 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
VideoChat-A1: Thinking with Long Videos by Chain-of-Shot Reasoning
Jun 06, 2025The recent advance in video understanding has been driven by multimodal large language models (MLLMs). But these MLLMs are good at analyzing short videos, while suffering from difficulties in understanding videos with a longer context. To address this difficulty, several agent paradigms have recently been proposed, using MLLMs as agents for retrieving extra contextual knowledge in a long video. However, most existing agents ignore the key fact that a long video is composed with multiple shots, i.e., to answer the user question from a long video, it is critical to deeply understand its relevant shots like human. Without such insight, these agents often mistakenly find redundant even noisy temporal context, restricting their capacity for long video understanding. To fill this gap, we propose VideoChat-A1, a novel long video agent paradigm. Different from the previous works, our VideoChat-A1 can deeply think with long videos, via a distinct chain-of-shot reasoning paradigm. More specifically, it can progressively select the relevant shots of user question, and look into these shots in a coarse-to-fine partition. By multi-modal reasoning along the shot chain, VideoChat-A1 can effectively mimic step-by-step human thinking process, allowing to interactively discover preferable temporal context for thoughtful understanding in long videos. Extensive experiments show that, our VideoChat-A1 achieves the state-of-the-art performance on the mainstream long video QA benchmarks, e.g., it achieves 77.0 on VideoMME and 70.1 on EgoSchema, outperforming its strong baselines (e.g., Intern2.5VL-8B and InternVideo2.5-8B), by up to 10.8\% and 6.2\%. Compared to leading close-source GPT-4o and Gemini 1.5 Pro, VideoChat-A1 offers competitive accuracy, but with 7\% input frames and 12\% inference time on average.
DS-ProGen: A Dual-Structure Deep Language Model for Functional Protein Design
May 18, 2025Inverse Protein Folding (IPF) is a critical subtask in the field of protein design, aiming to engineer amino acid sequences capable of folding correctly into a specified three-dimensional (3D) conformation. Although substantial progress has been achieved in recent years, existing methods generally rely on either backbone coordinates or molecular surface features alone, which restricts their ability to fully capture the complex chemical and geometric constraints necessary for precise sequence prediction. To address this limitation, we present DS-ProGen, a dual-structure deep language model for functional protein design, which integrates both backbone geometry and surface-level representations. By incorporating backbone coordinates as well as surface chemical and geometric descriptors into a next-amino-acid prediction paradigm, DS-ProGen is able to generate functionally relevant and structurally stable sequences while satisfying both global and local conformational constraints. On the PRIDE dataset, DS-ProGen attains the current state-of-the-art recovery rate of 61.47%, demonstrating the synergistic advantage of multi-modal structural encoding in protein design. Furthermore, DS-ProGen excels in predicting interactions with a variety of biological partners, including ligands, ions, and RNA, confirming its robust functional retention capabilities.
LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
Mar 13, 2025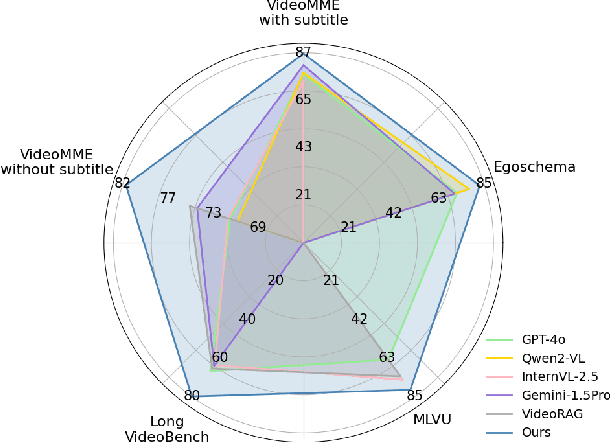



Existing Multimodal Large Language Models (MLLMs) encounter significant challenges in modeling the temporal context within long videos. Currently, mainstream Agent-based methods use external tools (e.g., search engine, memory banks, OCR, retrieval models) to assist a single MLLM in answering long video questions. Despite such tool-based support, a solitary MLLM still offers only a partial understanding of long videos, resulting in limited performance. In order to better address long video tasks, we introduce LVAgent, the first framework enabling multi-round dynamic collaboration of MLLM agents in long video understanding. Our methodology consists of four key steps: 1. Selection: We pre-select appropriate agents from the model library to form optimal agent teams based on different tasks. 2. Perception: We design an effective retrieval scheme for long videos, improving the coverage of critical temporal segments while maintaining computational efficiency. 3. Action: Agents answer long video-related questions and exchange reasons. 4. Reflection: We evaluate the performance of each agent in each round of discussion and optimize the agent team for dynamic collaboration. The agents iteratively refine their answers by multi-round dynamical collaboration of MLLM agents. LVAgent is the first agent system method that outperforms all closed-source models (including GPT-4o) and open-source models (including InternVL-2.5 and Qwen2-VL) in the long video understanding tasks. Our LVAgent achieves an accuracy of 80% on four mainstream long video understanding tasks. Notably, on the LongVideoBench dataset, LVAgent improves accuracy by up to 14.3% compared with SOTA.
