 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratising Clinical AI through Dataset Condensation for Classical Clinical Models
Mar 10, 2026Dataset condensation (DC) learns a compact synthetic dataset that enables models to match the performance of full-data training, prioritising utility over distributional fidelity. While typically explored for computational efficiency, DC also holds promise for healthcare data democratisation, especially when paired with differential privacy, allowing synthetic data to serve as a safe alternative to real records. However, existing DC methods rely on differentiable neural networks, limiting their compatibility with widely used clinical models such as decision trees and Cox regression. We address this gap using a differentially private, zero-order optimisation framework that extends DC to non-differentiable models using only function evaluations. Empirical results across six datasets, including both classification and survival tasks, show that the proposed method produces condensed datasets that preserve model utility while providing effective differential privacy guarantees - enabling model-agnostic data sharing for clinical prediction tasks without exposing sensitive patient information.
DynaGraph: Interpretable Multi-Label Prediction from EHRs via Dynamic Graph Learning and Contrastive Augmentation
Mar 28, 2025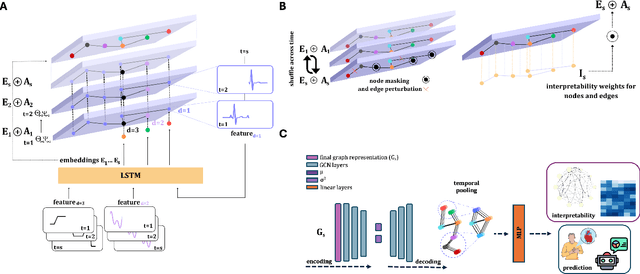
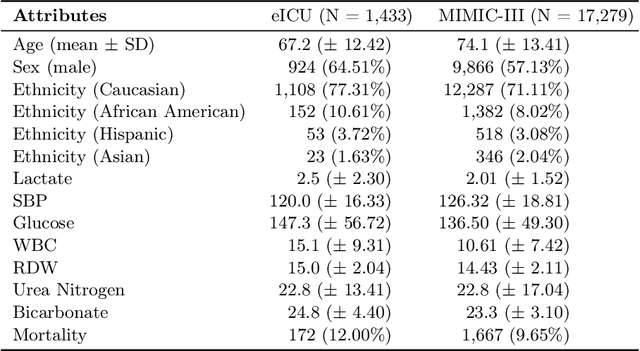
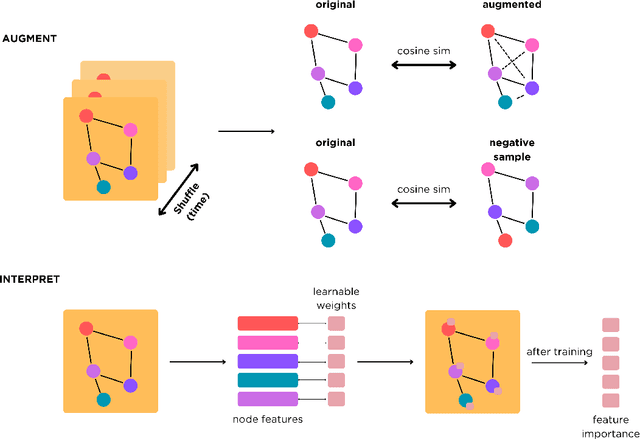
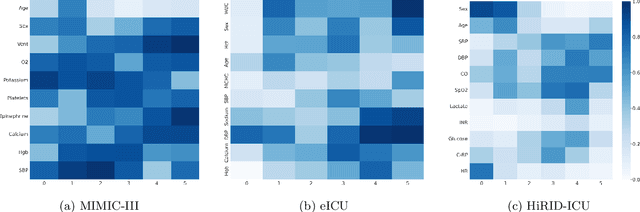
Learning from longitudinal electronic health records is limited if it does not capture the temporal trajectories of the patient's state in a clinical setting. Graph models allow us to capture the hidden dependencies of the multivariate time-series when the graphs are constructed in a similar dynamic manner. Previous dynamic graph models require a pre-defined and/or static graph structure, which is unknown in most cases, or they only capture the spatial relations between the features. Furthermore in healthcare, the interpretability of the model is an essential requirement to build trust with clinicians. In addition to previously proposed attention mechanisms, there has not been an interpretable dynamic graph framework for data from multivariate electronic health records (EHRs). Here, we propose DynaGraph, an end-to-end interpretable contrastive graph model that learns the dynamics of multivariate time-series EHRs as part of optimisation. We validate our model in four real-world clinical datasets, ranging from primary care to secondary care settings with broad demographics, in challenging settings where tasks are imbalanced and multi-labelled. Compared to state-of-the-art models, DynaGraph achieves significant improvements in balanced accuracy and sensitivity over the nearest complex competitors in time-series or dynamic graph modelling across three ICU and one primary care datasets. Through a pseudo-attention approach to graph construction, our model also indicates the importance of clinical covariates over time, providing means for clinical validation.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
Efficient Task Grouping Through Samplewise Optimisation Landscape Analysis
Dec 05, 2024Shared training approaches, such as multi-task learning (MTL) and gradient-based meta-learning, are widely used in various machine learning applications, but they often suffer from negative transfer, leading to performance degradation in specific tasks. While several optimisation techniques have been developed to mitigate this issue for pre-selected task cohorts, identifying optimal task combinations for joint learning - known as task grouping - remains underexplored and computationally challenging due to the exponential growth in task combinations and the need for extensive training and evaluation cycles. This paper introduces an efficient task grouping framework designed to reduce