 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoChat-A1: Thinking with Long Videos by Chain-of-Shot Reasoning
Jun 06, 2025The recent advance in video understanding has been driven by multimodal large language models (MLLMs). But these MLLMs are good at analyzing short videos, while suffering from difficulties in understanding videos with a longer context. To address this difficulty, several agent paradigms have recently been proposed, using MLLMs as agents for retrieving extra contextual knowledge in a long video. However, most existing agents ignore the key fact that a long video is composed with multiple shots, i.e., to answer the user question from a long video, it is critical to deeply understand its relevant shots like human. Without such insight, these agents often mistakenly find redundant even noisy temporal context, restricting their capacity for long video understanding. To fill this gap, we propose VideoChat-A1, a novel long video agent paradigm. Different from the previous works, our VideoChat-A1 can deeply think with long videos, via a distinct chain-of-shot reasoning paradigm. More specifically, it can progressively select the relevant shots of user question, and look into these shots in a coarse-to-fine partition. By multi-modal reasoning along the shot chain, VideoChat-A1 can effectively mimic step-by-step human thinking process, allowing to interactively discover preferable temporal context for thoughtful understanding in long videos. Extensive experiments show that, our VideoChat-A1 achieves the state-of-the-art performance on the mainstream long video QA benchmarks, e.g., it achieves 77.0 on VideoMME and 70.1 on EgoSchema, outperforming its strong baselines (e.g., Intern2.5VL-8B and InternVideo2.5-8B), by up to 10.8\% and 6.2\%. Compared to leading close-source GPT-4o and Gemini 1.5 Pro, VideoChat-A1 offers competitive accuracy, but with 7\% input frames and 12\% inference time on average.
V-Stylist: Video Stylization via Collaboration and Reflection of MLLM Agents
Mar 15, 2025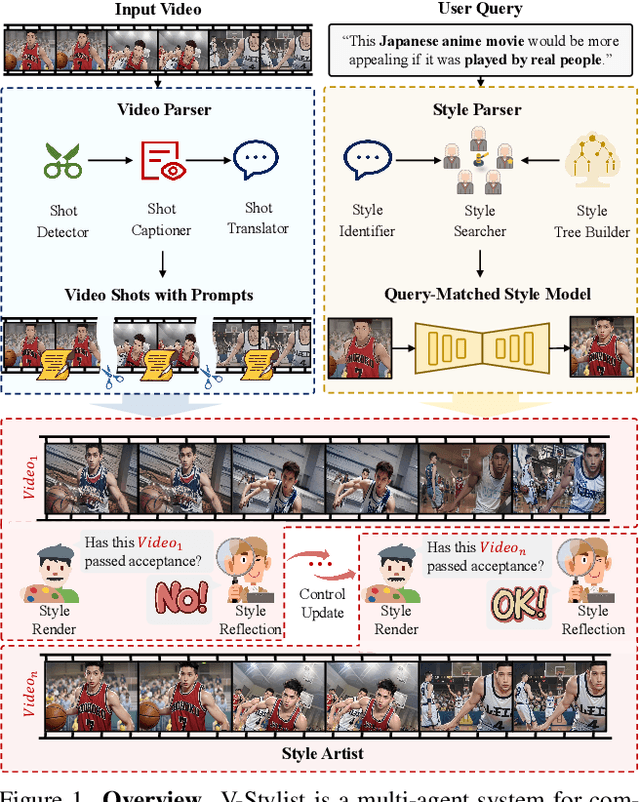
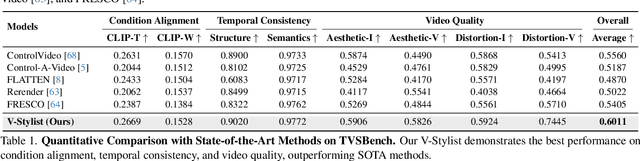


Despite the recent advancement in video stylization, most existing methods struggle to render any video with complex transitions, based on an open style description of user query. To fill this gap, we introduce a generic multi-agent system for video stylization, V-Stylist, by a novel collaboration and reflection paradigm of multi-modal large language models. Specifically, our V-Stylist is a systematical workflow with three key roles: (1) Video Parser decomposes the input video into a number of shots and generates their text prompts of key shot content. Via a concise video-to-shot prompting paradigm, it allows our V-Stylist to effectively handle videos with complex transitions. (2) Style Parser identifies the style in the