 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-STAR: Multi-Scale Spatiotemporal Autoregression for Human Mobility Modeling
Dec 08, 2025Modeling human mobility is vital for extensive applications such as transportation planning and epidemic modeling. With the rise of the Artificial Intelligence Generated Content (AIGC) paradigm, recent works explore synthetic trajectory generation using autoregressive and diffusion models. While these methods show promise for generating single-day trajectories, they remain limited by inefficiencies in long-term generation (e.g., weekly trajectories) and a lack of explicit spatiotemporal multi-scale modeling. This study proposes Multi-Scale Spatio-Temporal AutoRegression (M-STAR), a new framework that generates long-term trajectories through a coarse-to-fine spatiotemporal prediction process. M-STAR combines a Multi-scale Spatiotemporal Tokenizer that encodes hierarchical mobility patterns with a Transformer-based decoder for next-scale autoregressive prediction. Experiments on two real-world datasets show that M-STAR outperforms existing methods in fidelity and significantly improves generation speed. The data and codes are available at https://github.com/YuxiaoLuo0013/M-STAR.
Super Encoding Network: Recursive Association of Multi-Modal Encoders for Video Understanding
Jun 09, 2025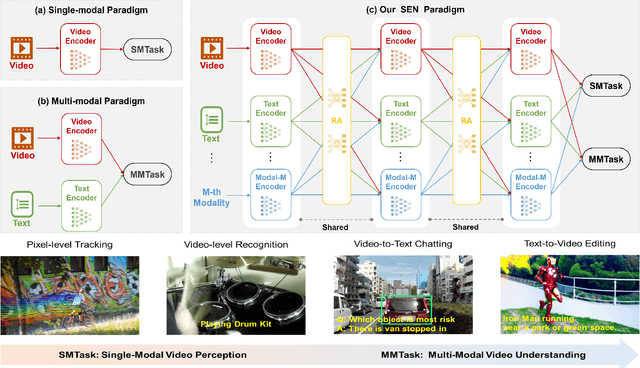
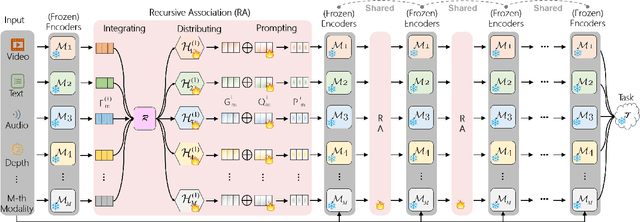
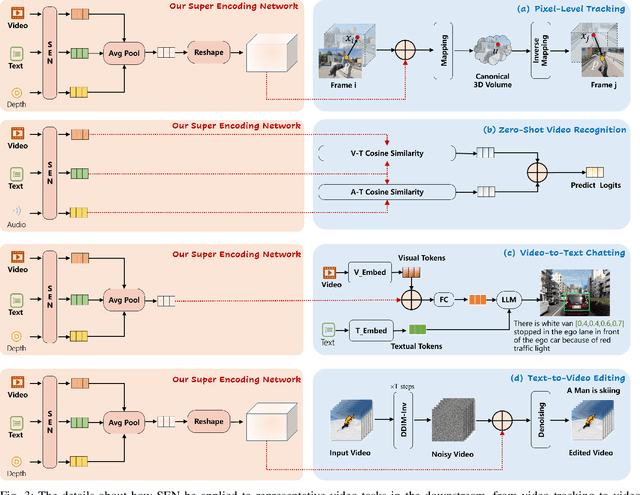