these overwhelming computational demands of the existing methods. The proposed framework infers pairwise task similarities through a sample-wise optimisation landscape analysis, eliminating the need for the shared model training required to infer task similarities in existing methods. With task similarities acquired, a graph-based clustering algorithm is employed to pinpoint near-optimal task groups, providing an approximate yet efficient and effective solution to the originally NP-hard problem. Empirical assessments conducted on 8 different datasets highlight the effectiveness of the proposed framework, revealing a five-fold speed enhancement compared to previous state-of-the-art methods. Moreover, the framework consistently demonstrates comparable performance, confirming its remarkable efficiency and effectiveness in task grouping.
GNNEvaluator: Evaluating GNN Performance On Unseen Graphs Without Labels
Oct 26, 2023



Evaluating the performance of graph neural networks (GNNs) is an essential task for practical GNN model deployment and serving, as deployed GNNs face significant performance uncertainty when inferring on unseen and unlabeled test graphs, due to mismatched training-test graph distributions. In this paper, we study a new problem, GNN model evaluation, that aims to assess the performance of a specific GNN model trained on labeled and observed graphs, by precisely estimating its performance (e.g., node classification accuracy) on unseen graphs without labels. Concretely, we propose a two-stage GNN model evaluation framework, including (1) DiscGraph set construction and (2) GNNEvaluator training and inference. The DiscGraph set captures wide-range and diverse graph data distribution discrepancies through a discrepancy measurement function, which exploits the outputs of GNNs related to latent node embeddings and node class predictions. Under the effective training supervision from the DiscGraph set, GNNEvaluator learns to precisely estimate node classification accuracy of the to-be-evaluated GNN model and makes an accurate inference for evaluating GNN model performance. Extensive experiments on real-world unseen and unlabeled test graphs demonstrate the effectiveness of our proposed method for GNN model evaluation.
A Brief Review of Hypernetworks in Deep Learning
Jun 12, 2023Hypernetworks, or hypernets in short, are neural networks that generate weights for another neural network, known as the target network. They have emerged as a powerful deep learning technique that allows for greater flexibility, adaptability, faster training, information sharing, and model compression etc. Hypernets have shown promising results in a variety of deep learning problems, including continual learning, causal inference, transfer learning, weight pruning, uncertainty quantification, zero-shot learning, natural language processing, and reinforcement learning etc. Despite their success across different problem settings, currently, there is no review available to inform the researchers about the developments and help in utilizing hypernets. To fill this gap, we review the progress in hypernets. We present an illustrative example to train deep neural networks using hypernets and propose to categorize hypernets on five criteria that affect the design of hypernets as inputs, outputs, variability of inputs and outputs, and architecture of hypernets. We also review applications of hypernets across different deep learning problem settings. Finally, we discuss the challenges and future directions that remain under-explored in the field of hypernets. We believe that hypernetworks have the potential to revolutionize the field of deep learning. They offer a new way to design and train neural networks, and they have the potential to improve the performance of deep learning models on a variety of tasks. Through this review, we aim to inspire further advancements in deep learning through hypernetworks.
