 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook & Mark: Leveraging Radiologist Eye Fixations and Bounding boxes in Multimodal Large Language Models for Chest X-ray Report Generation
May 28, 2025Recent advancements in multimodal Large Language Models (LLMs) have significantly enhanced the automation of medical image analysis, particularly in generating radiology reports from chest X-rays (CXR). However, these models still suffer from hallucinations and clinically significant errors, limiting their reliability in real-world applications. In this study, we propose Look & Mark (L&M), a novel grounding fixation strategy that integrates radiologist eye fixations (Look) and bounding box annotations (Mark) into the LLM prompting framework. Unlike conventional fine-tuning, L&M leverages in-context learning to achieve substantial performance gains without retraining. When evaluated across multiple domain-specific and general-purpose models, L&M demonstrates significant gains, including a 1.2% improvement in overall metrics (A.AVG) for CXR-LLaVA compared to baseline prompting and a remarkable 9.2% boost for LLaVA-Med. General-purpose models also benefit from L&M combined with in-context learning, with LLaVA-OV achieving an 87.3% clinical average performance (C.AVG)-the highest among all models, even surpassing those explicitly trained for CXR report generation. Expert evaluations further confirm that L&M reduces clinically significant errors (by 0.43 average errors per report), such as false predictions and omissions, enhancing both accuracy and reliability. These findings highlight L&M's potential as a scalable and efficient solution for AI-assisted radiology, paving the way for improved diagnostic workflows in low-resource clinical settings.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Minuscule Cell Detection in AS-OCT Images with Progressive Field-of-View Focusing
Mar 15, 2025Anterior Segment Optical Coherence Tomography (AS-OCT) is an emerging imaging technique with great potential for diagnosing anterior uveitis, a vision-threatening ocular inflammatory condition. A hallmark of this condition is the presence of inflammatory cells in the eye's anterior chamber, and detecting these cells using AS-OCT images has attracted research interest. While recent efforts aim to replace manual cell detection with automated computer vision approaches, detecting extremely small (minuscule) objects in high-resolution images, such as AS-OCT, poses substantial challenges: (1) each cell appears as a minuscule particle, representing less than 0.005\% of the image, making the detection difficult, and (2) OCT imaging introduces pixel-level noise that can be mistaken for cells, leading to false positive detections. To overcome these challenges, we propose a minuscule cell detection framework through a progressive field-of-view focusing strategy. This strategy systematically refines the detection scope from the whole image to a target region where cells are likely to be present, and further to minuscule regions potentially containing individual cells. Our framework consists of two modules. First, a Field-of-Focus module uses a vision foundation model to segment the target region. Subsequently, a Fine-grained Object Detection module introduces a specialized Minuscule Region Proposal followed by a Spatial Attention Network to distinguish individual cells from noise within the segmented region. Experimental results demonstrate that our framework outperforms state-of-the-art methods for cell detection, providing enhanced efficacy for clinical applications. Our code is publicly available at: https://github.com/joeybyc/MCD.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
Harnessing Knowledge Retrieval with Large Language Models for Clinical Report Error Correction
Jun 21, 2024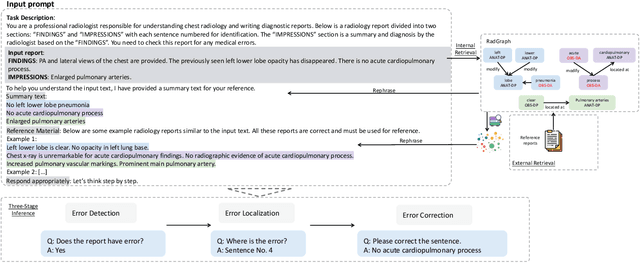



This study proposes an approach for error correction in clinical radiology reports, leveraging large language models (LLMs) and retrieval-augmented generation (RAG) techniques. The proposed framework employs internal and external retrieval mechanisms to extract relevant medical entities and relations from the report and external knowledge sources. A three-stage inference process is introduced, decomposing the task into error detection, localization, and correction subtasks, which enhances the explainability and performance of the system. The effectiveness of the approach is evaluated using a benchmark dataset created by corrupting real-world radiology reports with realistic errors, guided by domain experts. Experimental results demonstrate the benefits of the proposed methods, with the combination of internal and external retrieval significantly improving the accuracy of error detection, localization, and correction across various state-of-the-art LLMs. The findings contribute to the development of more robust and reliable error correction systems for clinical documentation.