Video understanding has been considered as one critical step towards world modeling, which is an important long-term problem in AI research. Recently, multi-modal foundation models have shown such potential via large-scale pretraining. However, these models simply align encoders of different modalities via contrastive learning, while lacking deeper multi-modal interactions, which is critical for understanding complex target movements with diversified video scenes. To fill this gap, we propose a unified Super Encoding Network (SEN) for video understanding, which builds up such distinct interactions through recursive association of multi-modal encoders in the foundation models. Specifically, we creatively treat those well-trained encoders as "super neurons" in our SEN. Via designing a Recursive Association (RA) block, we progressively fuse multi-modalities with the input video, based on knowledge integrating, distributing, and prompting of super neurons in a recursive manner. In this way, our SEN can effectively encode deeper multi-modal interactions, for prompting various video understanding tasks in downstream. Extensive experiments show that, our SEN can remarkably boost the four most representative video tasks, including tracking, recognition, chatting, and editing, e.g., for pixel-level tracking, the average jaccard index improves 2.7%, temporal coherence(TC) drops 8.8% compared to the popular CaDeX++ approach. For one-shot video editing, textual alignment improves 6.4%, and frame consistency increases 4.1% compared to the popular TuneA-Video approach.
LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
Mar 13, 2025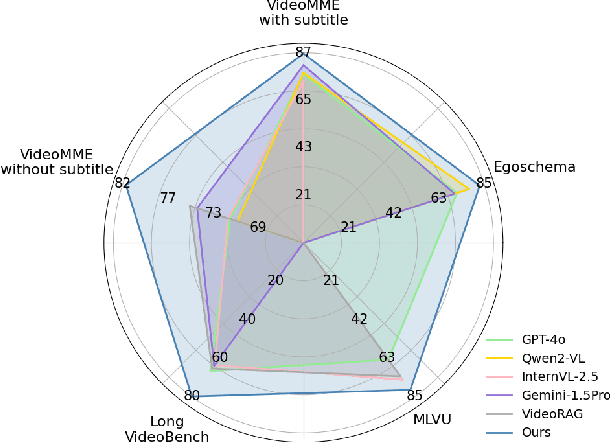



Existing Multimodal Large Language Models (MLLMs) encounter significant challenges in modeling the temporal context within long videos. Currently, mainstream Agent-based methods use external tools (e.g., search engine, memory banks, OCR, retrieval models) to assist a single MLLM in answering long video questions. Despite such tool-based support, a solitary MLLM still offers only a partial understanding of long videos, resulting in limited performance. In order to better address long video tasks, we introduce LVAgent, the first framework enabling multi-round dynamic collaboration of MLLM agents in long video understanding. Our methodology consists of four key steps: 1. Selection: We pre-select appropriate agents from the model library to form optimal agent teams based on different tasks. 2. Perception: We design an effective retrieval scheme for long videos, improving the coverage of critical temporal segments while maintaining computational efficiency. 3. Action: Agents answer long video-related questions and exchange reasons. 4. Reflection: We evaluate the performance of each agent in each round of discussion and optimize the agent team for dynamic collaboration. The agents iteratively refine their answers by multi-round dynamical collaboration of MLLM agents. LVAgent is the first agent system method that outperforms all closed-source models (including GPT-4o) and open-source models (including InternVL-2.5 and Qwen2-VL) in the long video understanding tasks. Our LVAgent achieves an accuracy of 80% on four mainstream long video understanding tasks. Notably, on the LongVideoBench dataset, LVAgent improves accuracy by up to 14.3% compared with SOTA.
H-MBA: Hierarchical MamBa Adaptation for Multi-Modal Video Understanding in Autonomous Driving
Jan 08, 2025



With the prevalence of Multimodal Large Language Models(MLLMs), autonomous driving has encountered new opportunities and challenges. In particular, multi-modal video understanding is critical to interactively analyze what will happen in the procedure of autonomous driving. However, videos in such a dynamical scene that often contains complex spatial-temporal movements, which restricts the generalization capacity of the existing MLLMs in this field. To bridge the gap, we propose a novel Hierarchical Mamba Adaptation (H-MBA) framework to fit the complicated motion changes in autonomous driving videos. Specifically, our H-MBA consists of two distinct modules, including Context Mamba (C-Mamba) and Query Mamba (Q-Mamba). First, C-Mamba contains various types of structure state space models, which can effectively capture multi-granularity video context for different temporal resolutions. Second, Q-Mamba flexibly transforms the current frame as the learnable query, and attentively selects multi-granularity video context into query. Consequently, it can adaptively integrate all the video contexts of multi-scale temporal resolutions to enhance video understanding. Via a plug-and-play paradigm in MLLMs, our H-MBA shows the remarkable performance on multi-modal video tasks in autonomous driving, e.g., for risk object detection, it outperforms the previous SOTA method with 5.5% mIoU improvement.
Percept, Chat, and then Adapt: Multimodal Knowledge Transfer of Foundation Models for Open-World Video Recognition
Feb 29, 2024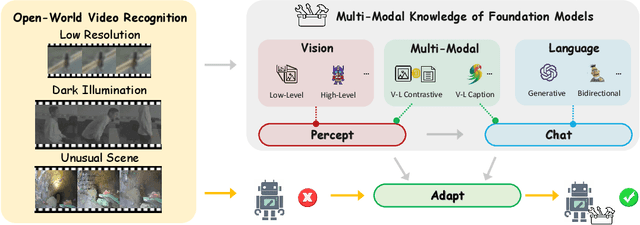