Dynamic Inter-treatment Information Sharing for Heterogeneous Treatment Effects Estimation
May 25, 2023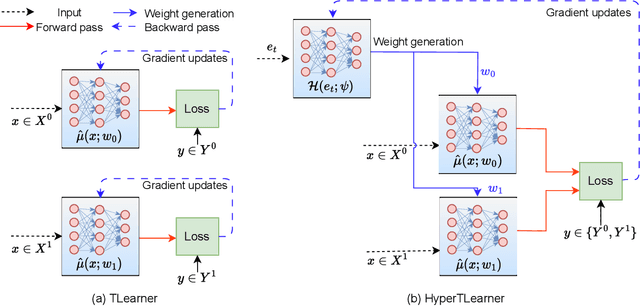
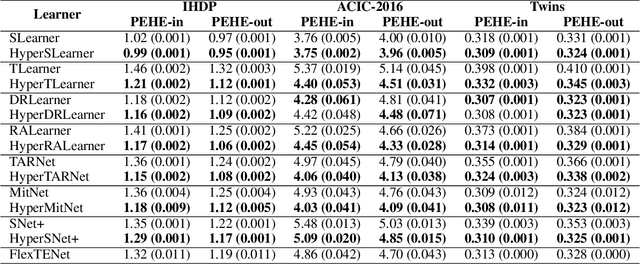
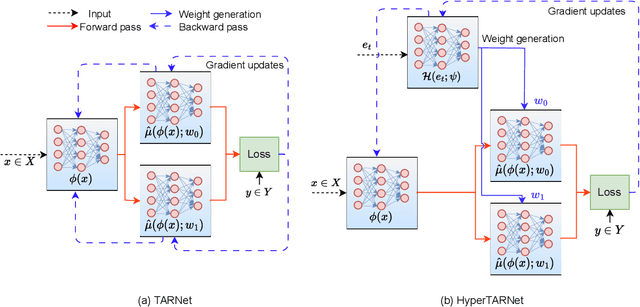
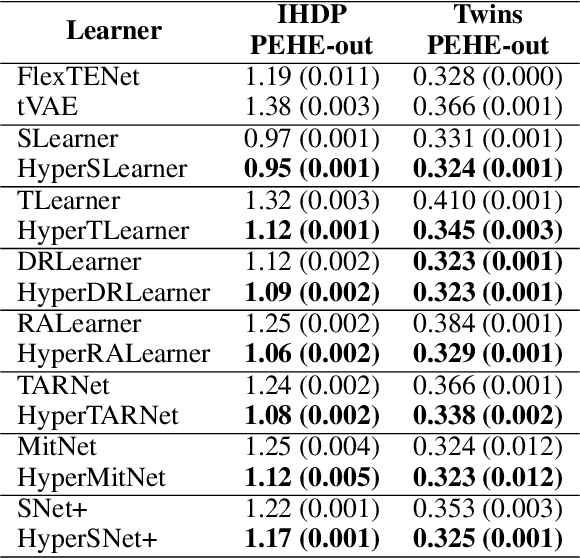
Existing heterogeneous treatment effects learners, also known as conditional average treatment effects (CATE) learners, lack a general mechanism for end-to-end inter-treatment information sharing, and data have to be split among potential outcome functions to train CATE learners which can lead to biased estimates with limited observational datasets. To address this issue, we propose a novel deep learning-based framework to train CATE learners that facilitates dynamic end-to-end information sharing among treatment groups. The framework is based on \textit{soft weight sharing} of \textit{hypernetworks}, which offers advantages such as parameter efficiency, faster training, and improved results. The proposed framework complements existing CATE learners and introduces a new class of uncertainty-aware CATE learners that we refer to as \textit{HyperCATE}. We develop HyperCATE versions of commonly used CATE learners and evaluate them on IHDP, ACIC-2016, and Twins benchmarks. Our experimental results show that the proposed framework improves the CATE estimation error via counterfactual inference, with increasing effectiveness for smaller datasets.
