 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results
Apr 21, 2026This paper presents a review for the LoViF Challenge on Real-World All-in-One Image Restoration. The challenge aimed to advance research on real-world all-in-one image restoration under diverse real-world degradation conditions, including blur, low-light, haze, rain, and snow. It provided a unified benchmark to evaluate the robustness and generalization ability of restoration models across multiple degradation categories within a common framework. The competition attracted 124 registered participants and received 9 valid final submissions with corresponding fact sheets, significantly contributing to the progress of real-world all-in-one image restoration. This report provides a detailed analysis of the submitted methods and corresponding results, emphasizing recent progress in unified real-world image restoration. The analysis highlights effective approaches and establishes a benchmark for future research in real-world low-level vision.
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
Apr 21, 2026Scaling humanoid foundation models is bottlenecked by the scarcity of robotic data. While massive egocentric human data offers a scalable alternative, bridging the cross-embodiment chasm remains a fundamental challenge due to kinematic mismatches. We introduce UniT (Unified Latent Action Tokenizer via Visual Anchoring), a framework that establishes a unified physical language for human-to-humanoid transfer. Grounded in the philosophy that heterogeneous kinematics share universal visual consequences, UniT employs a tri-branch cross-reconstruction mechanism: actions predict vision to anchor kinematics to physical outcomes, while vision reconstructs actions to filter out irrelevant visual confounders. Concurrently, a fusion branch synergies these purified modalities into a shared discrete latent space of embodiment-agnostic physical intents. We validate UniT across two paradigms: 1) Policy Learning (VLA-UniT): By predicting these unified tokens, it effectively leverages diverse human data to achieve state-of-the-art data efficiency and robust out-of-distribution (OOD) generalization on both humanoid simulation benchmark and real-world deployments, notably demonstrating zero-shot task transfer. 2) World Modeling (WM-UniT): By aligning cross-embodiment dynamics via unified tokens as conditions, it realizes direct human-to-humanoid action transfer. This alignment ensures that human data seamlessly translates into enhanced action controllability for humanoid video generation. Ultimately, by inducing a highly aligned cross-embodiment representation (empirically verified by t-SNE visualizations revealing the convergence of human and humanoid features into a shared manifold), UniT offers a scalable path to distill vast human knowledge into general-purpose humanoid capabilities.
Seeking Necessary and Sufficient Information from Multimodal Medical Data
Feb 27, 2026Learning multimodal representations from medical images and other data sources can provide richer information for decision-making. While various multimodal models have been developed for this, they overlook learning features that are both necessary (must be present for the outcome to occur) and sufficient (enough to determine the outcome). We argue learning such features is crucial as they can improve model performance by capturing essential predictive information, and enhance model robustness to missing modalities as each modality can provide adequate predictive signals. Such features can be learned by leveraging the Probability of Necessity and Sufficiency (PNS) as a learning objective, an approach that has proven effective in unimodal settings. However, extending PNS to multimodal scenarios remains underexplored and is non-trivial as key conditions of PNS estimation are violated. We address this by decomposing multimodal representations into modality-invariant and modality-specific components, then deriving tractable PNS objectives for each. Experiments on synthetic and real-world medical datasets demonstrate our method's effectiveness. Code will be available on GitHub.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Multimodal Generative Retrieval Model with Staged Pretraining for Food Delivery on Meituan
Feb 06, 2026Multimodal retrieval models are becoming increasingly important in scenarios such as food delivery, where rich multimodal features can meet diverse user needs and enable precise retrieval. Mainstream approaches typically employ a dual-tower architecture between queries and items, and perform joint optimization of intra-tower and inter-tower tasks. However, we observe that joint optimization often leads to certain modalities dominating the training process, while other modalities are neglected. In addition, inconsistent training speeds across modalities can easily result in the one-epoch problem. To address these challenges, we propose a staged pretraining strategy, which guides the model to focus on specialized tasks at each stage, enabling it to effectively attend to and utilize multimodal features, and allowing flexible control over the training process at each stage to avoid the one-epoch problem. Furthermore, to better utilize the semantic IDs that compress high-dimensional multimodal embeddings, we design both generative and discriminative tasks to help the model understand the associations between SIDs, queries, and item features, thereby improving overall performance. Extensive experiments on large-scale real-world Meituan data demonstrate that our method achieves improvements of 3.80%, 2.64%, and 2.17% on R@5, R@10, and R@20, and 5.10%, 4.22%, and 2.09% on N@5, N@10, and N@20 compared to mainstream baselines. Online A/B testing on the Meituan platform shows that our approach achieves a 1.12% increase in revenue and a 1.02% increase in click-through rate, validating the effectiveness and superiority of our method in practical applications.