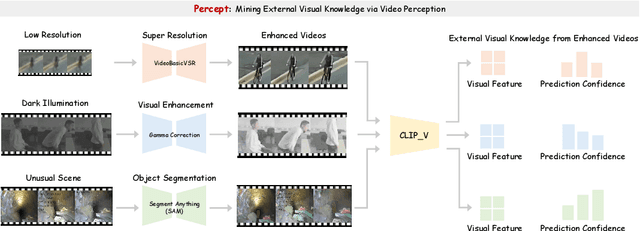
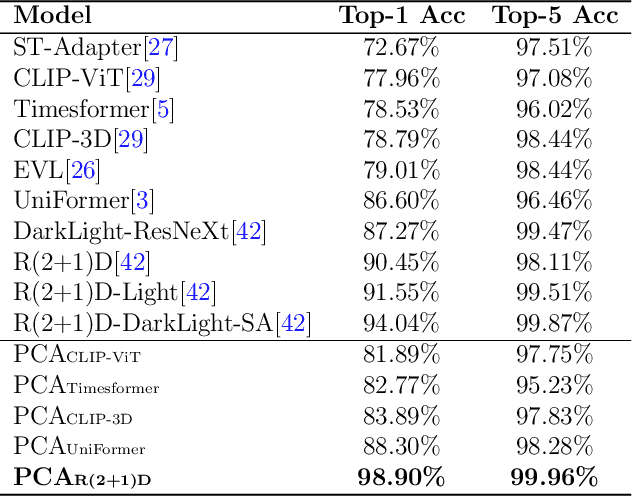
Open-world video recognition is challenging since traditional networks are not generalized well on complex environment variations. Alternatively, foundation models with rich knowledge have recently shown their generalization power. However, how to apply such knowledge has not been fully explored for open-world video recognition. To this end, we propose a generic knowledge transfer pipeline, which progressively exploits and integrates external multimodal knowledge from foundation models to boost open-world video recognition. We name it PCA, based on three stages of Percept, Chat, and Adapt. First, we perform Percept process to reduce the video domain gap and obtain external visual knowledge. Second, we generate rich linguistic semantics as external textual knowledge in Chat stage. Finally, we blend external multimodal knowledge in Adapt stage, by inserting multimodal knowledge adaptation modules into networks. We conduct extensive experiments on three challenging open-world video benchmarks, i.e., TinyVIRAT, ARID, and QV-Pipe. Our approach achieves state-of-the-art performance on all three datasets.
M-BEV: Masked BEV Perception for Robust Autonomous Driving
Dec 19, 2023



3D perception is a critical problem in autonomous driving. Recently, the Bird-Eye-View (BEV) approach has attracted extensive attention, due to low-cost deployment and desirable vision detection capacity. However, the existing models ignore a realistic scenario during the driving procedure, i.e., one or more view cameras may be failed, which largely deteriorates the performance. To tackle this problem, we propose a generic Masked BEV (M-BEV) perception framework, which can effectively improve robustness to this challenging scenario, by random masking and reconstructing camera views in the end-to-end training. More specifically, we develop a novel Masked View Reconstruction (MVR) module for M-BEV. It mimics various missing cases by randomly masking features of different camera views, then leverages the original features of these views as self-supervision, and reconstructs the masked ones with the distinct spatio-temporal context across views. Via such a plug-and-play MVR, our M-BEV is capable of learning the missing views from the resting ones, and thus well generalized for robust view recovery and accurate perception in the testing. We perform extensive experiments on the popular NuScenes benchmark, where our framework can significantly boost 3D perception performance of the state-of-the-art models on various missing view cases, e.g., for the absence of back view, our M-BEV promotes the PETRv2 model with 10.3% mAP gain.