Adversarial De-confounding in Individualised Treatment Effects Estimation
Oct 19, 2022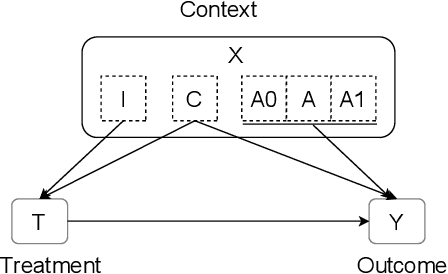
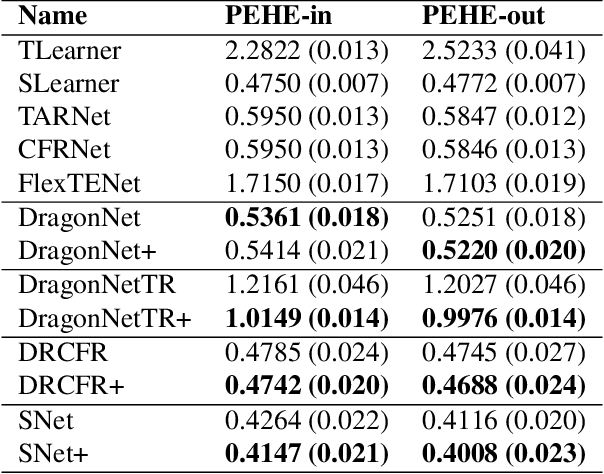
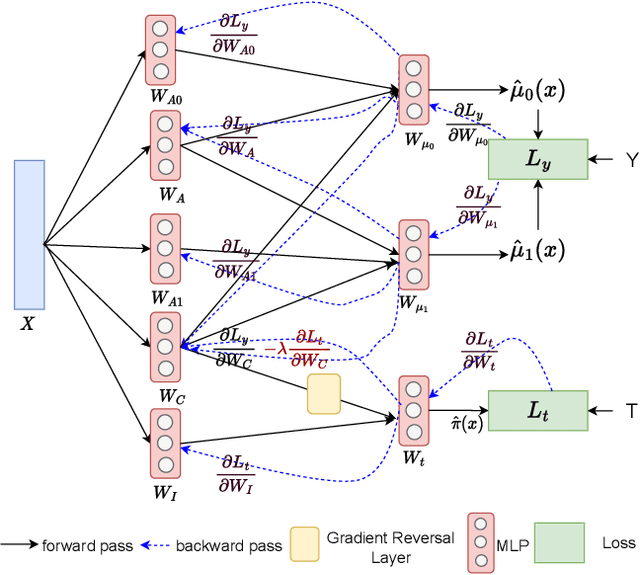
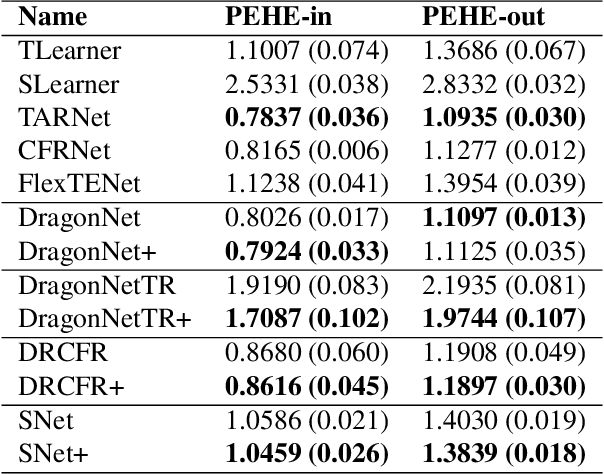
Observational studies have recently received significant attention from the machine learning community due to the increasingly available non-experimental observational data and the limitations of the experimental studies, such as considerable cost, impracticality, small and less representative sample sizes, etc. In observational studies, de-confounding is a fundamental problem of individualised treatment effects (ITE) estimation. This paper proposes disentangled representations with adversarial training to selectively balance the confounders in the binary treatment setting for the ITE estimation. The adversarial training of treatment policy selectively encourages treatment-agnostic balanced representations for the confounders and helps to estimate the ITE in the observational studies via counterfactual inference. Empirical results on synthetic and real-world datasets, with varying degrees of confounding, prove that our proposed approach improves the state-of-the-art methods in achieving lower error in the ITE estimation.