Large Language Models in Bioinformatics: A Survey
Mar 06, 2025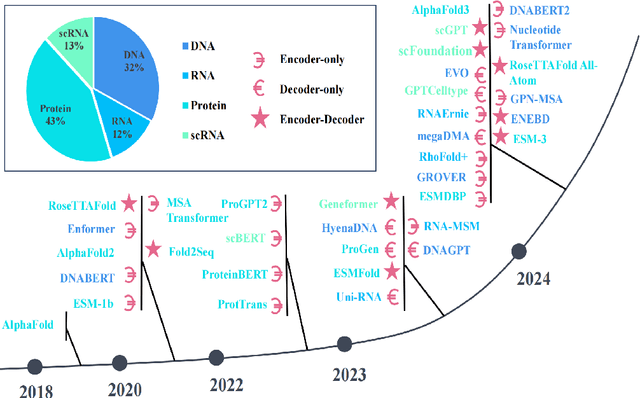
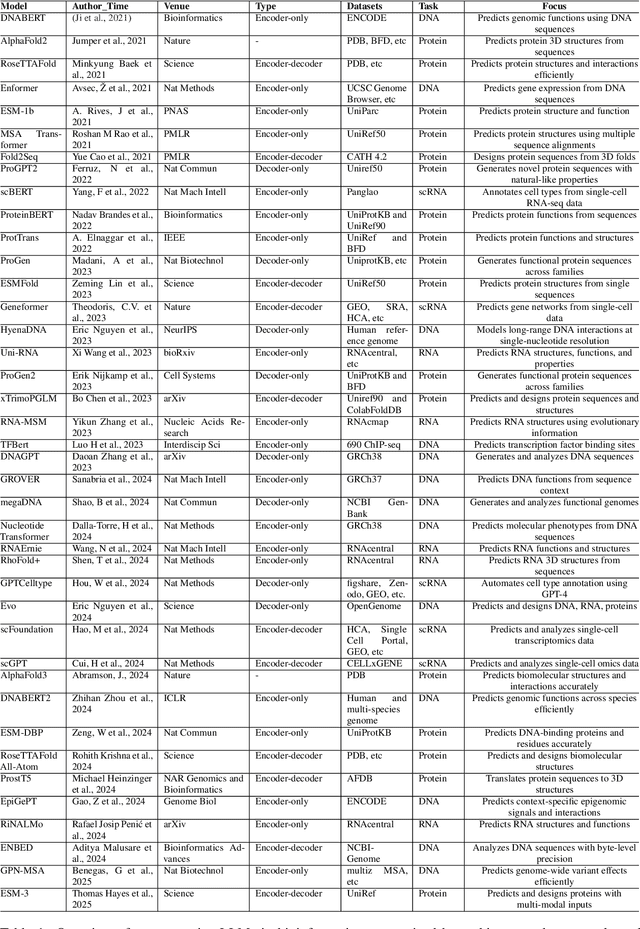
Large Language Models (LLMs) are revolutionizing bioinformatics, enabling advanced analysis of DNA, RNA, proteins, and single-cell data. This survey provides a systematic review of recent advancements, focusing on genomic sequence modeling, RNA structure prediction, protein function inference, and single-cell transcriptomics. Meanwhile, we also discuss several key challenges, including data scarcity, computational complexity, and cross-omics integration, and explore future directions such as multimodal learning, hybrid AI models, and clinical applications. By offering a comprehensive perspective, this paper underscores the transformative potential of LLMs in driving innovations in bioinformatics and precision medicine.
Biological Sequence with Language Model Prompting: A Survey
Mar 06, 2025Large Language models (LLMs) have emerged as powerful tools for addressing challenges across diverse domains. Notably, recent studies have demonstrated that large language models significantly enhance the efficiency of biomolecular analysis and synthesis, attracting widespread attention from academics and medicine. In this paper, we systematically investigate the application of prompt-based methods with LLMs to biological sequences, including DNA, RNA, proteins, and drug discovery tasks. Specifically, we focus on how prompt engineering enables LLMs to tackle domain-specific problems, such as promoter sequence prediction, protein structure modeling, and drug-target binding affinity prediction, often with limited labeled data. Furthermore, our discussion highlights the transformative potential of prompting in bioinformatics while addressing key challenges such as data scarcity, multimodal fusion, and computational resource limitations. Our aim is for this paper to function both as a foundational primer for newcomers and a catalyst for continued innovation within this dynamic field of study.