Infusing clinical knowledge into tokenisers for language models
Jun 20, 2024



This study introduces a novel knowledge enhanced tokenisation mechanism, K-Tokeniser, for clinical text processing. Technically, at initialisation stage, K-Tokeniser populates global representations of tokens based on semantic types of domain concepts (such as drugs or diseases) from either a domain ontology like Unified Medical Language System or the training data of the task related corpus. At training or inference stage, sentence level localised context will be utilised for choosing the optimal global token representation to realise the semantic-based tokenisation. To avoid pretraining using the new tokeniser, an embedding initialisation approach is proposed to generate representations for new tokens. Using three transformer-based language models, a comprehensive set of experiments are conducted on four real-world datasets for evaluating K-Tokeniser in a wide range of clinical text analytics tasks including clinical concept and relation extraction, automated clinical coding, clinical phenotype identification, and clinical research article classification. Overall, our models demonstrate consistent improvements over their counterparts in all tasks. In particular, substantial improvements are observed in the automated clinical coding task with 13\% increase on Micro $F_1$ score. Furthermore, K-Tokeniser also shows significant capacities in facilitating quicker converge of language models. Specifically, using K-Tokeniser, the language models would only require 50\% of the training data to achieve the best performance of the baseline tokeniser using all training data in the concept extraction task and less than 20\% of the data for the automated coding task. It is worth mentioning that all these improvements require no pre-training process, making the approach generalisable.
Chain-of-Though (CoT) prompting strategies for medical error detection and correction
Jun 13, 2024
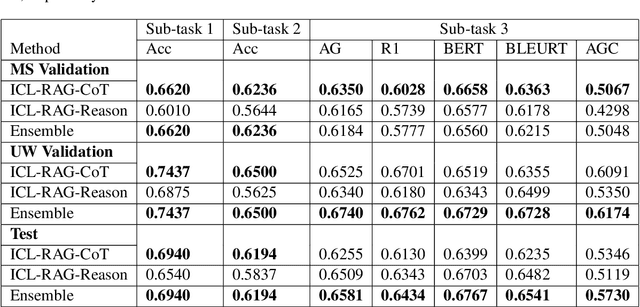

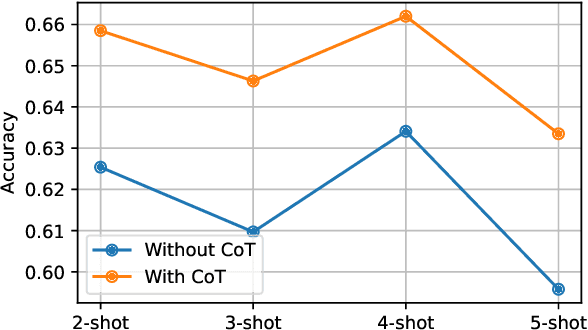
This paper describes our submission to the MEDIQA-CORR 2024 shared task for automatically detecting and correcting medical errors in clinical notes. We report results for three methods of few-shot In-Context Learning (ICL) augmented with Chain-of-Thought (CoT) and reason prompts using a large language model (LLM). In the first method, we manually analyse a subset of train and validation dataset to infer three CoT prompts by examining error types in the clinical notes. In the second method, we utilise the training dataset to prompt the LLM to deduce reasons about their correctness or incorrectness. The constructed CoTs and reasons are then augmented with ICL examples to solve the tasks of error detection, span identification, and error correction. Finally, we combine the two methods using a rule-based ensemble method. Across the three sub-tasks, our ensemble method achieves a ranking of 3rd for both sub-task 1 and 2, while securing 7th place in sub-task 3 among all submissions.