Deep Learning Approach on Information Diffusion in Heterogeneous Networks
Feb 23, 2019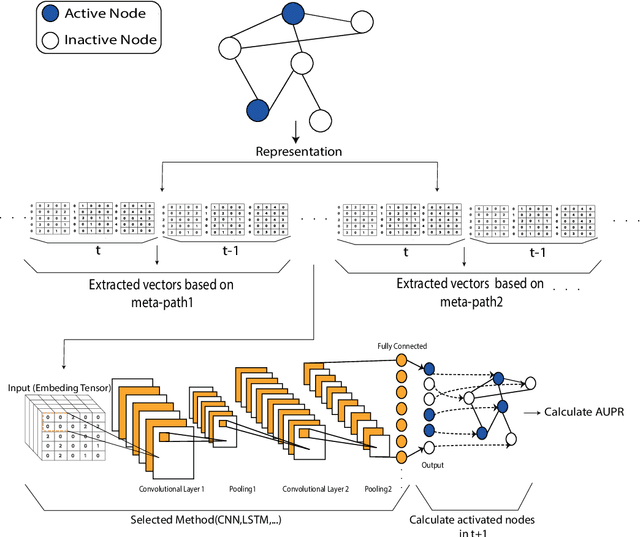
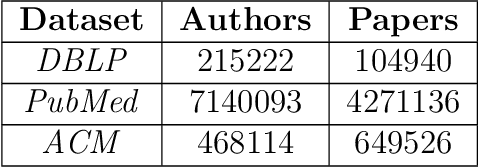
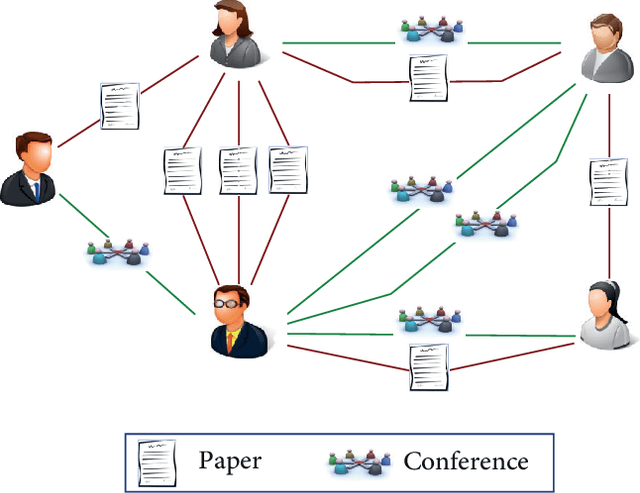
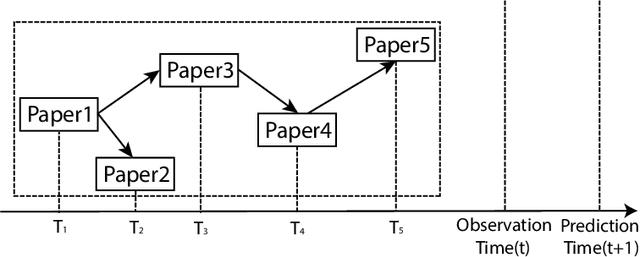
There are many real-world knowledge based networked systems with multi-type interacting entities that can be regarded as heterogeneous networks including human connections and biological evolutions. One of the main issues in such networks is to predict information diffusion such as shape, growth and size of social events and evolutions in the future. While there exist a variety of works on this topic mainly using a threshold-based approach, they suffer from the local viewpoint on the network and sensitivity to the threshold parameters. In this paper, information diffusion is considered through a latent representation learning of the heterogeneous networks to encode in a deep learning model. To this end, we propose a novel meta-path representation learning approach, Heterogeneous Deep Diffusion(HDD), to exploit meta-paths as main entities in networks. At first, the functional heterogeneous structures of the network are learned by a continuous latent representation through traversing meta-paths with the aim of global end-to-end viewpoint. Then, the well-known deep learning architectures are employed on our generated features to predict diffusion processes in the network. The proposed approach enables us to apply it on different information diffusion tasks such as topic diffusion and cascade prediction. We demonstrate the proposed approach on benchmark network datasets through the well-known evaluation measures. The experimental results show that our approach outperforms the earlier state-of-the-art methods.