Super Encoding Network: Recursive Association of Multi-Modal Encoders for Video Understanding
Jun 09, 2025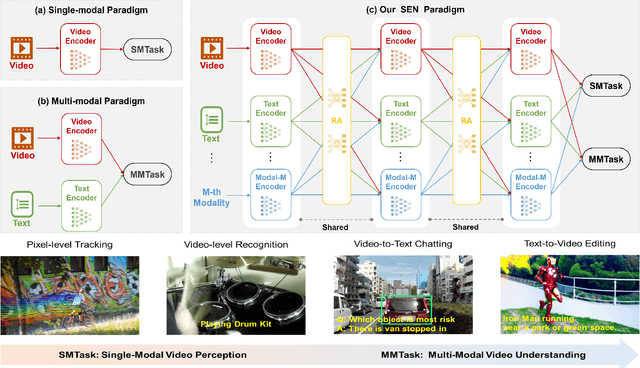
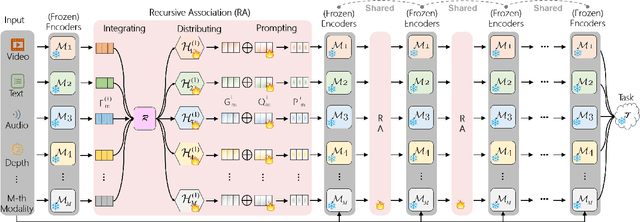
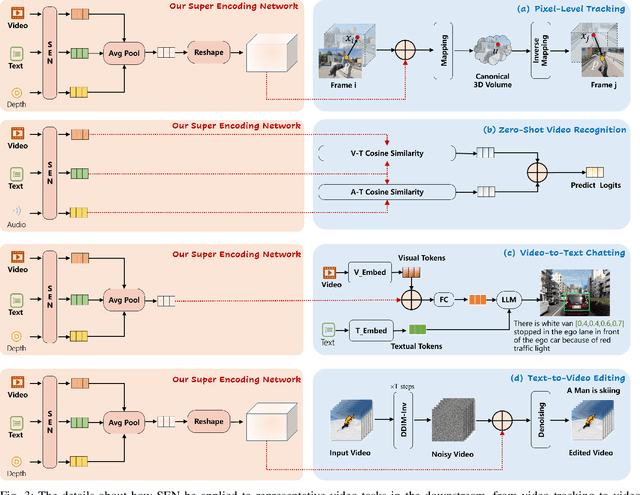

Video understanding has been considered as one critical step towards world modeling, which is an important long-term problem in AI research. Recently, multi-modal foundation models have shown such potential via large-scale pretraining. However, these models simply align encoders of different modalities via contrastive learning, while lacking deeper multi-modal interactions, which is critical for understanding complex target movements with diversified video scenes. To fill this gap, we propose a unified Super Encoding Network (SEN) for video understanding, which builds up such distinct interactions through recursive association of multi-modal encoders in the foundation models. Specifically, we creatively treat those well-trained encoders as "super neurons" in our SEN. Via designing a Recursive Association (RA) block, we progressively fuse multi-modalities with the input video, based on knowledge integrating, distributing, and prompting of super neurons in a recursive manner. In this way, our SEN can effectively encode deeper multi-modal interactions, for prompting various video understanding tasks in downstream. Extensive experiments show that, our SEN can remarkably boost the four most representative video tasks, including tracking, recognition, chatting, and editing, e.g., for pixel-level tracking, the average jaccard index improves 2.7%, temporal coherence(TC) drops 8.8% compared to the popular CaDeX++ approach. For one-shot video editing, textual alignment improves 6.4%, and frame consistency increases 4.1% compared to the popular TuneA-Video approach.
VideoChat-A1: Thinking with Long Videos by Chain-of-Shot Reasoning
Jun 06, 2025The recent advance in video understanding has been driven by multimodal large language models (MLLMs). But these MLLMs are good at analyzing short videos, while suffering from difficulties in understanding videos with a longer context. To address this difficulty, several agent paradigms have recently been proposed, using MLLMs as agents for retrieving extra contextual knowledge in a long video. However, most existing agents ignore the key fact that a long video is composed with multiple shots, i.e., to answer the user question from a long video, it is critical to deeply understand its relevant shots like human. Without such insight, these agents often mistakenly find redundant even noisy temporal context, restricting their capacity for long video understanding. To fill this gap, we propose VideoChat-A1, a novel long video agent paradigm. Different from the previous works, our VideoChat-A1 can deeply think with long videos, via a distinct chain-of-shot reasoning paradigm. More specifically, it can progressively select the relevant shots of user question, and look into these shots in a coarse-to-fine partition. By multi-modal reasoning along the shot chain, VideoChat-A1 can effectively mimic step-by-step human thinking process, allowing to interactively discover preferable temporal context for thoughtful understanding in long videos. Extensive experiments show that, our VideoChat-A1 achieves the state-of-the-art performance on the mainstream long video QA benchmarks, e.g., it achieves 77.0 on VideoMME and 70.1 on EgoSchema, outperforming its strong baselines (e.g., Intern2.5VL-8B and InternVideo2.5-8B), by up to 10.8\% and 6.2\%. Compared to leading close-source GPT-4o and Gemini 1.5 Pro, VideoChat-A1 offers competitive accuracy, but with 7\% input frames and 12\% inference time on average.