user query and progressively search the matched style model from a style tree. Via a robust tree-of-thought searching paradigm, it allows our V-Stylist to precisely specify vague style preference in the open user query. (3) Style Artist leverages the matched model to render all the video shots into the required style. Via a novel multi-round self-reflection paradigm, it allows our V-Stylist to adaptively adjust detail control, according to the style requirement. With such a distinct design of mimicking human professionals, our V-Stylist achieves a major breakthrough over the primary challenges for effective and automatic video stylization. Moreover,we further construct a new benchmark Text-driven Video Stylization Benchmark (TVSBench), which fills the gap to assess stylization of complex videos on open user queries. Extensive experiments show that, V-Stylist achieves the state-of-the-art, e.g.,V-Stylist surpasses FRESCO and ControlVideo by 6.05% and 4.51% respectively in overall average metrics, marking a significant advance in video stylization.
LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
Mar 13, 2025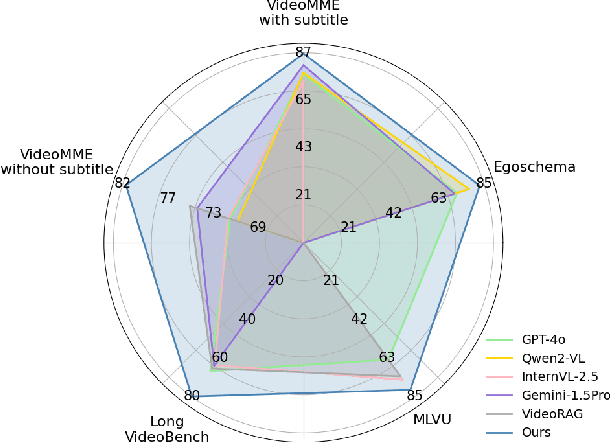



Existing Multimodal Large Language Models (MLLMs) encounter significant challenges in modeling the temporal context within long videos. Currently, mainstream Agent-based methods use external tools (e.g., search engine, memory banks, OCR, retrieval models) to assist a single MLLM in answering long video questions. Despite such tool-based support, a solitary MLLM still offers only a partial understanding of long videos, resulting in limited performance. In order to better address long video tasks, we introduce LVAgent, the first framework enabling multi-round dynamic collaboration of MLLM agents in long video understanding. Our methodology consists of four key steps: 1. Selection: We pre-select appropriate agents from the model library to form optimal agent teams based on different tasks. 2. Perception: We design an effective retrieval scheme for long videos, improving the coverage of critical temporal segments while maintaining computational efficiency. 3. Action: Agents answer long video-related questions and exchange reasons. 4. Reflection: We evaluate the performance of each agent in each round of discussion and optimize the agent team for dynamic collaboration. The agents iteratively refine their answers by multi-round dynamical collaboration of MLLM agents. LVAgent is the first agent system method that outperforms all closed-source models (including GPT-4o) and open-source models (including InternVL-2.5 and Qwen2-VL) in the long video understanding tasks. Our LVAgent achieves an accuracy of 80% on four mainstream long video understanding tasks. Notably, on the LongVideoBench dataset, LVAgent improves accuracy by up to 14.3% compared with SOTA.
