 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIVER: A Real-Time Interaction Benchmark for Video LLMs
Mar 04, 2026The rapid advancement of multimodal large language models has demonstrated impressive capabilities, yet nearly all operate in an offline paradigm, hindering real-time interactivity. Addressing this gap, we introduce the Real-tIme Video intERaction Bench (RIVER Bench), designed for evaluating online video comprehension. RIVER Bench introduces a novel framework comprising Retrospective Memory, Live-Perception, and Proactive Anticipation tasks, closely mimicking interactive dialogues rather than responding to entire videos at once. We conducted detailed annotations using videos from diverse sources and varying lengths, and precisely defined the real-time interactive format. Evaluations across various model categories reveal that while offline models perform well in single question-answering tasks, they struggle with real-time processing. Addressing the limitations of existing models in online video interaction, especially their deficiencies in long-term memory and future perception, we proposed a general improvement method that enables models to interact with users more flexibly in real time. We believe this work will significantly advance the development of real-time interactive video understanding models and inspire future research in this emerging field. Datasets and code are publicly available at https://github.com/OpenGVLab/RIVER.
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
LaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning
Jan 15, 2026Current multimodal latent reasoning often relies on external supervision (e.g., auxiliary images), ignoring intrinsic visual attention dynamics. In this work, we identify a critical Perception Gap in distillation: student models frequently mimic a teacher's textual output while attending to fundamentally divergent visual regions, effectively relying on language priors rather than grounded perception. To bridge this, we propose LaViT, a framework that aligns latent visual thoughts rather than static embeddings. LaViT compels the student to autoregressively reconstruct the teacher's visual semantics and attention trajectories prior to text generation, employing a curriculum sensory gating mechanism to prevent shortcut learning. Extensive experiments show that LaViT significantly enhances visual grounding, achieving up to +16.9% gains on complex reasoning tasks and enabling a compact 3B model to outperform larger open-source variants and proprietary models like GPT-4o.
Make Your Training Flexible: Towards Deployment-Efficient Video Models
Mar 18, 2025



Popular video training methods mainly operate on a fixed number of tokens sampled from a predetermined spatiotemporal grid, resulting in sub-optimal accuracy-computation trade-offs due to inherent video redundancy. They also lack adaptability to varying computational budgets for downstream tasks, hindering applications of the most competitive model in real-world scenes. We thus propose a new test setting, Token Optimization, for maximized input information across budgets, which optimizes the size-limited set of input tokens through token selection from more suitably sampled videos. To this end, we propose a novel augmentation tool termed Flux. By making the sampling grid flexible and leveraging token selection, it is easily adopted in most popular video training frameworks, boosting model robustness with nearly no additional cost. We integrate Flux in large-scale video pre-training, and the resulting FluxViT establishes new state-of-the-art results across extensive tasks at standard costs. Notably, with 1/4 tokens only, it can still match the performance of previous state-of-the-art models with Token Optimization, yielding nearly 90\% savings. All models and data are available at https://github.com/OpenGVLab/FluxViT.
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024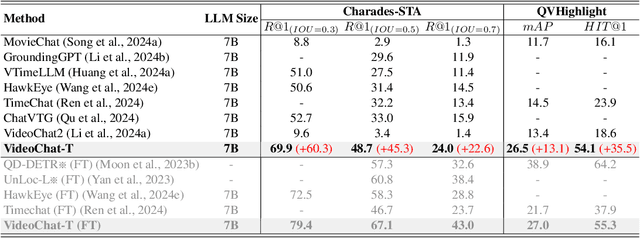
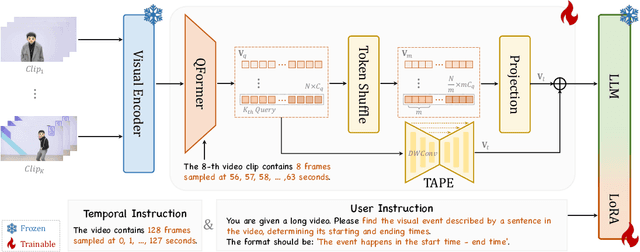
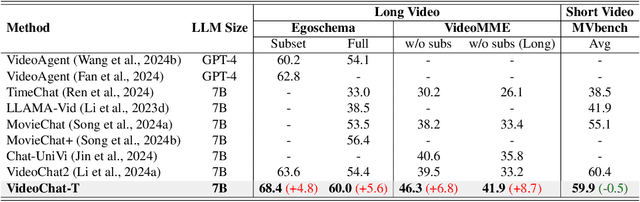
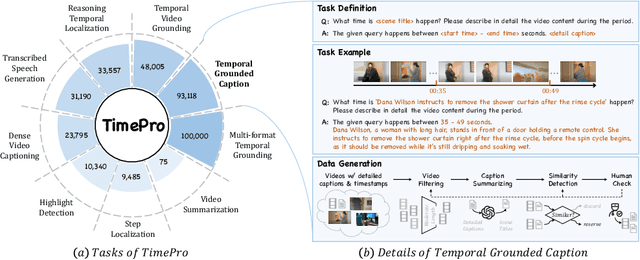
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.
Dynamic Resolution Guidance for Facial Expression Recognition
Apr 09, 2024
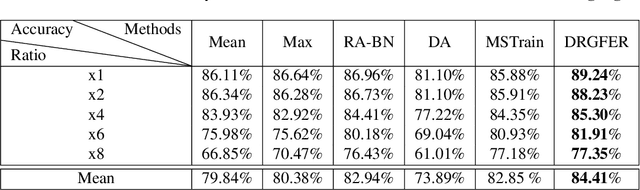
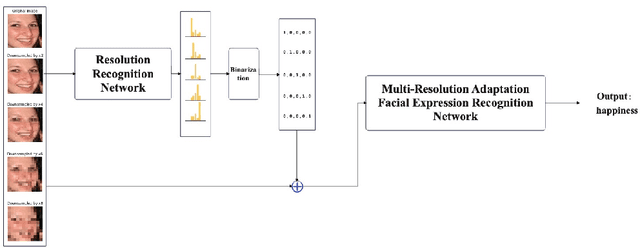
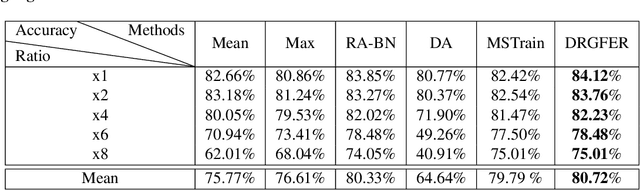
Facial expression recognition (FER) is vital for human-computer interaction and emotion analysis, yet recognizing expressions in low-resolution images remains challenging. This paper introduces a practical method called Dynamic Resolution Guidance for Facial Expression Recognition (DRGFER) to effectively recognize facial expressions in images with varying resolutions without compromising FER model accuracy. Our framework comprises two main components: the Resolution Recognition Network (RRN) and the Multi-Resolution Adaptation Facial Expression Recognition Network (MRAFER). The RRN determines image resolution, outputs a binary vector, and the MRAFER assigns images to suitable facial expression recognition networks based on resolution. We evaluated DRGFER on widely-used datasets RAFDB and FERPlus, demonstrating that our method retains optimal model performance at each resolution and outperforms alternative resolution approaches. The proposed framework exhibits robustness against resolution variations and facial expressions, offering a promising solution for real-world applications.
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.