 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePercept, Chat, and then Adapt: Multimodal Knowledge Transfer of Foundation Models for Open-World Video Recognition
Paper and Code
Feb 29, 2024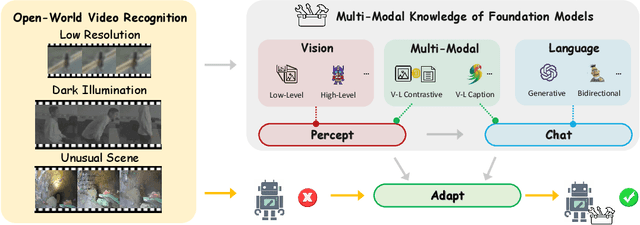

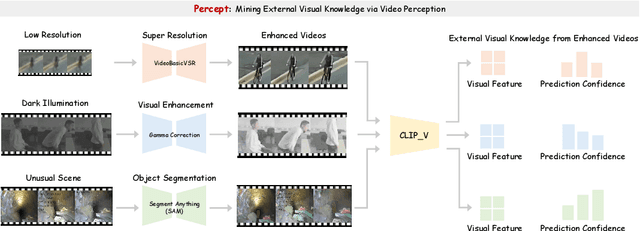
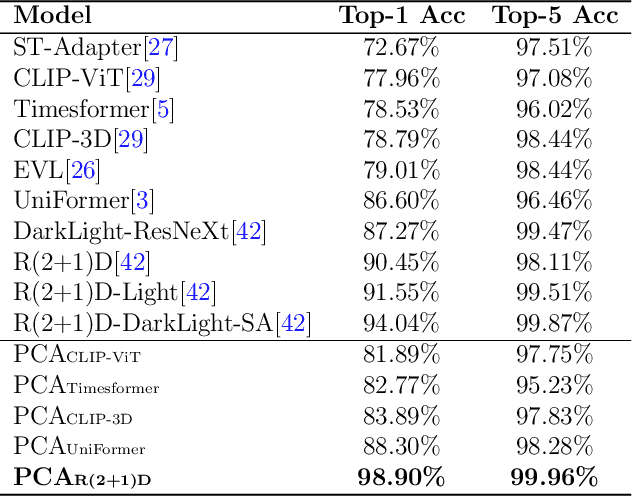
Open-world video recognition is challenging since traditional networks are not generalized well on complex environment variations. Alternatively, foundation models with rich knowledge have recently shown their generalization power. However, how to apply such knowledge has not been fully explored for open-world video recognition. To this end, we propose a generic knowledge transfer pipeline, which progressively exploits and integrates external multimodal knowledge from foundation models to boost open-world video recognition. We name it PCA, based on three stages of Percept, Chat, and Adapt. First, we perform Percept process to reduce the video domain gap and obtain external visual knowledge. Second, we generate rich linguistic semantics as external textual knowledge in Chat stage. Finally, we blend external multimodal knowledge in Adapt stage, by inserting multimodal knowledge adaptation modules into networks. We conduct extensive experiments on three challenging open-world video benchmarks, i.e., TinyVIRAT, ARID, and QV-Pipe. Our approach achieves state-of-the-art performance on all three datasets.