 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
Paper and Code
Mar 13, 2025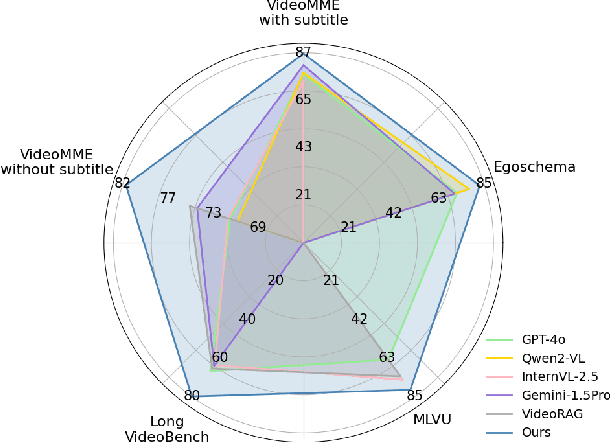



Existing Multimodal Large Language Models (MLLMs) encounter significant challenges in modeling the temporal context within long videos. Currently, mainstream Agent-based methods use external tools (e.g., search engine, memory banks, OCR, retrieval models) to assist a single MLLM in answering long video questions. Despite such tool-based support, a solitary MLLM still offers only a partial understanding of long videos, resulting in limited performance. In order to better address long video tasks, we introduce LVAgent, the first framework enabling multi-round dynamic collaboration of MLLM agents in long video understanding. Our methodology consists of four key steps: 1. Selection: We pre-select appropriate agents from the model library to form optimal agent teams based on different tasks. 2. Perception: We design an effective retrieval scheme for long videos, improving the coverage of critical temporal segments while maintaining computational efficiency. 3. Action: Agents answer long video-related questions and exchange reasons. 4. Reflection: We evaluate the performance of each agent in each round of discussion and optimize the agent team for dynamic collaboration. The agents iteratively refine their answers by multi-round dynamical collaboration of MLLM agents. LVAgent is the first agent system method that outperforms all closed-source models (including GPT-4o) and open-source models (including InternVL-2.5 and Qwen2-VL) in the long video understanding tasks. Our LVAgent achieves an accuracy of 80% on four mainstream long video understanding tasks. Notably, on the LongVideoBench dataset, LVAgent improves accuracy by up to 14.3% compared with SOTA.