MedExQA: Medical Question Answering Benchmark with Multiple Explanations
Jun 10, 2024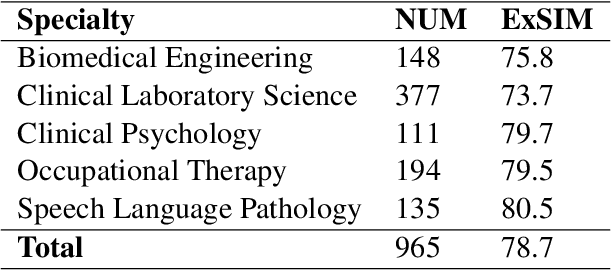
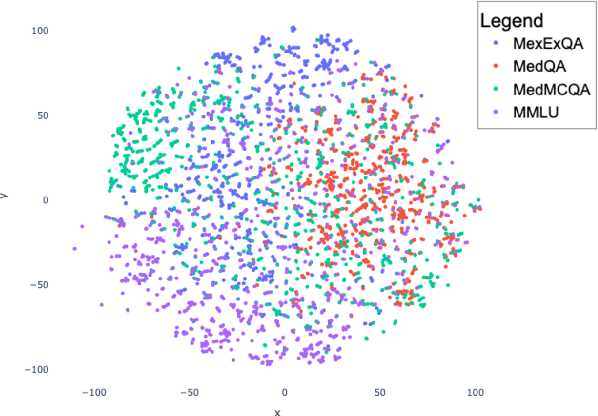
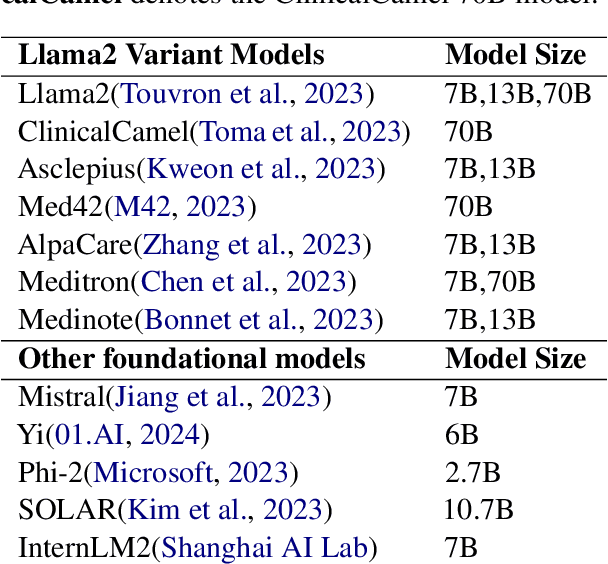
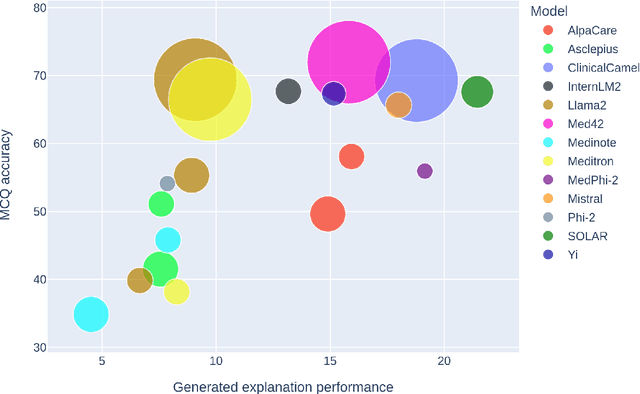
This paper introduces MedExQA, a novel benchmark in medical question-answering, to evaluate large language models' (LLMs) understanding of medical knowledge through explanations. By constructing datasets across five distinct medical specialties that are underrepresented in current datasets and further incorporating multiple explanations for each question-answer pair, we address a major gap in current medical QA benchmarks which is the absence of comprehensive assessments of LLMs' ability to generate nuanced medical explanations. Our work highlights the importance of explainability in medical LLMs, proposes an effective methodology for evaluating models beyond classification accuracy, and sheds light on one specific domain, speech language pathology, where current LLMs including GPT4 lack good understanding. Our results show generation evaluation with multiple explanations aligns better with human assessment, highlighting an opportunity for a more robust automated comprehension assessment for LLMs. To diversify open-source medical LLMs (currently mostly based on Llama2), this work also proposes a new medical model, MedPhi-2, based on Phi-2 (2.7B). The model outperformed medical LLMs based on Llama2-70B in generating explanations, showing its effectiveness in the resource-constrained medical domain. We will share our benchmark datasets and the trained model.