Unveiling Hidden Vulnerabilities in Digital Human Generation via Adversarial Attacks
Apr 24, 2025



Expressive human pose and shape estimation (EHPS) is crucial for digital human generation, especially in applications like live streaming. While existing research primarily focuses on reducing estimation errors, it largely neglects robustness and security aspects, leaving these systems vulnerable to adversarial attacks. To address this significant challenge, we propose the \textbf{Tangible Attack (TBA)}, a novel framework designed to generate adversarial examples capable of effectively compromising any digital human generation model. Our approach introduces a \textbf{Dual Heterogeneous Noise Generator (DHNG)}, which leverages Variational Autoencoders (VAE) and ControlNet to produce diverse, targeted noise tailored to the original image features. Additionally, we design a custom \textbf{adversarial loss function} to optimize the noise, ensuring both high controllability and potent disruption. By iteratively refining the adversarial sample through multi-gradient signals from both the noise and the state-of-the-art EHPS model, TBA substantially improves the effectiveness of adversarial attacks. Extensive experiments demonstrate TBA's superiority, achieving a remarkable 41.0\% increase in estimation error, with an average improvement of approximately 17.0\%. These findings expose significant security vulnerabilities in current EHPS models and highlight the need for stronger defenses in digital human generation systems.
Blend the Separated: Mixture of Synergistic Experts for Data-Scarcity Drug-Target Interaction Prediction
Mar 20, 2025Drug-target interaction prediction (DTI) is essential in various applications including drug discovery and clinical application. There are two perspectives of input data widely used in DTI prediction: Intrinsic data represents how drugs or targets are constructed, and extrinsic data represents how drugs or targets are related to other biological entities. However, any of the two perspectives of input data can be scarce for some drugs or targets, especially for those unpopular or newly discovered. Furthermore, ground-truth labels for specific interaction types can also be scarce. Therefore, we propose the first method to tackle DTI prediction under input data and/or label scarcity. To make our model functional when only one perspective of input data is available, we design two separate experts to process intrinsic and extrinsic data respectively and fuse them adaptively according to different samples. Furthermore, to make the two perspectives complement each other and remedy label scarcity, two experts synergize with each other in a mutually supervised way to exploit the enormous unlabeled data. Extensive experiments on 3 real-world datasets under different extents of input data scarcity and/or label scarcity demonstrate our model outperforms states of the art significantly and steadily, with a maximum improvement of 53.53%. We also test our model without any data scarcity and it still outperforms current methods.
Minuscule Cell Detection in AS-OCT Images with Progressive Field-of-View Focusing
Mar 15, 2025Anterior Segment Optical Coherence Tomography (AS-OCT) is an emerging imaging technique with great potential for diagnosing anterior uveitis, a vision-threatening ocular inflammatory condition. A hallmark of this condition is the presence of inflammatory cells in the eye's anterior chamber, and detecting these cells using AS-OCT images has attracted research interest. While recent efforts aim to replace manual cell detection with automated computer vision approaches, detecting extremely small (minuscule) objects in high-resolution images, such as AS-OCT, poses substantial challenges: (1) each cell appears as a minuscule particle, representing less than 0.005\% of the image, making the detection difficult, and (2) OCT imaging introduces pixel-level noise that can be mistaken for cells, leading to false positive detections. To overcome these challenges, we propose a minuscule cell detection framework through a progressive field-of-view focusing strategy. This strategy systematically refines the detection scope from the whole image to a target region where cells are likely to be present, and further to minuscule regions potentially containing individual cells. Our framework consists of two modules. First, a Field-of-Focus module uses a vision foundation model to segment the target region. Subsequently, a Fine-grained Object Detection module introduces a specialized Minuscule Region Proposal followed by a Spatial Attention Network to distinguish individual cells from noise within the segmented region. Experimental results demonstrate that our framework outperforms state-of-the-art methods for cell detection, providing enhanced efficacy for clinical applications. Our code is publicly available at: https://github.com/joeybyc/MCD.