lesion features between different views, we design a multi-view fundus image fusion method based on shifted window self-attention, which also solves the computational complexity of the multi-view fundus fusion method based on self-attention is quadratic to the size and number of multi-view fundus images. Finally, we design a multi-task retinopathy diagnosis framework to help ophthalmologists reduce workload and improve diagnostic accuracy by combining the proposed two fusion methods. The experimental results of retinopathy classification and report generation tasks indicate our method's potential to improve the efficiency and reliability of retinopathy diagnosis in clinical practice, achieving a classification accuracy of 82.53\% and a report generation BlEU-1 of 0.543.
A Two-Stage Pretraining-Finetuning Framework for Treatment Effect Estimation with Unmeasured Confounding
Jan 15, 2025

Estimating the conditional average treatment effect (CATE) from observational data plays a crucial role in areas such as e-commerce, healthcare, and economics. Existing studies mainly rely on the strong ignorability assumption that there are no unmeasured confounders, whose presence cannot be tested from observational data and can invalidate any causal conclusion. In contrast, data collected from randomized controlled trials (RCT) do not suffer from confounding, but are usually limited by a small sample size. In this paper, we propose a two-stage pretraining-finetuning (TSPF) framework using both large-scale observational data and small-scale RCT data to estimate the CATE in the presence of unmeasured confounding. In the first stage, a foundational representation of covariates is trained to estimate counterfactual outcomes through large-scale observational data. In the second stage, we propose to train an augmented representation of the covariates, which is concatenated to the foundational representation obtained in the first stage to adjust for the unmeasured confounding. To avoid overfitting caused by the small-scale RCT data in the second stage, we further propose a partial parameter initialization approach, rather than training a separate network. The superiority of our approach is validated on two public datasets with extensive experiments. The code is available at https://github.com/zhouchuanCN/KDD25-TSPF.