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024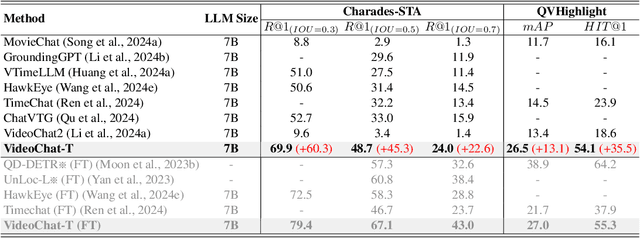
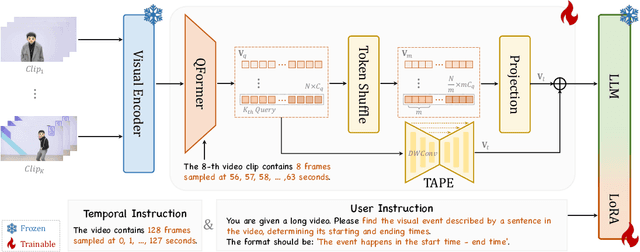
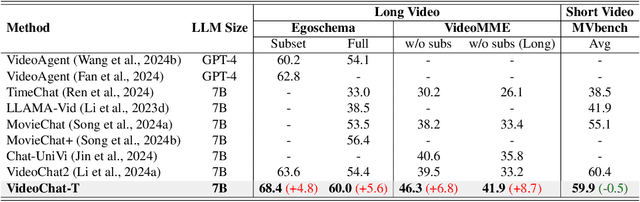
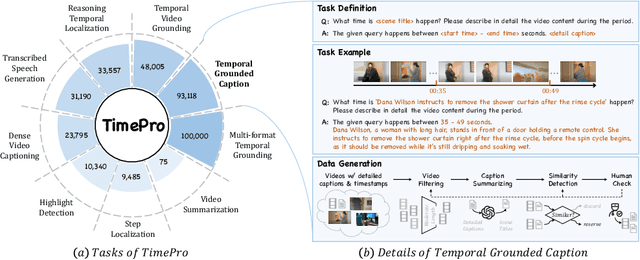
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.
MUSES: 3D-Controllable Image Generation via Multi-Modal Agent Collaboration
Aug 21, 2024


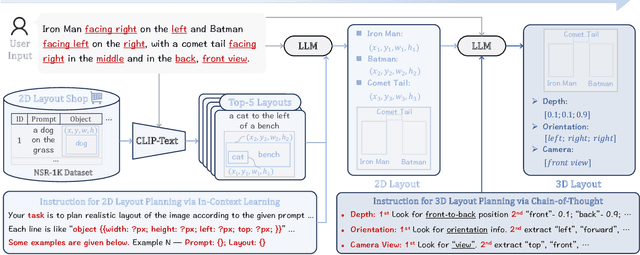
Despite recent advancements in text-to-image generation, most existing methods struggle to create images with multiple objects and complex spatial relationships in 3D world. To tackle this limitation, we introduce a generic AI system, namely MUSES, for 3D-controllable image generation from user queries. Specifically, our MUSES addresses this challenging task by developing a progressive workflow with three key components, including (1) Layout Manager for 2D-to-3D layout lifting, (2) Model Engineer for 3D object acquisition and calibration, (3) Image Artist for 3D-to-2D image rendering. By mimicking the collaboration of human professionals, this multi-modal agent pipeline facilitates the effective and automatic creation of images with 3D-controllable objects, through an explainable integration of top-down planning and bottom-up generation. Additionally, we find that existing benchmarks lack detailed descriptions of complex 3D spatial relationships of multiple objects. To fill this gap, we further construct a new benchmark of T2I-3DisBench (3D image scene), which describes diverse 3D image scenes with 50 detailed prompts. Extensive experiments show the state-of-the-art performance of MUSES on both T2I-CompBench and T2I-3DisBench, outperforming recent strong competitors such as DALL-E 3 and Stable Diffusion 3. These results demonstrate a significant step of MUSES forward in bridging natural language, 2D image generation, and 3D world.