RadBARTsum: Domain Specific Adaption of Denoising Sequence-to-Sequence Models for Abstractive Radiology Report Summarization
Jun 05, 2024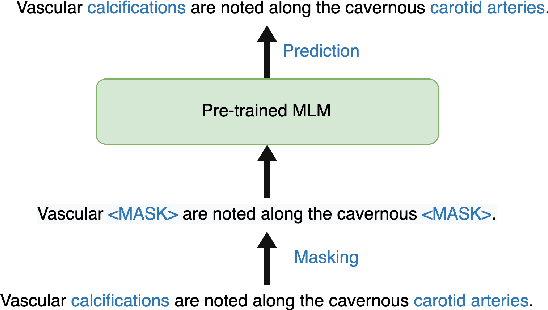

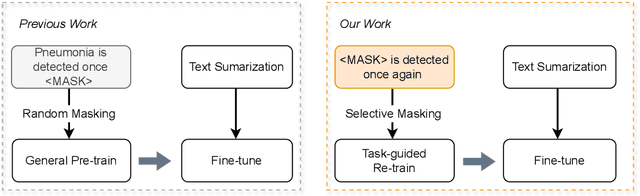
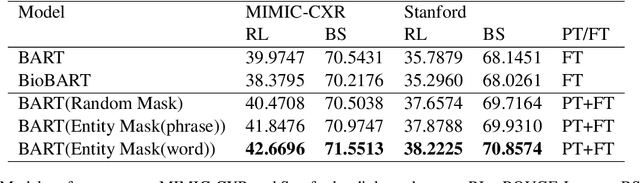
Radiology report summarization is a crucial task that can help doctors quickly identify clinically significant findings without the need to review detailed sections of reports. This study proposes RadBARTsum, a domain-specific and ontology facilitated adaptation of the BART model for abstractive radiology report summarization. The approach involves two main steps: 1) re-training the BART model on a large corpus of radiology reports using a novel entity masking strategy to improving biomedical domain knowledge learning, and 2) fine-tuning the model for the summarization task using the Findings and Background sections to predict the Impression section. Experiments are conducted using different masking strategies. Results show that the re-training process with domain knowledge facilitated masking improves performances consistently across various settings. This work contributes a domain-specific generative language model for radiology report summarization and a method for utilising medical knowledge to realise entity masking language model. The proposed approach demonstrates a promising direction of enhancing the efficiency of language models by deepening its understanding of clinical knowledge in radiology reports.
Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification
May 16, 2024The infrequency and heterogeneity of clinical presentations in rare diseases often lead to underdiagnosis and their exclusion from structured datasets. This necessitates the utilization of unstructured text data for comprehensive analysis. However, the manual identification from clinical reports is an arduous and intrinsically subjective task. This study proposes a novel hybrid approach that synergistically combines a traditional dictionary-based natural language processing (NLP) tool with the powerful capabilities of large language models (LLMs) to enhance the identification of rare diseases from unstructured clinical notes. We comprehensively evaluate various prompting strategies on six large language models (LLMs) of varying sizes and domains (general and medical). This evaluation encompasses zero-shot, few-shot, and retrieval-augmented generation (RAG) techniques to enhance the LLMs' ability to reason about and understand contextual information in patient reports. The results demonstrate effectiveness in rare disease identification, highlighting the potential for identifying underdiagnosed patients from clinical notes.